Node.js C++插件实践指南
简介
熟悉Node.js的人都知道,Node.js是基于C++开发的一个JavaScript运行时,既然Node.js是用C++开发的,那么我能否将C++代码引入到Node.js中呢,这当然是可以的,这项技术被称为C++模块。官方对Node.js C++模块解释如下
Node.JS插件是使用C++编写的动态链接库,可以被Node.JS以require的形式载入,在使用时就像Node.js原生模块一样。主要被用于在Node.js的JavaScript和C或者C++库之间建立起桥梁的关系。
动态链接库,即window平台的.dll文件,linux下的.so文件。只不过Node.js模块导出的是.node文件。
动态链接库提供了一种方法,使进程可以调用不属于其可执行代码的函数,函数的可执行代码位于一个.dll (window)或.so (linux)文件中,该文件包含一个或多个已被编译、链接并与使用它们的进程分开存储的函数。说到动态链接库,不得不提一下静态链接库,静态链接库是指在编译阶段就把相关的函数库(静态库)链接,合成一个可执行文件。
那么,为什么需要C++模块?
JavaScript是基于异步,单线程的语言,对于一些异步任务非常占优势,但对于一些计算密集型的任务,也有明显的劣势(也许这是脚本语言的缺点)。换句话说使用JavaScript解释器执行JavaScript代码的效率通常是比直接执行一个C++编译好的二进制文件效率要低。除此之外,其实很多开源库是基于C++写的,比如图像处理库(ImageMagick),像我们团队使用的图像处理库,也是基于C++编写(用JavaScript写,性能达不到要求),所以对于一些问题使用C++来实现,效率和性能能有显著的提升,何乐而不为呢。
因此本文从C++插件基本原理以及几种编写方式来向读者介绍如何将C++代码加载到JavaScript中(编写Node.js C++模块)
原理浅析
前面提到,Node.js的C++模块是以动态链接库存在的(.node),那么Node.JS是如何加载C++模块的呢。首先Node.js的一个模块时一个遵循CommonJS规范书写的JavaScript源文件(.js),也可能是一个C++模块二进制文件(.node),这些文件通过Node.js中的 require() 函数被引入并使用。
在Node.js中引入C++模块的本质就是在Node.js运行时引入一个动态链接库的过程。在Node.js中通过 require() 函数加载模块,无论是Node.js模块还是C++模块。那么知道这个函数怎么实现的就知道怎么加载模块的。
为了揭开require的正面目,我们翻开Node.js的源码(Node.js Github)
在lib/internal/modules/cjs/loader.js,我们可以找到Module实现的JavaScript代码
function Module(id = '', parent) { // Class Module
this.id = id; // 模块id
this.path = path.dirname(id);
this.exports = {}; //
this.parent = parent;
updateChildren(parent, this, false);
this.filename = null;
this.loaded = false;
this.children = [];
}
Module._cache = ObjectCreate(null); // Object.create()
Module._pathCache = ObjectCreate(null); // 模块缓存
Module._extensions = ObjectCreate(null); // 对于文件名的处理
let wrap = function(script) {
// 用下面的wrapper包裹相应的js脚本
return Module.wrapper[0] + script + Module.wrapper[1];
};
const wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
继续往下翻,找到 require() 的实现
Module.prototype.require = function(id) {
// ...
return Module._load(id, this, /* isMain */ false);
// ...
