2019年CS224N课程笔记-Lecture 16:Coreference Resolution
资源链接:https://www.bilibili.com/video/BV1r4411f7td?p=16
正课内容
What is Coreference Resolution?/什么是共指消解?
识别所有涉及到相同现实世界实体的提及,指的是在一短文本内多个表达段/句子指向现实世界中的同一个实体,例如下属例子

这一段话中有许多实体(蓝色部分),其中许多实体指的是同一个人/现实中的事物,例如:


红色部分和橙色部分全部指向现实中的人物/事物,再例如
不同颜色代表不同的实体,不光是人,还有公园等~(图片来自视频,课件中的本内容无标记)
为什么Coreference Resolution有用?或者说有什么用?
基本都是和全文理解相关的各个方面都需要Coreference Resolution
1、信息提取, 回答问题, 总结, …,例如:“他生于1961年”,这个“他”到底是谁?(在阅读理解、问题回答、总结中还有其他方面都是非常关键的)
2、机器翻译
语言对性别,数量等有不同的特征,或者说很多动词语法等也需要确定主题等


3、对话系统/聊天系统

(例如某人买了一个xx的票,可能会把某人和xx混淆,如果没有Coreference Resolution的话)
Coreference Resolution in Two Steps/共指消解分两步进行

1、检测提到/提及的内容(简单)
2、把提到/提及的内容集中起来(困难)
(本质是一个集群任务)
如何快速找到提及内容?提及内容基本都是文本中的所有名词短语,通常人们会想到我们确定有三种类型的提及。
3. Mention Detection
- Mention : 指向某个实体的一段文本
- 三种Mention
- Pronouns/代词
- I, your, it, she, him, etc.
- 因为代词是 POS 检测结果的一种,所以只要使用 POS 检测器即可 - Named entities/命名实体
- People, places, etc.
- Use a NER system (like hw3) - Noun phrases/名词短语
- “a dog,” “the big fluffy cat stuck in the tree”
- Use a parser (especially a 依存解析器 constituency parser – next week!)
Mention Detection: Not so Simple/提及检测:没那么简单
将所有代词、命名实体和np标记为“提到”会生成“提及”
有一些非常棘手的案例,无论是否有提及?

- 天气晴朗(英文中如上图,好像没有提及,因为是it,虽然翻译后有)
- 每个学生(英文中同样并没有对应的实体,没有具体的参考)
- 没有学生(同上)
- 世界上最好的甜甜圈(这个是一个辩论,如果存在世界上最好的甜甜圈那么就是有对应实体的,否则就是...无对应实体,但是这个最好,可能很多人有不同意见,所以可能并不存在客观的世界上最好的甜甜圈~)
- 100英里(像一个名词短语,但是实际上是没有参考的数量)
如何解决?看下面~
How to deal with these bad mentions?如何处理这些不好的提及?
在上述例子中,我们发现许多对应现实实体存在的各种问题,解决思想如下:
可以训练一个分类器过滤掉spurious mentions,更为常见的:保持所有mentions 作为 “candidate mentions”,在你的共指系统运行完成后,丢弃所有的单个引用(即没有被标记为与其他任何东西共同引用的)
Can we avoid a pipelined system?/我们能避免流水线系统吗?
我们可以训练一个专门用于 mention 检测的分类器,而不是使用POS标记器、NER系统和解析器。甚至端到端共同完成mention检测和共指解析,而不是两步
4. On to Coreference! First, some linguistics/开始共指!首先,一些语言学
指代是指两个词指的是世界上同一个实体,当两个 mention 指向世界上的同一个实体时,被称为共指,例如Barack Obama 和 Obama
相关的语言概念是 anaphora 回指:当一个词(回指)指另一个词(先行词),下文的词返指或代替上文的词,例如:Barack Obama said he would sign the bill。anaphor 的解释在某种程度上取决于 antecedent 先行词的解释
Anaphora vs Coreference/回指与共指

共指类似指向同一个事物,而回指考虑了文中的文本关系
Not all anaphoric relations are coreferential/并非所有回指关系都是共指关系
并非所有的名词短语都有指称,例如

