InnoDB存储引擎为什么选择B+树构建索引
索引是对数据库表中一个或多个列的值进行排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B树及其变种。索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,它从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。
索引在 MySQL 数据库中分三类:
- B+树索引
- Hash索引
- 全文索引
我们在工作开发中最常接触到的是InnoDB存储引擎中的B+树索引。要了解 B+树索引,就不得不提二叉查找树、B树这两种数据结构。B+树就是由它们演化来的。
二叉查找树
对一张表建立二叉查找树索引的示意图如下:
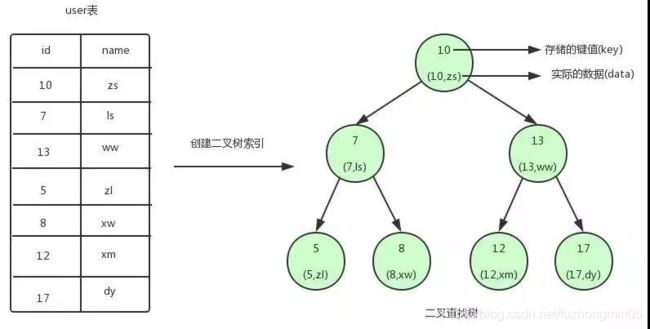
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。查找的时间复杂度是 O(logN)。如上图,利用二叉查找树最多只需要3次即可找到匹配的数据。如果在表中一条条的查找的话,最多需要6次才能找到。虽然利用二叉查找树查找性能很高,但它不足以支持按照区间快速查找数据。
为了让二叉查找树支持按照区间来查找数据,我们可以对它进行这样的改造:树中的节点并不存储数据本身,而是只是作为索引。除此之外,我们把每个叶子节点串在一条链表上,链表中的数据是从小到大有序的。经过改造之后的二叉树如下图所示。
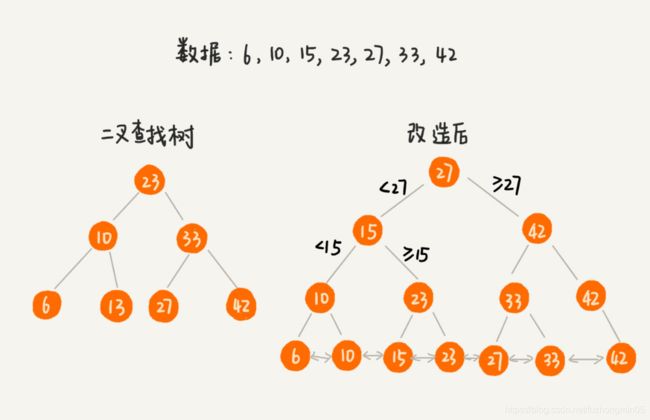
改造之后,如果我们要寻找某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。
如果我们用树这种数据结构作为索引的数据结构,那我们每查找一次数据就需要从磁盘中读取一个节点,也就是一个磁盘块。二叉查找树每个节点只存储一个键值和数据的。说明每个磁盘块仅仅存储一个键值和数据!但是,我们要为几千万、上亿的数据构建索引,如果将索引存储在内存中,尽管内存访问的速度非常快,查询的效率非常高,但是,占用的内存会非常多。比如,我们给1亿个数据构建二叉查找树索引,那索引中会包含大约1亿个节点,每个节点假设占用16个字节,那就需要大约1GB的内存空间。给一张表建立索引,我们需要1GB的内存空间。如果我们要给10张表建立索引,那对内存的需求是无法满足的。如何解决这个索引占用太多内存的问题呢?