};
Module._load = function(request, parent, isMain) {
// 省略了大部分代码...
const filename = Module._resolveFilename(request, parent, isMain);
// 模块在缓存中,则从缓存中加载
const cachedModule = Module._cache[filename];
if (cachedModule !== undefined) {
return cachedModule.exports;
}
// 内建模块
const mod = loadNativeModule(filename, request);
if (mod && mod.canBeRequiredByUsers) return mod.exports;
// 其他模块的处理
const module = new Module(filename, parent);
if (isMain) {
process.mainModule = module;
module.id = '.';
}
Module._cache[filename] = module;
// ...
module.load(filename); // 委托到load这个函数
return module.exports;
};
从上面的代码中可以看到模块的加载规则
- 如果模块在缓存里,则直接读缓存里的
- 如果的内建模块,则使用
loadNativeModule加载模块 - 其他情况使用
Module.proptype.load函数来加载模块
Module.prototype.load = function(filename) {
// 省略。。。
const extension = findLongestRegisteredExtension(filename);
// 终于到重点了,对每一种扩展,使用不同的函数来处理
Module._extensions[extension](this, filename);
this.loaded = true;
// 省略。。。
};
看到Module._extensions[extension](this, filename);这一行,对.js/.node/.json文件分别处理,让我们将目光放到Module._extensions的实现上
Module.prototype._compile = function(content, filename) {
// 省略。。。
const dirname = path.dirname(filename);
const require = makeRequireFunction(this, redirects);
let result;
/*
就是用上面的wrapper对content进行包裹,并将对应的参数传进去,所以这就是我们能在Node.js中直接使用require(), __filename, __dirname的原因
const wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];
*/
const compiledWrapper = wrapSafe(filename, content, this);
const exports = this.exports;
const thisValue = exports;
const module = this;
result = compiledWrapper.call(thisValue, exports, require, module,
filename, dirname);
return result;
};
// Native extension for .js
Module._extensions['.js'] = function(module, filename) {
// 省略。。。
const content = fs.readFileSync(filename, 'utf8');
module._compile(content, filename); // 将wrapper的内容扔到vm模块里去执行
};
// Native extension for .json
Module._extensions['.json'] = function(module, filename) {
const content = fs.readFileSync(filename, 'utf8');
// 省略。。。
module.exports = JSONParse(stripBOM(content));
};
// Native extension for .node
Module._extensions['.node'] = function(module, filename) {
// 省略。。。
return process.dlopen(module, path.toNamespacedPath(filename));
};
可以看到,对.node文件的处理是使用process.dlopen函数,但这个函数使用C++实现的(类似于C++插件的编写形式),在src/node_process_methods.cc下能找到这个函数的定义。
