Trie(前缀树)
知识简介
我们常常用Trie(也叫前缀树)来保存字符串集合。
Trie 的强大之处就在于它的时间复杂度。它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关。Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题;Trie 的缺点是空间消耗很高。
至于Trie树的实现,可以用数组,也可以用指针动态分配,我做题时为了方便就用了数组,静态分配空间。
Trie树,又称单词查找树或键树,字典树,前缀树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
性质
Trie树的基本性质可以归纳为:
(1)根节点不包含字符,除根节点意外每个节点只包含一个字符。
(2)从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
(3)每个节点的所有子节点包含的字符串不相同。
除基本性质外,Trie树还有一些特性:
(1)如果字符的种数为n,则每个结点的出度为n,这也是空间换时间的体现,浪费了很多的空间。
(2)插入查找的复杂度为O(n),n为字符串长度。
基本思想(以字母树为例):
1、插入过程
对于一个单词,从根开始,沿着单词的各个字母所对应的树中的节点分支向下走,直到单词遍历完,将最后的节点标记为红色,表示该单词已插入Trie树。
2、查询过程
同样的,从根开始按照单词的字母顺序向下遍历trie树,一旦发现某个节点标记不存在或者单词遍历完成而最后的节点未标记为红色,则表示该单词不存在,若最后的节点标记为红色,表示该单词存在。
数据结构
利用串构建一个字典树,这个字典树保存了串的公共前缀信息,因此可以降低查询操作的复杂度。
下面以英文单词构建的字典树为例,这棵Trie树中每个结点包括26个孩子结点,因为总共有26个英文字母(假设单词都是小写字母组成)。
则可声明包含Trie树的结点信息的结构体:
指针版:
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;数组版:
struct node
{
char ch; //本节点的值
bool endflag; //是否是某个单词的最后一个字符
int link[26]; //26个分叉
} tree[600100];
其中next是一个指针数组,存放着指向各个孩子结点的指针。
如给出字符串”abc”,”ab”,”bd”,”dda”,根据该字符串序列构建一棵Trie树。则构建的树如下:
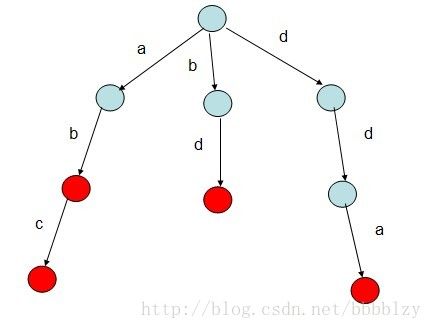
Trie树的根结点不包含任何信息,第一个字符串为”abc”,第一个字母为’a’,因此根结点中数组next下标为’a’-97的值不为NULL,其他同理,构建的Trie树如图所示,红色结点表示在该处可以构成一个单词。很显然,如果要查找单词”abc”是否存在,查找长度则为O(len),len为要查找的字符串的长度。而若采用一般的逐个匹配查找,则查找长度为O(len*n),n为字符串的个数。显然基于Trie树的查找效率要高很多。
如上图中:Trie树中存在的就是abc、ab、bd、dda四个单词。在实际的问题中可以将标记颜色的标志位改为数量count等其他符合题目要求的变量。
已知n个由小写字母构成的平均长度为10的单词,判断其中是否存在某个串为另一个串的前缀子串。下面对比3种方法:
(1)最容易想到的:即从字符串集中从头往后搜,看每个字符串是否为字符串集中某个字符串的前缀,复杂度为O(n^2)。
(2) 使用hash:我们用hash存下所有字符串的所有的前缀子串。建立存有子串hash的复杂度为O(n*len)。查询的复杂度为O(n)* O(1)= O(n)。
(3)使用Trie:因为当查询如字符串abc是否为某个字符串的前缀时,显然以b、c、d….等不是以a开头的字符串就不用查找了,这样迅速缩小查找的范围和提高查找的针对性。所以建立Trie的复杂度为O(n*len),而建立+查询在trie中是可以同时执行的,建立的过程也就可以成为查询的过程,hash就不能实现这个功能。所以总的复杂度为O(n*len),实际查询的复杂度只是O(len)。
Trie树的操作
在Trie树中主要有3个操作,插入、查找和删除。一般情况下Trie树中很少存在删除单独某个结点的情况,因此只考虑删除整棵树。
1、插入
假设存在字符串str,Trie树的根结点为root。i=0,p=root。
1)取str[i],判断p->next[str[i]-97]是否为空,若为空,则建立结点temp,并将p->next[str[i]-97]指向temp,然后p指向temp;
若不为空,则p=p->next[str[i]-97];
2)i++,继续取str[i],循环1)中的操作,直到遇到结束符’\0’,此时将当前结点p中的 exist置为true。
2、查找
假设要查找的字符串为str,Trie树的根结点为root,i=0,p=root
1)取str[i],判断判断p->next[str[i]-97]是否为空,若为空,则返回false;若不为空,则p=p->next[str[i]-97],继续取字符。
2))重复1)中的操作直到遇到结束符’\0’,若当前结点p不为空并且 exist 为true,则返回true,否则返回false。
3、删除
删除可以以递归的形式进行删除。
指针版:
typedef struct Trie_node
{
int count; // 统计单词前缀出现的次数
struct Trie_node* next[26]; // 指向各个子树的指针
bool exist; // 标记该结点处是否构成单词
}TrieNode , *Trie;
TrieNode* createTrieNode()
{
TrieNode* node = (TrieNode *)malloc(sizeof(TrieNode));
node->count = 0;
node->exist = false;
memset(node->next , 0 , sizeof(node->next)); // 初始化为空指针
return node;
}
void Trie_insert(Trie root, char* word)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
if(node->next[id] == NULL)
{
node->next[id] = createTrieNode();
}
node = node->next[id]; // 每插入一步,相当于有一个新串经过,指针向下移动
++p;
node->count += 1; // 这行代码用于统计每个单词前缀出现的次数(也包括统计每个单词出现的次数)
