文章转自公众号【机器学习炼丹术】,关注回复“炼丹”即可获得海量免费学习资料哦!
1 作者前言
在2020年还在整理XGB的算法,其实已经有点过时了。不过,主要是为了扩大知识面和应付面试嘛。现在的大数据竞赛,XGB基本上已经全面被LGB模型取代了,这里主要是学习一下Boost算法。之前已经在其他博文中介绍了Adaboost算法和Gradient-boost算法,这篇文章讲解一下XGBoost。
2 树模型概述
XGB就是Extreme Gradient Boosting极限梯度提升模型。XGB简单的说是一组分类和回归树(CART)的组合。跟GBDT和Adaboost都有异曲同工之处。
【CART=classification adn regression trees】
这里对于一个决策树,如何分裂,如何选择最优的分割点,其实就是一个搜索的过程。搜索怎么分裂,才能让目标函数最小。目标函数如下:
$Obj = Loss + \Omega$
$Obj$就是我们要最小化的优化函数,$Loss$就是这个CART模型的预测结果和真实值得损失。$\Omega$就是这个CART模型的复杂度,类似神经网络中的正则项。
【上面的公式就是一个抽象的概念。我们要知道的是:CART树模型即要求预测尽可能准确,又要求树模型不能过于复杂。】
对于回归问题,我们可以用均方差来作为Loss:
$Loss=\sum_i{(y_i-\hat{y_i})^2}$
对于分类问题,用交叉熵是非常常见的,这里用二值交叉熵作为例子:
$Loss = \sum_i{(y_ilog(\hat{y_i})+(1-y_i)log(\hat{y_i}))}$
总之,这个Loss就是衡量模型预测准确度的损失。
下面看一下如何计算这个模型复杂度$\Omega$吧。
$\Omega = \gamma T+\frac{1}{2} \lambda \sum^T_j{w_j}^2$
$T$表示叶子节点的数量,$w_j$表示每个叶子节点上的权重(与叶子节点的样本数量成正比)。
【这里有点麻烦的在于,$w_j$是与每个叶子节点的样本数量成正比,但是并非是样本数量。这个$w_j$的求取,要依靠与对整个目标函数求导数,然后找到每个叶子节点的权重值$w_j$。】
3 XGB vs GBDT
其实说了这么多,感觉XGB和GDBT好像区别不大啊?那是因为说了这么多还没开始说XGB呢!之前都是讲树模型的通用概念的。下面讲解XGB~整理一下网上有的说法,再加上自己的理解。有错误请指出评论,谢谢!
3.1 区别1:自带正则项
GDBT中,只是让新的弱分类器来拟合负梯度,那拟合多少棵树才算好呢?不知道。XGB的优化函数中,有一个$\Omega$复杂度。这个复杂度不是某一课CART的复杂度,而是XGB中所有CART的总复杂度。可想而知,每多一颗CART,这个复杂度就会增加他的惩罚力度,当损失下降小于复杂度上升的时候,XGB就停止了。
3.2 区别2:有二阶导数信息
GBDT中新的CART拟合的是负梯度,也就是一阶导数。而在XGB会考虑二阶导数的信息。
这里简单推导一下XGB如何用上二阶导数的信息的:
- 之前我们得到了XGB的优化函数:
$Obj = Loss + \Omega$
- 然后我们把Loss和Omega写的更具体一点:
$Obj = \sum_i^n{Loss(y_i,\hat{y}_i^t)}+\sum_j^t{\Omega(cart_j)}$
- $\hat{y_i^t}$表示总共有t个CART弱分类器,然后t个弱分类器给出样本i的估计值就。
- $y_i$第i个样本的真实值;
- $\Omega(cart_j)$第j个CART模型的复杂度。
- 我们现在要求取第t个CART模型的优化函数,所以目前我们只是知道前面t-1的模型。所以我们得到:
$\hat{y}_i^t = \hat{y}_i^{t-1}+f_t(x_i)$
t个CART模型的预测,等于前面t-1个CART模型的预测加上第t个模型的预测。
- 所以可以得到:
$\sum_i^n{Loss(y_i,\hat{y}_i^t)}=\sum_i^n{Loss(y_i,\hat{y}_i^{t-1}+f_t(x_i))}$
这里考虑一下特勒展开:
$f(x+\Delta x)\approx f(x)+f'(x)\Delta x + \frac{1}{2} f''(x)\Delta x^2$
- 如何把泰勒公式带入呢?