env->SetMethodNoSideEffect(target, "cwd", Cwd); //process.cwd()
env->SetMethod(target, "dlopen", binding::DLOpen); // process.dlopen()
env->SetMethod(target, "reallyExit", ReallyExit);
env->SetMethodNoSideEffect(target, "uptime", Uptime);
env->SetMethod(target, "patchProcessObject", PatchProcessObject);
是不是觉得很熟悉,这些的都是process上的方法,我们重点关注binding::DLOpen函数的实现,在src/node_binding.cc下
void DLOpen(const FunctionCallbackInfo& args) { // 里面涉及的V8数据类型,后面会介绍,其实这也算是一个C++插件
Environment* env = Environment::GetCurrent(args);
auto context = env->context();
CHECK_NULL(thread_local_modpending);
// 对照着上面的process.dlopen(module, filename)
if (args.Length() < 2) {
env->ThrowError("process.dlopen needs at least 2 arguments.");
return;
}
int32_t flags = DLib::kDefaultFlags;
if (args.Length() > 2 && !args[2]->Int32Value(context).To(&flags)) {
return env->ThrowTypeError("flag argument must be an integer.");
}
Local Node.js中将动态链接库的操作封装成一个DLib类,dlib->Open()其实是调用到uv_dlopen()函数来加载链接库。
int ret = uv_dlopen(filename_.c_str(), &lib_); // [out] _lib
uv_dlopen()是libuv中提供的一个加载动态链接库的函数,其返回一个uv_lib_t句柄类型
typeof strcut uv_lib_s uv_lib_t;
struct uv_lib_s {
char* errmsg;
void* handle;
};
handle保存链接库句柄。callback(exports, module, context);来调用一个编写的C++插件(对于Node.js v8才出现的N-API有另一种处理,但对于一般的C++插件其实就是类似于这种void Init(Local形式的函数,然后在上面调用),下面用一张流程图来描述整个加载过程
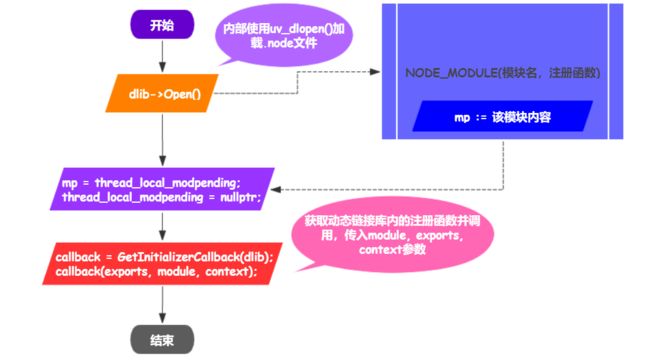
准备工作
终于到了实践环节,但别急,工欲善其事,必先利其器,先准备好开发环境。
编辑器
通过对比Vim/Vs Code/Qt Creator/CLoin几款编辑器后,得到一个结论: Vim没有代码提示(太菜了,不会配),Vs Code写C++代码异常的卡,动不动代码提示、高亮就全没了。Qt Creator写C++很不错,但是转手写JavaScript时很头疼,最后还是选择CLoin,无论是C++还是JavaScript都支持的非常好(jetbrian大法好),最重要的是提示不会写着写着就没了,只不过要稍微写写CmakeList.txt文件。

node-gyp
node-gyp是Node.js下的扩展构建工具,在安装C++插件时,通过一个binding.gyp描述文件来生成不同系统所需要的C++项目文件(UNIX 的 Makefile,Windows下的Visual Studio项目),然后调用相应的构建工具(gcc)来进行构建。
安装
mac 上保证安装了xcode(应用商店直接下载即可),然后命令行
npm install node-gyp -g
node-gyp的常用命令
- help
- configure 根据平台和node版本,生成相应的构建文件(生成一个build目录)
- build 构建node插件(根据build文件夹的内容,生成.node文件)
- clean 清除build目录
- rebuild 依次执行 clean、configure、build,可以方便的重新构建插件
- install 安装对应版本的node 头文件,代码提示必备
- list 列出当前安装的node头文件的版本
- remove 删除安装的node头文件
binding.gyp文件初窥
上面提到了binding.gyp文件,其实它是一个类似于python的dict的一个文件,基于python的dict语法,注释风格也和python一致。比如一个简单的binding.gyp如下
{
"targets": [
