爬虫与反爬之艺龙反爬(code值的生成,下,算法篇)
开局一张图,其它全靠编。
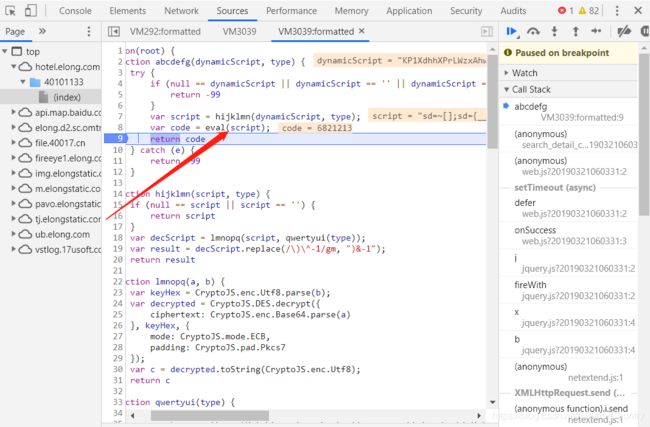
这里可以看到此abcdefg方法总共有四步构成,1:判断参数dynamicScrip是否为空,2使用hijklmn方法处理字符串dynamicScrip(hijklmn方法下面就有,可以使用拿来原则),3.eval 执行处理过的dynamicScrip字符串返回值为code,4.返回code值,到此结束。
我们只需要处理第三步就行了,之所以需要处理是因为我们需要用自己的环境来执行这些js代码,其中有些对象和属性只有浏览器中有,这样的话就只能自己先解析一下判读出执行这个字符串所需要用到的对象。
现在我们自己来一步一步解析,先把经过hijklmn处理后的dynamicScrip给复制出来,并格式化,会得到一段这个代码。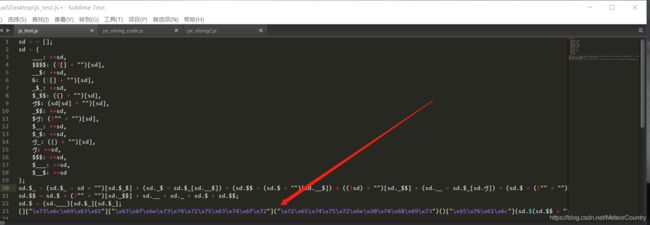
将这段代码粘贴到你所打开的酒店详情页的console中运行,就可以得到最终的code值(如下图)。

不过这样子还不行,还需要继续往下分析。在上图中的代码里的最后一行代码可以解为:
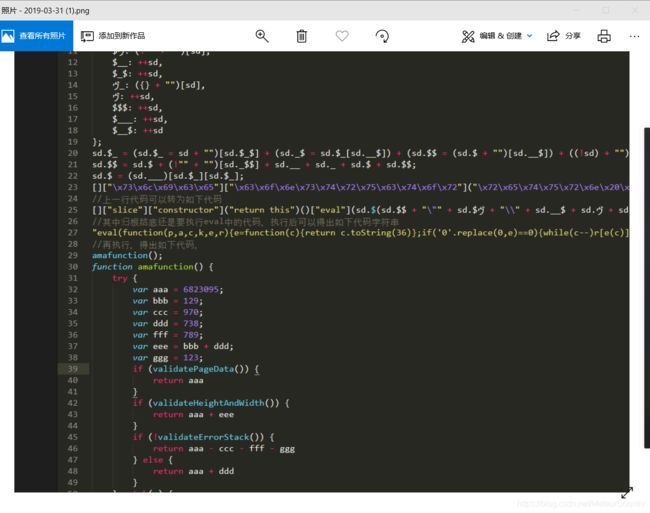
这是最后的js方法(js代码如下):
amafunction();
function amafunction() {
try {
var aaa = 6823095;
var bbb = 129;
var ccc = 970;
var ddd = 738;
var fff = 789;
var eee = bbb + ddd;
var ggg = 123;
if (validatePageData()) {
return aaa
}
if (validateHeightAndWidth()) {
return aaa + eee
}
if (!validateErrorStack()) {
return aaa - ccc - fff - ggg
} else {
return aaa + ddd
}
} catch(e) {
return - 99
}
}
function validatePageData() {
var temp = document.getElementsByClassName('t24 yahei');
if (temp.length == 0) {
return true
}
return false
}
function validateHeightAndWidth() {
var heigh = window.outerHeight;
var width = window.outerWidt;
if (0 == heigh || 0 == width) {
return true
} else {
return false
}
}
function validateErrorStack() {
var stackDetectionKeys = ["phantomjs", "callFunction", "pyppeteer", "moz"];
try {
null[0]()
} catch(e) {
for (var i = 0,
len = stackDetectionKeys.length; i < len; i++) {
var stackDetectionKeyValue = stackDetectionKeys[i];
if (e.stack.indexOf(stackDetectionKeyValue) > -1) {
return true
}
}
}
return false
}可以发现其中需要什么 document.getElementsByClassName,window.outerHeight 这种东西,如果不是在浏览器环境下运行就这些东西就需要自己补全,还有这只是其中一种情况,而且更改频率极高,搞得我是筋疲力竭,以经处于半放弃状态。
最后还是要说一句,爬虫最好还是要写的友好一些,速度能慢则慢,能在晚上爬就绝对不在白天爬,对别人网站影响较大的话,就降低影响。
爬虫之路,且行且珍惜吧。
写于 2019/3/31,一个周末无聊的晚上。