${Loss(y_i,\hat{y}_i^t)}$中的$y_i$其实就是常数,不是变量
所以其实这个是可以看成$Loss(\hat{y}_i^t)$,也就是:
$Loss(\hat{y}_i^{t-1}+f_t(x_i))$
- 带入泰勒公式,把$f_t(x_i)$看成$\Delta x$:
$Loss(\hat{y}_i^{t-1}+f_t(x_i))=Loss(\hat{y}_i^{t-1})+Loss'(\hat{y}_i^{t-1})f_t(x_i)+\frac{1}{2}Loss''(\hat{y}_i^{t-1})(f_t(x_i))^2$
- 在很多的文章中,会用$g_i=Loss'(\hat{y}_i^{t-1})$,以及$h_i=Loss''(\hat{y}_i^{t-1})$来表示函数的一阶导数和二阶导数。
- 把泰勒展开的东西带回到最开始的优化函数中,删除掉常数项$Loss(\hat{y}_i^{t-1})$(这个与第t个CART模型无关呀)以及前面t-1个模型的复杂度,可以得到第t个CART的优化函数:
$Obj^t \approx \sum_i^n{[g_i f_t(x_i)+\frac{1}{2}h_i(f_t(x_i))^2}]+{\Omega(cart_t)}$
【所以XGB用到了二阶导数的信息,而GBDT只用了一阶的梯度】
3.3 区别3:列抽样
XGB借鉴了随机森林的做法,不仅仅支持样本抽样,还支持特征抽样(列抽样),不仅可以降低过拟合,还可以减少计算。(但是这一点我个人存疑,感觉这个只是代码给出的功能,并不算是XGB本身算法相对GBDT的优势。因为XGB和GBDT明明都可以用列抽样的方法。总之,最关键的区别是二阶导数那个和引入正则项)
4 XGB为什么用二阶导
这个是一个关于XGB的面试进阶题。第一次看到这个问题的时候,一脸懵逼。
【先说自己总结的答案】
- 使用了二阶导数的信息,加快了收敛速度。
- 减少了计算量。
4.1 为什么减少了计算量
这个比较理解,就先从这个开始解释。
在GBDT中,最花费时间的就是计算分裂点,选择哪个特征,在哪个分割点进行分裂可以得到最小的loss。假设有5个特征,每个特征有100个潜在分割点,那么分类一次需要计算500次。
$loss(y,\hat{y}^t)$像之前一样,写成之前所有已经训练完成的弱分类器和正在训练的分类器$loss(y,\hat{y}^{t-1}+f_t(x))$
如果计算这个损失的话,我们需要计算500次的
$loss(y,\hat{y}^{t-1}+f_t(x))$
但是假设使用泰勒展开得到:
$loss(\hat{y}^{t-1})+g*f_t(x)+\frac{1}{2}h(f_t(x))^2$