{
"target_name": "addon",
"sources": [
"addon.cpp" # 编译用的c++源文件
],
}
]
}
targets字段是一个数组,数组中每一个元素都是将要被node-gyp构建的C++模块,target_name是必须的,表示模块名,编译时会通过该名字来命名.node文件,sources字段也是必须的,用于将哪些文件当作源码进行编译。
- 基本类型
类似于python的数据类型,gyp里面的基本类型只有 String, Integer, Lists, Dictionaries
- 关键字段
下面列举一些比较常见的字段(键)
targets, target_name,sources上面解释过了,这里就不解释了。
include_dirs: 头文件搜索路径,-I标识,比如gcc -I some.c -o some.o
defines: 为目标添加预编译宏,-D标识,比如gcc -D N=1000 some.c -o some.i,直接在源文件中添加#define N 1000
libraries: 为编译添加链接库,-L编译标识
cflags: 自定义编译标识
dependencies: 如果代码中用了第三方的C++代码,就需要在binding.gyp中将这个库编译为静态链接库,然后在主target使用dependencies将第三方库依赖进来。
conditions: 分支条件处理字段
type: 编译类型,有三种值:shared_library(动态链接库),static_library(静态链接库),loadable_module(Node.js可直接载入的C++扩展动态链接库, binding.gyp的默认类型)
variables: 变量字段,可以写一些变量在gyp文件中使用
下面是一个简单举个简单的例子,更多示例请参考: https://github.com/Node.js/node-gyp/wiki/%22binding.gyp%22-files-out-in-the-wild
{
"targets": [
{
"target_name": "some_library",
"sources": [
"some.cc"
]
},
{
"target_name": "main_addon",
"variables": { # 定义变量
"main": "main.cc",
"include": ["./lib", "../src"]
},
"cflags": ["-Werror"] # g++编译标识
"sources": [
"<(main)" # 使用 < 这种方式引用变量
],
"defines": [ # 定义宏
"MY_NODE_ADDON=1"
],
"include_dirs": [
"/usr/local/node/include",
"<@(include)" # 使用 <@ 引用数组变量
],
"dependencies": [ # 定义依赖
"some_library" # 依赖上面的some_library
],
"libraries": [
"some.a", # mac
"xxx.lib" # win
],
"conditions": [ # 条件,其格式如下
[
["OS=='mac'", {"sources": ["mac_main.cc"]}],
["OS=='win'", {"sources": ["win_main.cc"]}],
]
]
}
]
}
- 变量
在gyp中主要有三类变量:预定义变量、用户定义变量,自动变量。
预定义变量:比如OS变量,表示当前的操作系统(linux, mac, win)
用户定义变量:在variables字段下定义的变量。
自动变量:所有的字符串键名都会被当作自动变量处理,变量名是键名加上_前缀。
变量的引用:以<开头或>开头,用@来区分不同类型的变量。<(VAR)或>(VAR),如果VAR是一个字符串,则当作一个正常的字符串处理,如果VAR是一个数组,则按空格拼接数组每一项的字符串。<@(VAR)或>@(VAR),该指令只能用在数组中,如果VAR是一个数组,数组的内容会一一插入到当前所在的数组中,如果是字符串则会按指定分隔符转成数组再一一插入到当前所在数组里。
- 指令
指令与变量类似,不过比变量高级一点,GYP读到指令时会启动一个进程去执行这条展开的指令,其语法格式是: 以开头或者开头的,与变量相同的一点是也是用于数组的。
{
# ...
"include_dirs": [
" # 相当于在cmd下执行 node -e "require('nan')",并将结果放在include_dirs里
]
# ...
}
- 条件分支
conditions字段,其值是一个数组,那么第一个元素是一个字符串,表示条件,条件格式跟python的条件分支一样,例如"OS=='mac' or OS=='win'"或者"VAR>=1 and VAR <= 2"。第二个元素则是一个对象,用于根据条件合并到最近的一个上下文中的内容。
- 列表过滤器
用于值是数组的键,键名以!或者/结尾,其中键名以!结尾是一个排除过滤器,表示这里的键值将被从无!的同名键中排除。键名以/结尾是一个匹配过滤器,表示通过正则匹配出相应结果,然后以指定方式(include或者exclude)进行处理。