每句话中都有三个NPs;因为第一个是非指称的(之前也说了,实际上找不到真实的参考),其他两个也不是,但是her和前面的是回指关系。
再例如: 门票和音乐会有关,这也被称为照应关系,如果要解释门票含义必须依赖于文本的另一个名词短语(音乐会),但是显然他们两个是不同的实体,这被称为衔接回指/桥接回指/bridging anaphora,因为这点必须自己提供桥梁将先行者和回忆者联系起来(也就是刚刚说的音乐会和门票)
门票和音乐会有关,这也被称为照应关系,如果要解释门票含义必须依赖于文本的另一个名词短语(音乐会),但是显然他们两个是不同的实体,这被称为衔接回指/桥接回指/bridging anaphora,因为这点必须自己提供桥梁将先行者和回忆者联系起来(也就是刚刚说的音乐会和门票)
关系图如下:
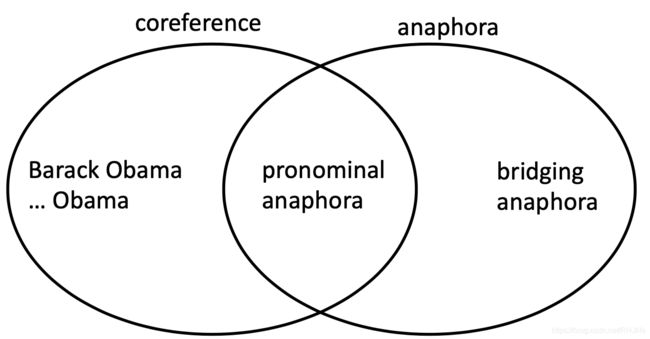
通常先行词在照应词之前(例如代词),但并不总是这样
Cataphora/后视
可以通过下面的文章体会一下(he、his都是向后找到参考),或者自己百度百度,不过好像不太好找
百度翻译结果:亨利·沃顿勋爵躺在波斯马鞍袋的一角,按他的习惯抽着无数支香烟,从那张沙发床的角落里,亨利·沃顿勋爵刚好能捕捉到一株紫檀花开的蜂蜜般甜美和蜂蜜色的光芒。。。
Four Kinds of Coreference Models/四种共指模式
基于规则的(代词回指解析)
提对
提及排名
聚类
5. Traditional pronominal anaphora resolution:Hobbs’ naive algorithm/传统代词回指解决方法:霍布斯'天真的算法
(1976年的共识解决方案,现在通常称为Hobbs算法,该算法仅用于寻找代词的参考,也可以延伸到其他案例,下面展示的也是代词的参考部分)


- 从名词短语开始,直接支配代词
- 上树到第一个NP或S,称之为X,路径为p。
- 横过X以下的所有分支到p的左边,从左到右,宽度优先。提出任何在它和X之间有NP或sb的NP作为先行词
- 如果X是句子中最高的S,则按照最近的顺序遍历前面句子的解析树。从左到右遍历每棵树,宽度优先。当遇到NP时,建议作为先行词。如果X不是最高的节点,则转到步骤5。
- 从节点X到树的第一个NP或S,称之为X,路径p。
- 如果X是NP,并且p到X的路径来自X的非头短语(一个说明符或附加语,如所有格、PP、同位或关联从句),则建议X作为先行词(原话说“没有通过X立即表示的N'”,但宾州树库语法缺少N'节点…)
- 以从左到右、宽度优先的方式将X以下的所有分支移到路径的左侧。提出任何遇到的NP作为前因
- 如果X是S节点,则遍历X的所有分支到路径的右侧,但不要低于遇到的任何NP或S。以NP为前因。
- 转到步骤4
Hobbs Algorithm Example/上述算法的例子
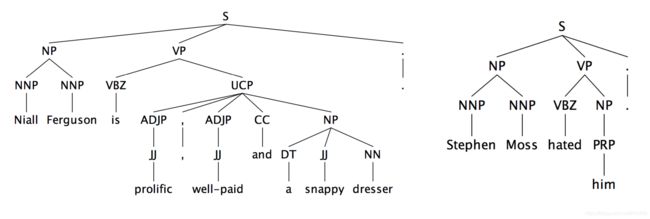
这是一个很简单、但效果很好的共指消解的基线/基准
Knowledge-based Pronominal Coreference/基于知识的代词共指代词