其中的$loss(\hat{y}^{t-1})$,$g$,$h$都是仅仅与之前已经训练完成的决策树相关,所以就是常数,所以是可以在500次的计算中共享,计算一次足以。
4.2 为什么加快收敛速度
这里要回到泰勒展开那里:
$f(x+\Delta x) = f(x) + g(x) * \Delta x + \frac{1}{2} h(x) (\Delta x)^2$
这个式子其实就可以看成是$F(\Delta x)$,因为$x$可以看成一个常数。我们希望$F(\Delta x)$最小(也就是损失最小),所以我们对$\Delta x$求导数:
$F'(\Delta x)=g(x)+h(x)\Delta x=0$
导数为0,则是极小值(默认是凸函数)
$\Delta x=-\frac{g(x)}{h(x)}$,也就是说,更新的步长其实就是一阶导数除以二阶导数。
了解最优化算法的朋友应该可以意识到,这个其实是跟牛顿法等价的。XGB每一次训练一个新的基模型,其实就是再使用牛顿法来对损失函数进行最小值的优化与更新。
【小总结】
因此我个人认为,使用了二阶信息的XGB比使用了一阶信息的GBDT收敛速度快的原因,可以用牛顿法比梯度下降法收敛快来解释。
【为什么牛顿法收敛速度快】
其实这一块我有些解释不清楚了,因为我最优化算法学的也不精(好像突然发现找不到工作的原因了2333)。能给出的是一个比较通俗的解释: 从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。
5 牛顿法
这里简单介绍一下牛顿法是什么。毕竟有的朋友可能没学过,或者学过像我一样忘记了。
【牛顿法的目的】
求解一个函数的根,也就是这个函数与x坐标轴的交点。
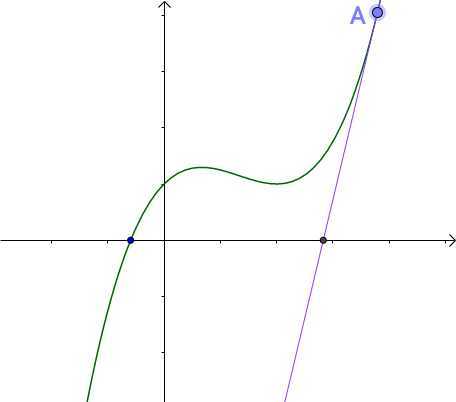
然后这个焦点做一个平行于y轴的线,交于B点,然后B点做切线,然后交于x轴,然后......

然后迭代到C点
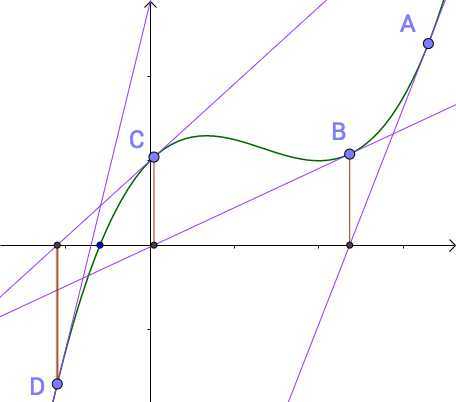
慢慢的,就逼近三次函数与x轴的交点,也就是三次函数等于0的根了。
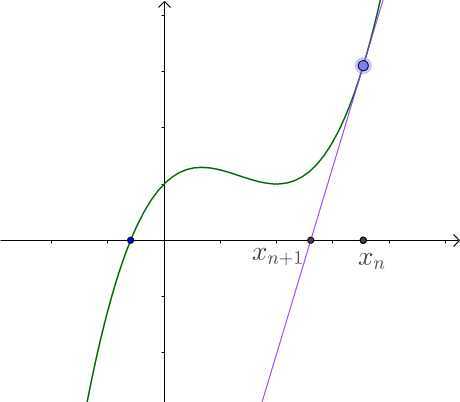
【数学算式】
$x_n$点的切线方程:
$f(x_n)+f'(x_n)(x-x_n)=0$
所以很简单得到:
$x_{n+1}=x_n-\frac{f(x_n)}{f'(x_n)}$
【为什么这里只用到了一阶信息?】
因为这里的目的是求取一个函数的根,也就是函数等于0的根。我们在最优化问题中,求解的是一个函数的极小值,这就要求求取这个函数的导数等于0的根,所以在最优化问题中,是一个二阶导数优化方法。
写了4000字,太累了。欢迎大家加好友交流。