{
"targets": [
{
"target_name": "addon",
"sources": [
"a.cc", "b.cc", "c.cc", "d.cc"
],
"conditions": [
["OS=='mac'", {"sources!": ["a.cc"]}], # 排除过滤器,条件成立则从sources中排除掉a.cc
["OS=='win'", {"sources/": [ # 匹配过滤器
["include", "b|c\\.cc"], # 包含b.cc和c.cc
["exclude", "a\\.cc"] # 排除 a.cc
]}]
]
}
]
}
- 合并
从上面可以看到GYP的许多操作都是通过字典和列表项合并在一起实现(条件分支),在合并操作时,最重要的是识别源和目标值之间的区别。
在合并一个字典时,遵循以下规则
- 如果键在目标字典中不存在,则将其插入
- 如果键已经存在
- 如果值是字典,则源和目标值字典执行字典合并过程
- 如果值是列表,则源和目标值列表执行列表合并过程
- 如果值是字符串或整数,则直接将源值替换
在合并列表时,可根据附加到键名的后缀进行合并
- 键以
=结尾,源列表完全替换目标列表 - 键以
?结尾,则只有当键不在目标时,才会将源列表设置为目标列表 - 键以
+结尾,则源列表会被追加到目标列表 - 键没有修饰符,则源列表内容附加到目标列表
例如
# 源
{
"include_dirs+": [
"/public"
]
}
# 目标
{
"include_dirs": [
"/header"
],
"sources": [
"aa.cc"
]
}
# 合并后
{
"include_dirs": [
"/public",
"/header"
],
"sources": [
"aa.cc"
]
}
第一个C++插件:Hello World
首先使用node-gyp install安装对应版本的Node.js头文件,安装完后头文件目录位于~/.node-gyp/node-version/include/node目录下, 或者在你的Node.js安装目录找到include目录,里面就是Node.js的头文件。

目录结构以及C++代码如下,首先使用NODE_MODULE宏去注册一个C++模块,对应的Init函数接受Local参数,这里的exports类似与Node.js中的module.exports,所以往exports挂载函数即可。

编写CMakeLists.txt,使用include_directories将node的头文件链接过来,编辑器代码提示时非常有用
cmake_minimum_required(VERSION 3.15)
project(cpp_addon_test)
set(CMAKE_CXX_STANDARD 14)
# 链接node 头文件,代码提示时有用
include_directories(/Users/dengpengfei/.node-gyp/12.6.0/include/node)
add_executable(cpp_addon_test main.cpp)

编写binding.gyp,将sources指定为main.cpp
{
"targets": [
{
"target_name": "cpp_addon",
"sources": [
"main.cpp"
]
}
]
}
使用node-gyp对C++文件进行编译,使用node-gyp configure生成配置文件,node-gyp build构建C++插件(生成.node文件)。或者使用node-gyp rebuild直接构建C++插件。
index.js引入cpp_addon.node文件
const cpp = require("./build/Release/cpp_addon");
console.log(cpp.hello());
运行结果如下
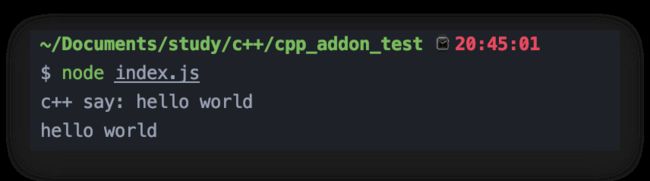
Hello world!不过瘾?那来看看几个简单的C++函数以及BigNumber类的封装吧。来看几个工具方法,lib/utils.h
int findSubStr(const char* str, const char* subStr); // 查找子串位置,kmp算法
int subStrCount(const char* str, const char* subStr); // 字串在源字符串中出现次数,kmp算法
以及BigNumber包装类,lib/bigNumber.h
class BigNumber: node::ObjectWrap {
public:
static void Init(Local这里使用了node::ObjectWrap封装类,将C++ Class与JavaScript Class相连接的工具类(位于 node_object_wrap.h头文件中,下文会具体介绍这个工具类)。由于篇幅有限,这里只展示函数以及类的定义,相关实现以及示例可以参考GitHub:https://github.com/sundial-dreams/node_cpp_addon
主函数main.cpp
#include
#include