第一个例子中,两个句子具有相同的语法结构,但是出于外部世界知识,我们能够知道倒水之后,满的是杯子(第一句it指向的是the cup),空的是壶(第二句it指向的是the pitcher);第二个例子也是相同的(一个是委员会一个是女人)
可以将世界知识编码成共指问题
Hobbs’ algorithm: commentary/Hobbs算法述评

百度翻译:“... 这种天真的做法是相当好的。从计算上讲,一个基于语义的算法还需要很长时间才能实现,这些结果为任何其他方法的目标设定了一个非常高的标准。
然而,我们完全有理由追求基于语义的方法。天真的算法不起作用。任何人都可以举出失败的例子。在这些情况下,它不仅失败了,而且没有任何迹象表明它失败了,也无法帮助找到真正的前因。”
-霍布斯(1978),《语言学》,第345页
(直到2010年,设法产生代词回指分辨率的算法(我不知道翻译的对不对)才表现优于Hobbs算法)
6. Coreference Models: Mention Pair/共指模式:提及对
统计神经算法已经用于共指消解的常用的简单算法---Mention Pair

训练一个二元分类器,为每一对 mention 的分配共参的概率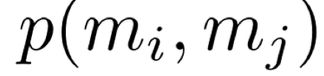 。例如,为了寻找 “she” 的共指,查看所有候选先行词(以前出现的 mention ),并确定哪些与之相关
。例如,为了寻找 “she” 的共指,查看所有候选先行词(以前出现的 mention ),并确定哪些与之相关
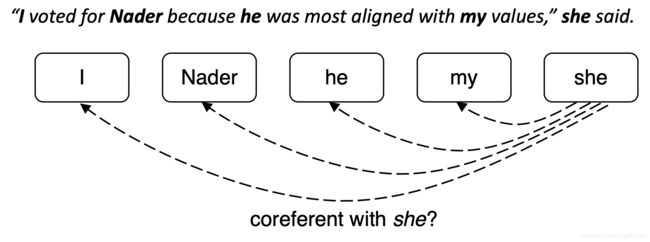
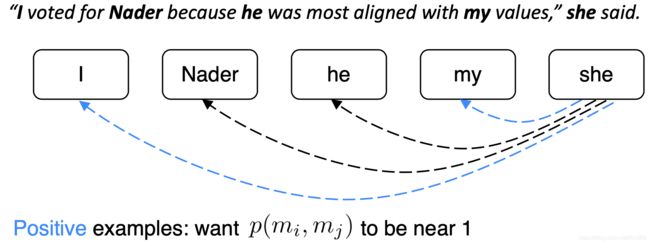
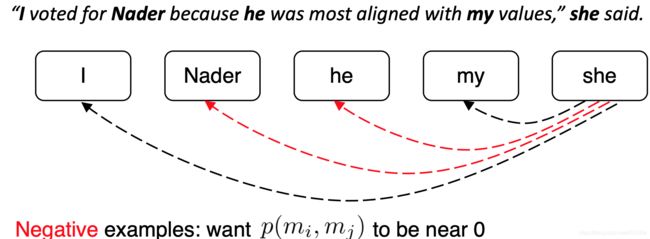
文章的 N 个mention,如果mi和mj是共指的,则yij=1,否则yij=-1,只是训练正常的交叉熵损失(看起来有点不同,因为它是二元分类)

图片内容分别为:
- 遍历 mentions
- 遍历候选先行词(前面出现的 mention)
- 共指 mention 对应该得到高概率,其他应该得到低概率
Mention Pair Test Time/提及配对测试时间
共指解析是一项聚类任务,但是我们只是对mentions对进行了评分……该怎么办?

选择一些阈值(例如0.5),并将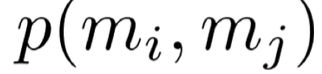 在阈值以上的 mentions 对之间添加共指链接
在阈值以上的 mentions 对之间添加共指链接
利用传递闭包得到聚类
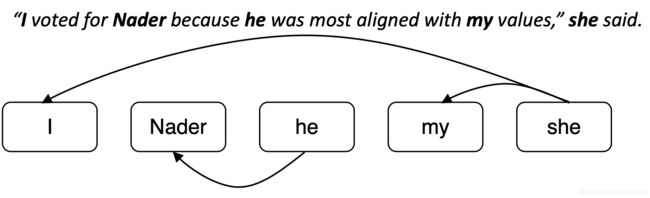
使用传递闭包来获得集群
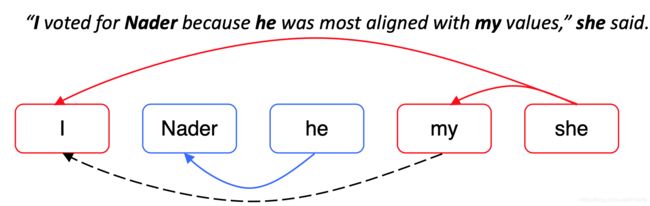
尽管模型没有预测到这种共指链接,但由于及物性,我和我的是共指者
添加这个额外的链接会将所有内容合并到一个大的共指集群中!