}
node->exist = true; // 单词结束的地方标记此处可以构成一个单词
}
int Trie_search(Trie root, char* word)
{
Trie node = root;
char *p = word;
int id;
while( *p )
{
id = *p - 'a';
node = node->next[id];
++p;
if(node == NULL)
return 0;
}
return node->count;
}
Trie root = createTrieNode(); // 初始化字典树的根节点
数组版:
根节点的编号是0.并且不代表任何字符。
利用类似于静态临界表的构造方法,trie树开在一个一维数组里,并且依照用到再申请空间的原则,在建树的时候,如果需要用到哪个字符,我们再申请新的空间。
void add(int k,int node) //k是s的第k个字符,node为当前节点。
{
int chindex=s[k]-‘A’; //字符的编号
if (tree[node].link[chindex]==0) //新开节点
{
tree[node].link[chindex]=++len;
tree[len].ch=s[k];
}
int nexnode=tree[node].link[chindex]; //下一个节点的下标
if (k==(int)s.size()-1)
{
tree[nexnode].endflag=true;
return;
}
add(k+1,nexnode);
}
bool find(int k, int last,int node)
//k是要查找字符串s的第k个元素
{
int chindex=s[k]-'a';
if (tree[node].link[chindex]==0) return false;
int nextnode=tree[node].link[chindex];
if (k==(s.size()-1)) //如果k是最后一个字符
if (tree[nextnode].endflag) return true;
else return false;
return find(k+1,last,nextnode);
}
例题(oj611)
题目描述
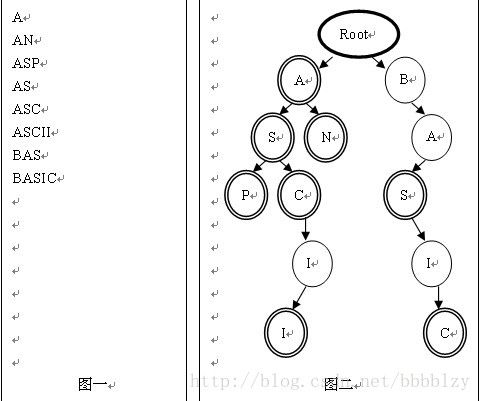
在进行文法分析的时候,通常需要检测一个单词是否在我们的单词列表里。为了提高查找和定位的速度,通常都要画出与单词列表所对应的单词查找树,其特点如下:
根节点不包含字母,除根节点外每一个节点都仅包含一个大写英文字母;
从根节点到某一节点,路径上经过的字母依次连起来所构成的字母序列,称为该节点对应的单词。单词列表中的每个词,都是该单词查找树某个节点所对应的单词;
在满足上述条件下,该单词查找树的节点数最少。
例:图一的单词列表对应图二的单词查找树
输入格式
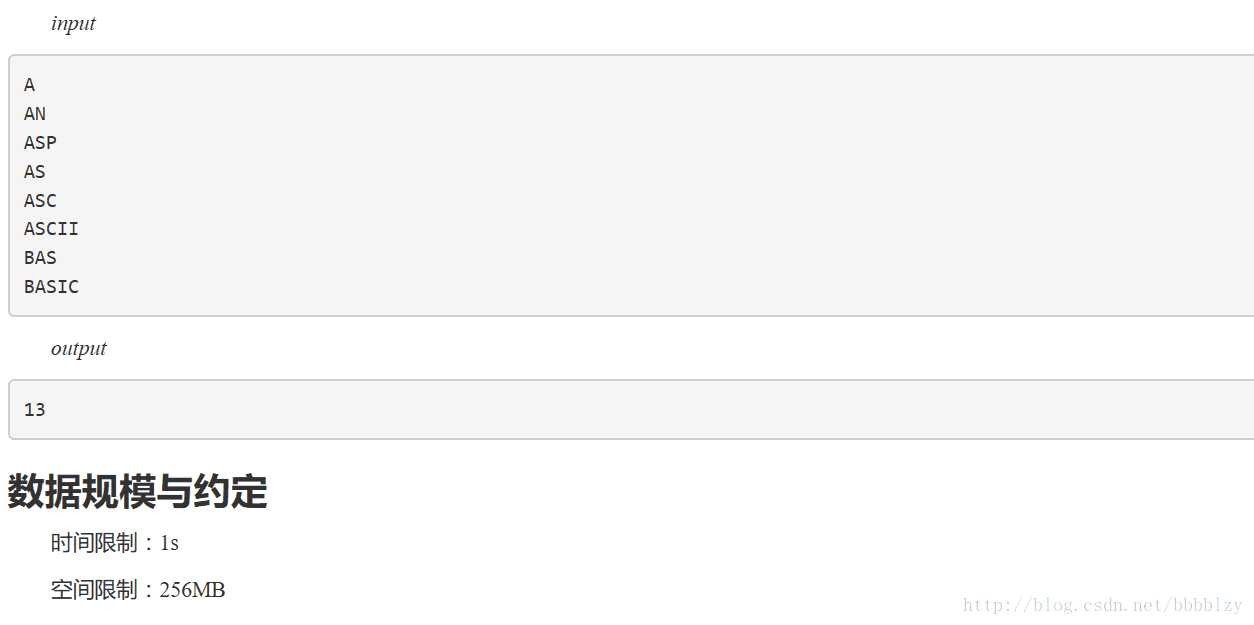
输入为一个单词列表,每一行仅包含一个单词和一个换行/回车符。每个单词仅由大写的英文字符组成,长度不超过63个字符。文件总长度不超过32K,至少有一行数据。
建议这样读入
while (getline(cin,s))
输出格式
仅包含一个整数和一个换行/回车符。该整数为单词列表对应的单词查找树的节点数。
模板题练练手哦
#include