#include
#include
#include
#include "lib/utils.h"
#include "lib/bigNumber.h"
const int N = 10000;
using namespace v8;
// 对findSubStr(const char*, const char*)的包装
void FindSubStr(const FunctionCallbackInfo& args) {
Isolate* isolate = args.GetIsolate();
if (!args[0]->IsString() || !args[1]->IsString()) {
isolate->ThrowException(Exception::TypeError(ToLocalString("type error")));
}
// 将Local 转化到 char*类型,下文会介绍
String::Utf8Value str(isolate, args[0].As());
String::Utf8Value subStr(isolate, args[1].As());
int i = findSubStr(*str, *subStr);
args.GetReturnValue().Set(Number::New(isolate, i));
}
// 对 subStrCount(const char*, const char*)的包装
void SubStrCount(const FunctionCallbackInfo& args) {
Isolate* isolate = args.GetIsolate();
if (!args[0]->IsString() || !args[1]->IsString()) {
isolate->ThrowException(Exception::TypeError(ToLocalString("type error")));
}
// 将Local 转化到 char*类型,下文会介绍
String::Utf8Value str(isolate, args[0].As());
String::Utf8Value subStr(isolate, args[1].As());
int i = subStrCount(*str, *subStr); // 调用c++侧的方法
args.GetReturnValue().Set(Number::New(isolate, i));
}
void Init(Local binding.gyp文件如下
{
"targets": [
{
"target_name": "addon",
"sources": [
"lib/utils.cpp",
"lib/bigNumber.cpp",
"main.cpp"
]
}
]
}
就是将lib/utils.cpp,和lib/bigNumber.cpp都加入到sources里,使用node-gyp rebuild构建插件。
然后JavaScript侧
const { findSubStr, subStrCount, BigNumber } = require("./build/Release/addon");
console.log("subStr index is: ", findSubStr("abcabdacac", "cab"));
console.log("subStr count is: ", subStrCount("abababcda", "ab"));
let n = new BigNumber("9999");
n.add(n);
console.log("add: ", n.val());
n.multiply("12222");
console.log("multiply: ", n.val());
运行一下
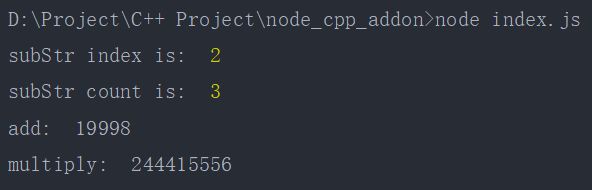
编写C++插件的几种方式
随着Node.js C++插件编写方式的变化, 本文总结出了以下几种编写C++插件的方式
- 原生拓展
- 使用NAN
- 使用N-API
- 使用node-addon-api
原生扩展
原生的方式是指直接使用内部的V8,libuv和Node.js库来创建插件,这种方式编写一个插件可能比较复杂,涉及到以下组件和API。
- V8: JavaScript运行时,用于解释执行JavaScript。V8提供了创建对象,调用函数等机制。
- libuv: 实现Node.js事件循环。
- 内部Node.js库: Node.js本身会导出插件可以使用的C++API,比较重要的是
node::ObjectWrap类。 - Node.js其他静态链接库: 包括OpenSSL,zlib等,可以使用zlib.h,openssl等来在自己的插件中引用。
V8
V8(v8文档)引擎是一个可独立运行的JavaScript运行时,回顾浏览器端和Node.js端的区别,大概就是对V8引擎的上层封装不一样,也就是说我们可以拿着V8引擎自己包装一个自己的Node.js。
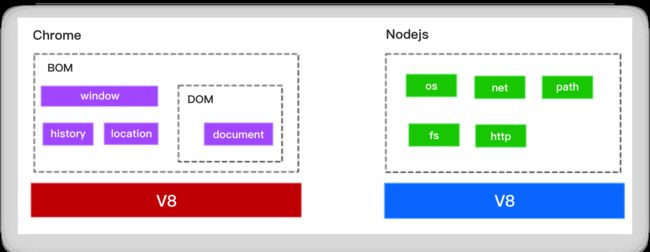
Node.js是V8引擎的一个宿主,其很大部分都是直接使用Chrome V8所暴露出来的API。