这是十分危险的,如果有一个共指 link 判断错误,就会导致两个 cluster 被错误地合并了
Mention Pair Models: Disadvantage/提及配对模式:劣势
假设我们的长文档里有如下的mentions
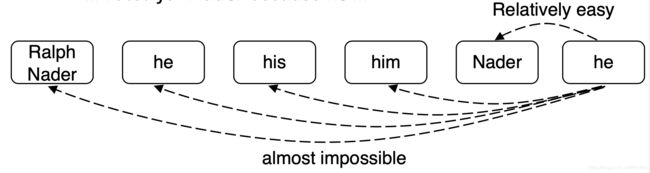
许多 mentions 只有一个清晰的先行词,但我们要求模型来预测它们
解决方案:相反,训练模型为每个mention只预测一个先行词,在语言上更合理
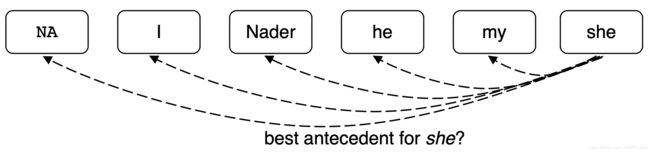
7. Coreference Models: Mention Ranking/共指模型:提及排名
根据模型把其得分最高的先行词分配给每个mention,虚拟的 NA mention 允许模型拒绝将当前 mention 与任何内容联系起来(“singleton” or “first” mention),first mention: I 只能选择 NA 作为自己的先行词

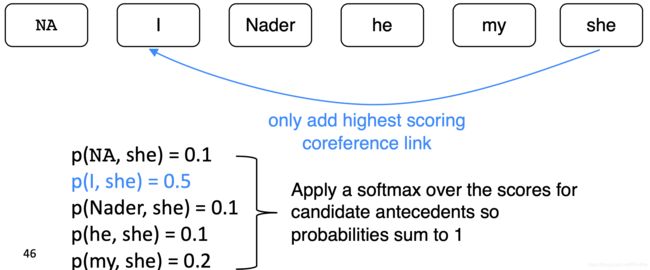
(一看到概率,就很容易联想到softmax)
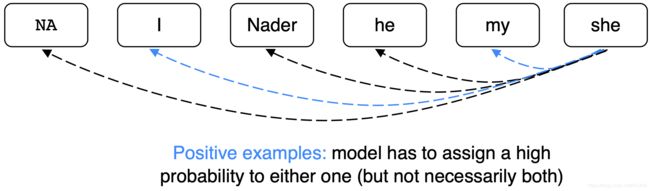
Coreference Models: Training/共指模型:训练
我们希望当前mention mj与它所关联的任何一个候选先行词相关联,在数学上,我们可能想要最大化这个概率,公式如下:
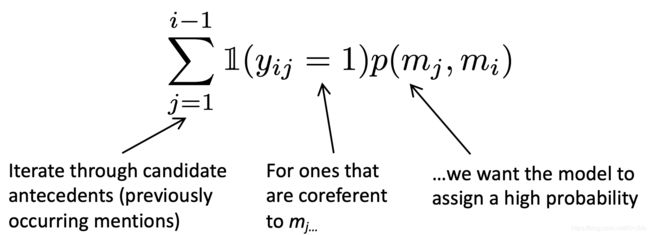
上图内容翻译:
- 遍历候选先行词集合
- 对于 yij=1的情况,即mi与mj是共指关系的情况
- 我们希望模型能够给予其高可能性
这个模型对一个正确的前因产生了0.9的概率,而其他所有的概率都很低,而且总和仍然很大
把它转化为一个loss函数,如下:
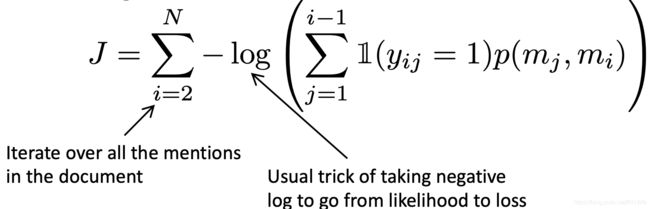
Mention Ranking Models: Test Time/提及排名模型:测试时间(或者是测试阶段更好)
和mention-pair模型几乎一样,除了每个mention只分配一个先行词

How do we compute the probabilities?/我们如何计算概率?
如何决定mi和mj是共同的呢?将会从下面三个方面进行介绍
A. Non-neural statistical classifier/非神经统计分类器
B. Simple neural network/简单神经网络
C. More advanced model using LSTMs, attention/使用LSTM的更高级模型,注意力机制
A. Non-Neural Coref Model: Features/非神经Coref模型:特征
经典做法是我们有一大堆功能,基于特征的统计分类器,然后给出分数

使用如下特征进行分类 (可以把这些特征都投入进去训练)
- 人、数字、性别
- 语义相容性(类似集团和公司就很相似)
- 句法约束(例如之前说的Hobbs算法,不同的句法配置有多大可能意味着共同参与)
- 更近的提到的实体是个可能的参考对象(两个人先后做个一个事情,出现的he更可能是后一个人,如上图对应例子)
- 语法角色:偏好主语位置的实体(上述对应例子就很能表达出这个意思)
- 排比(看对应例子...)
B. Neural Coref Model
标准的前馈神经网络,输入层:词嵌入和一些类别特征(彩色部分可能提到了什么是语法关系?这是一个主题吗?它是一个对象吗?是否是共同?额外功能记录了相距有多远及尺寸)

Neural Coref Model: Inputs/神经Coref模型:输入
嵌入:每个 mention 的前两个单词,第一个单词,最后一个单词,head word,… 。head word是 mention 中“最重要”的单,—可以使用解析器找到它
例如:The fluffycat stuck in the tree
仍然需要一些其他特征,如下(刚刚也说过了)
- 距离
- 文档体裁
- 说话者的信息嵌入
(这部分跳过了,直接说的C)
C. End-to-end Model/端到端模型
这里说明了一下什么是当前的共参考分辨率技术(总感觉翻译怪怪的,但是我也不懂这个..555...),这是一个华盛顿大学完成的系统(2017年,Kenton Lee和其他作者完成的),目标是生成一个端到端的共享系统,提出共同的集群,是当前最先进的模型算法(Kenton Lee et al. from UW, EMNLP 2017),是Mention排名模型,改进了简单的前馈神经网络,改进如下:
- 使用LSTM
- 使用注意力
- 端到端的完成 mention 检测和共指(没有 mention 检测步骤!而是考虑每段文本(一定长度)作为候选 mention们,例如:a span 是一个连续的序列)
End-to-end Mode的步骤
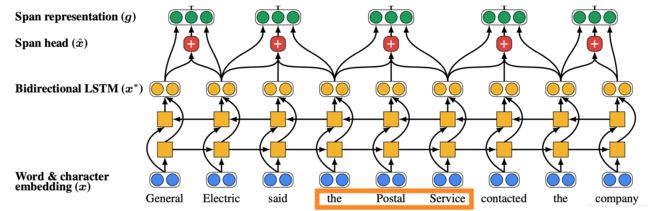
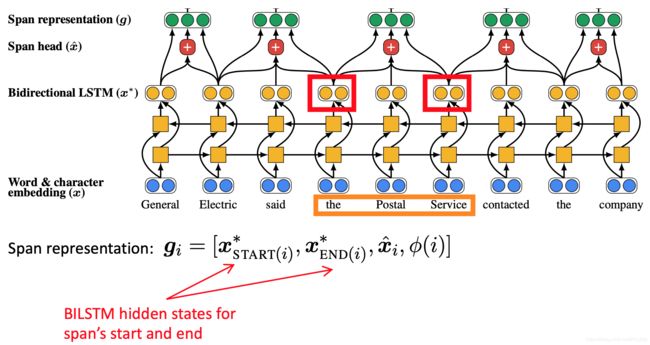
首先将文档里的单词使用词嵌入矩阵和 charCNN embed 为词嵌入