V8的一些基本概念
- Isolate
-
一个Isolate就是一个V8引擎实例,也称隔离实例(Isolated instance),实例内部拥有完全独立的各种状态,包括堆管理,垃圾回收等。
-
Isolate通常传递给其他V8 API函数,并提供一些API来管理JavaScript引擎的行为或者查询一些相关信息,比如内存使用情况。
-
一个Isolate生成的任何对象都不能在另一个Isolate中使用。
-
在Node.js插件中Isolate可通过以下方式获取
// 直接获取
Isolate* isolate = Isolate::GetCurrent();
// 如果有Context
Isolate* isolate = context->GetIsolate();
// 在binding函数中有const FunctionCallback& args
Isolate* isolate = args.GetIsolate();
// 如果有Environment
Isolate* isolate = env->isolate();
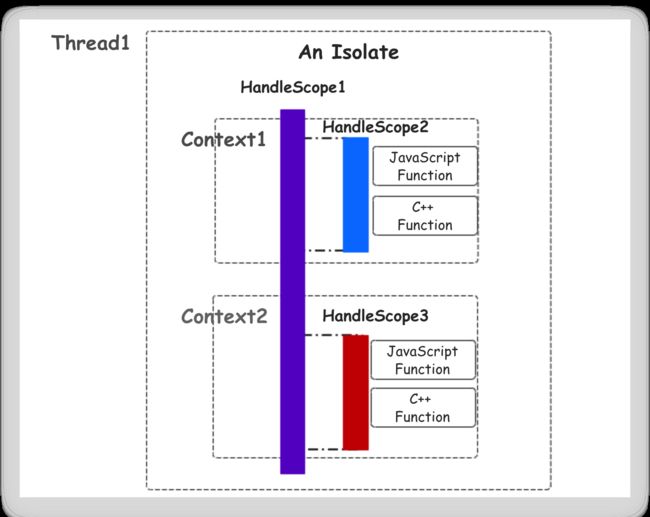
2. Context
可以理解为浏览器上的window,其实Node也有自己的context,即global,甚至我们也可以对context进行包装,比如
Local<ObjectTemplate> global = ObjectTemplate::New(isolate);
Local<String> key = String::NewFromUtf8(isolate, "CONST", NewStringType::kNormal).ToLocalChecked();
Local<String> value = String::NewFromUtf8(isolate, "I am global value", NewStringType::kNormal).ToLocalChecked();
global->Set(key, value);
Local<Context> myContext = Context::New(isolate, nullptr, global); // 使用这种方式创建Context,然后现在的Context就是 { CONST: "I am global value" }
- Script
就是一个包含一段已经编译好的JavaScript脚本对象,数据类型是Script,并且在编译时与一个Context进行绑定。我们可以实现一个eval函数,将一段JavaScript代码进行编译,并且封装一个自己的Context,来看C++代码
#include
#include
using namespace v8;
// 这块的代码并不复杂
void Eval(const FunctionCallbackInfo& args) {
Isolate* isolate = args.GetIsolate(); // 拿到 isolate
HandleScope handleScope(isolate); // 定义句柄作用域
Local context = isolate->GetCurrentContext(); // 拿到Context
// 定义一个global对象并为他设置相应的键和值
Local global = ObjectTemplate::New(isolate);
Local key = String::NewFromUtf8(isolate, "CONST", NewStringType::kNormal).ToLocalChecked();
Local value = String::NewFromUtf8(isolate, "I am global value", NewStringType::kNormal).ToLocalChecked();
global->Set(key, value);
Local printStr = String::NewFromUtf8(isolate, "print", NewStringType::kNormal).ToLocalChecked(); // let printStr = "print";
global->Set(printStr, FunctionTemplate::New(isolate, [](const FunctionCallbackInfo& args) -> void {
Isolate* isolate = args.GetIsolate();
for (size_t i = 0; i < args.Length(); i++) {
Local str = args[i].As();
String::Utf8Value s(isolate, str); // 数据转换,将Local转到char*,以便用cout输出
std::cout<<*s<<" ";
}
std::cout< myContext = Context::New(isolate, nullptr, global);
Local code = args[0].As();
// 编译JavaScript代码
Local