接着在文档上运行双向 LSTM

接着将每段文本i从 到
到 表示为一个向量
表示为一个向量
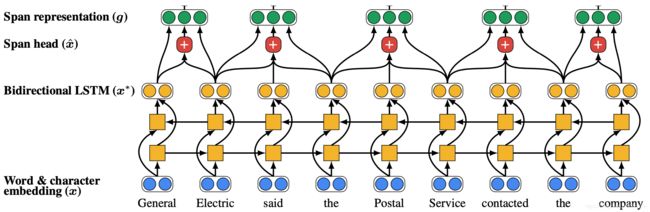
span 是句子中任何单词的连续子句
General, General Electric, General Electric said, … Electric, Electric said, …都会得到它自己的向量表示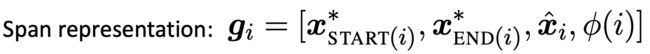
例如 “the postal service”
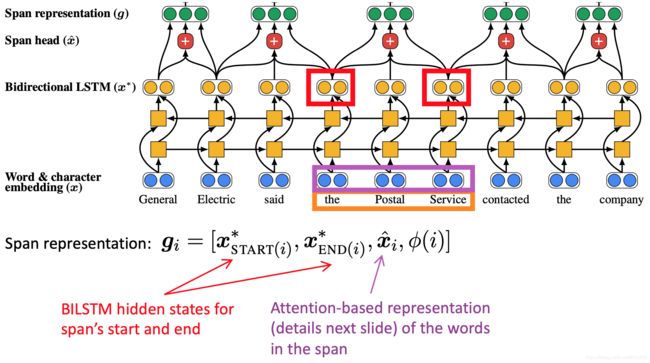
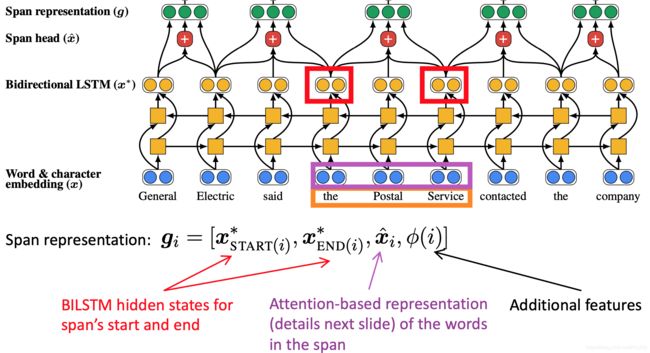
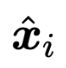 是 span 的注意力加权平均的词向量
是 span 的注意力加权平均的词向量
 为什么要在 span 中引入所有的这些不同的项?
为什么要在 span 中引入所有的这些不同的项?
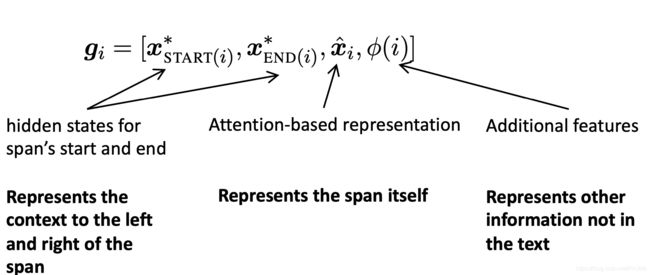
最后,为每个span对打分来决定他们是不是共指mentions

打分函数以span representations作为输入

为每对 span 打分是棘手的,因为:一个文档中有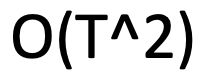 spans,T是词的个数,时间复杂度为
spans,T是词的个数,时间复杂度为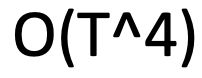 ,所以必须做大量的修剪工作(只考虑一些可能是 mention 的span),关注学习哪些单词是重要的在提到(有点像head word)
,所以必须做大量的修剪工作(只考虑一些可能是 mention 的span),关注学习哪些单词是重要的在提到(有点像head word)
![]()
8. Last Coreference Approach: Clustering-Bas/最后一种共指方法:聚类Bas
共指是个聚类任务,让我们使用一个聚类算法吧。特别是我们将使用 agglomerative 凝聚聚类(自下而上的)。开始时,每个mention在它自己的单独集群中,每一步合并两个集群(使用模型来打分那些聚类合并是好的)
所以这里的想法是我们会有段文字:谷歌最近等等(如下)
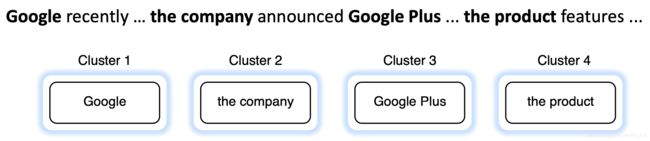
到这里我们有一些/四个提及,这四个提及各有自己的集群,我们可能决定两个提及是共同的并把他们合并成一个集群,如下

Mention-pair decision is difficult/提及对的决定是困难的
因为通常比较难判断是否是共同的

Cluster-pair decision is easier/聚类对决策更容易
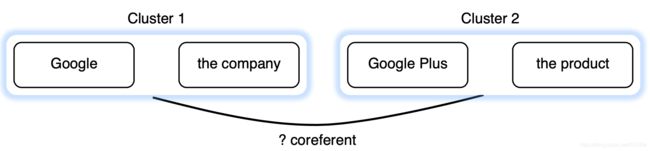
Clustering Model Architecture/聚类模型体系结构
From Clark & Manning, 2016
之前我们nlp经常用分布式词向量进行表示,这里将超越它并提出了集群表示(如图那样多个词合在一起)

(后续内容没说直接到9了,以下为课件内容)
首先为每个 mention 对生成一个向量。例如,前馈神经网络模型中的隐藏层的输出
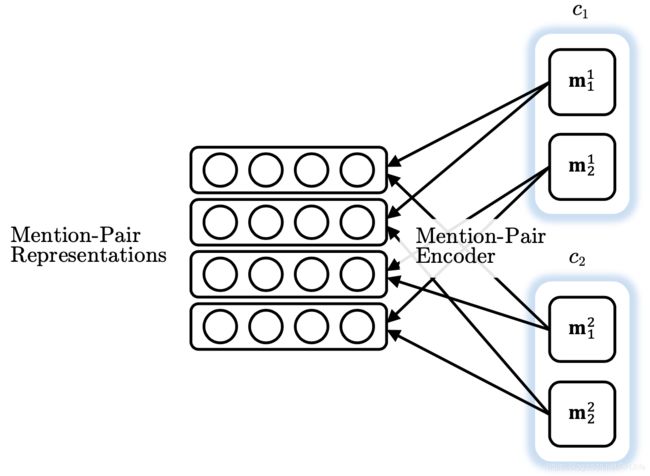
接着将池化操作应用于 mentino-pair 表示的矩阵上,得到一个 cluster-pair 聚类对的表示
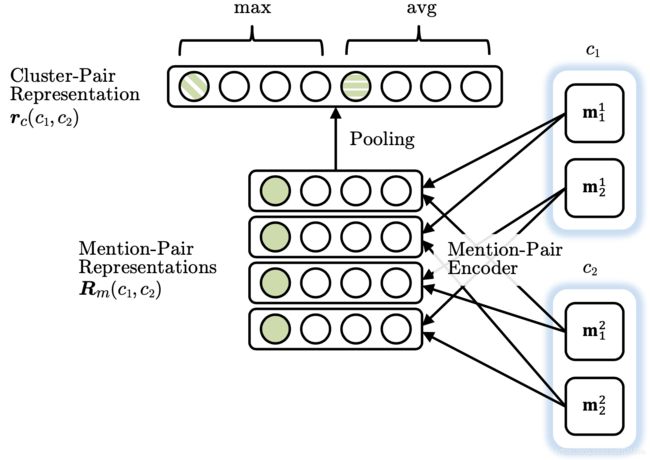
通过用权重向量与表示向量的点积,对 candidate cluster merge 进行评分。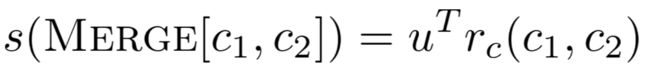
当前候选簇的合并,取决于之前的合并,所以不能用常规的监督学习,使用类似强化学习训练模型(为每个合并分配奖励:共指评价指标的变化)
9. Coreference Evaluation/共指评估
许多不同的评价指标:MUC, CEAF, LEA, B-CUBED, BLANC。经常使用一些不同评价指标的均值
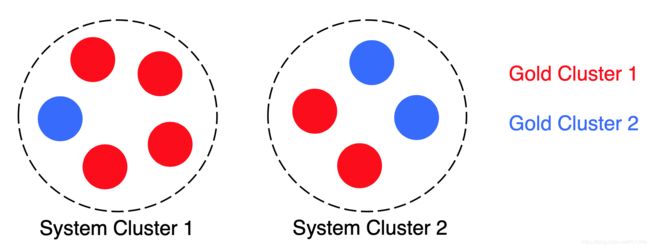
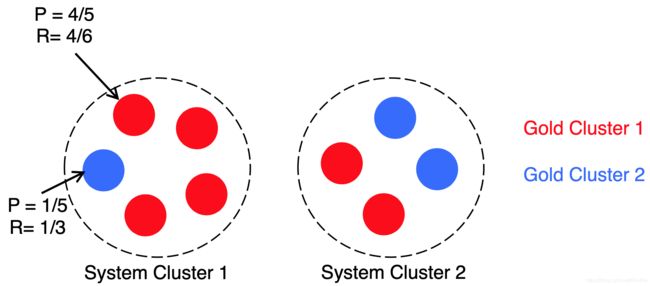
例如 B-cubed,对于每个 mention ,计算其准确率和召回率,然后平均每个个体的准确率和召回率,过程如下:


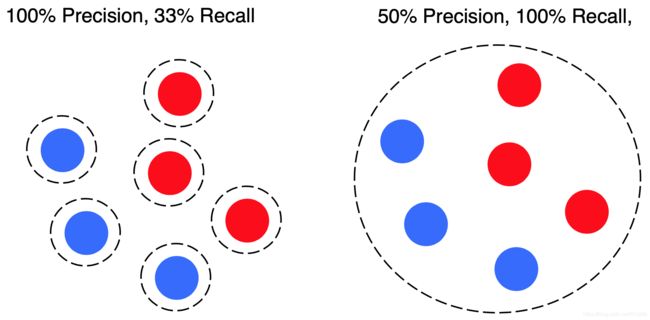
System Performance/系统性能
OntoNotes数据集:~ 3000人类标注的文档(英语和中文)报告一个F1分数在3个参考指标上的平均值
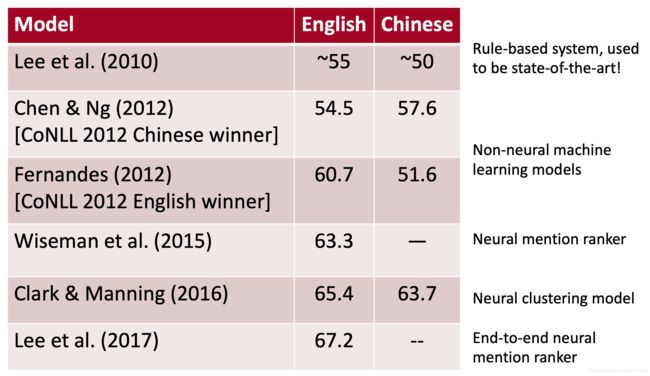
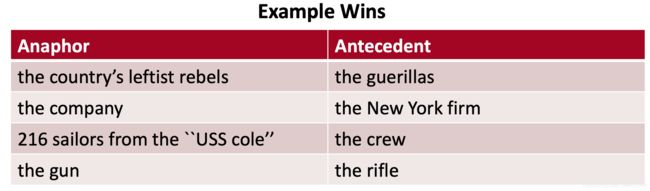
Where do neural scoring models help?/神经评分模型有何帮助?
尤其是对于没有字符串匹配的NPs和命名实体。神经性与非神经性评分:

18.9 F1对10.7 F1,而68.7 F1对66.1 F1,这类共指很难,而且分数仍然很低!
Conclusion/结论
共指是一个有用的、具有挑战性和有趣的语言任务,许多不同种类的算法系统
系统迅速好转,很大程度上是由于更好的神经模型,但总的来说,还没有惊人的结果
你自己尝试一个共指系统
http://corenlp.run/ (ask for coref in Annotations)
https://huggingface.co/coref/
(即使现在一些比较好的共指系统,输入文本后依旧可以发现存在许多问题)