可以借助时间换空间的思路,把索引存储在硬盘中,而非内存中。我们都知道,硬盘是一个非常慢速的存储设备。通常内存的访问速度是纳秒级别的,而磁盘访问的速度是毫秒级别的。读取同样大小的数据,从磁盘中读取花费的时间,是从内存中读取所花费时间的上万倍,甚至几十万倍。这种将索引存储在硬盘中的方案,尽管减少了内存消耗,但是在数据查找的过程中,需要读取磁盘中的索引,因此数据查询效率就相应降低很多。
二叉查找树经过改造之后,支持区间查找的功能就实现了。不过,为了节省内存,如果把树存储在硬盘中,那么每个节点的读取(或者访问),都对应一次磁盘IO操作。树的高度就等于每次查询数据时磁盘IO操作的次数。我们前面讲到,比起内存读写操作,磁盘IO操作非常耗时,所以我们优化的重点就是尽量减少磁盘IO操作,也就是,尽量降低树的高度。那如何降低树的高度呢?
B树
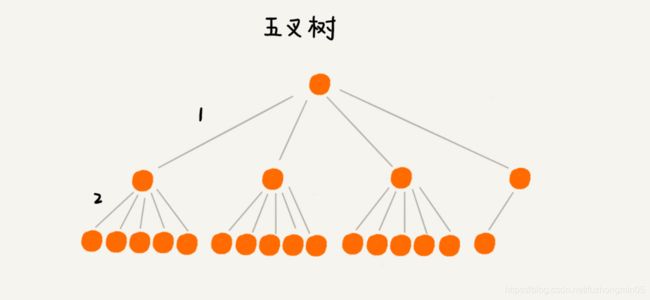
如果我们把索引构建成m叉树,高度是不是比二叉树要小呢?如图所示,给16个数据构建二叉树索引,树的高度是4,查找一个数据,就需要4个磁盘IO操作(如果根节点存储在内存中,其他节点存储在磁盘中),如果对16 个数据构建五叉树索引,那高度只有2,查找一个数据,对应只需要2次磁盘操作。如果m叉树中的m是100,那对一亿个数据构建索引,树的高度也只是3,最多只要3次磁盘IO就能获取到数据。磁盘IO变少了,查找数据的效率也就提高了。

为了解决二叉查找树的一个节点只能存储一个键值和数据的弊端,我们应该寻找一种单个节点可以存储多个键值和数据的搜索树,B树就是这样一种平衡的多路查找树,下图即是一棵B树:
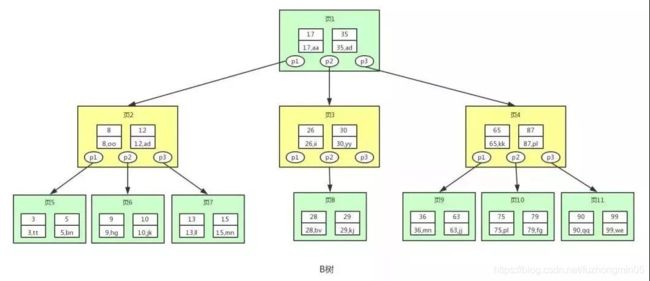
上图中的p节点为指向子节点的指针,二叉查找树其实也有,只是图里省略了。上图中的每个节点称为页,页就是我们上面说的磁盘块,在MySQL中数据读取的基本单位都是页,所以我们这里叫做页更符合MySQL中索引的底层数据结构。
从上图可以看出,B树相对于二叉查找树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树是3阶B树,高度也会很低。基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比二叉查找树高很多。
B树为什么要设计成多路?为了进一步降低树的高度,路数越多树的高度越低,如果设计成无限多路就退化成有序数组了。
B树的使用场景决定了它的设计。B树经常用做文件系统的索引,为什么文件系统的索引喜欢用B树而不是红黑树或有序数组呢?文件系统或数据库的索引都是在硬盘上的,如果数据量很大的话,索引树不一定能一次性加载到内存中,如果一棵树根本无法一次性加载进内存,该如何利用它作查找?此时B树多路的威力就体现出来了,可以每次只加载B树的一个节点,然后一步步往下找。如果整棵树的完整结构都在内存中,那么红黑树当然比B树效率高,但是当树大到不能完整加载进内存要涉及到磁盘IO时,B树就更优了。比起内存读写操作,磁盘IO操作非常耗时,所以我们优化的重点就是尽量减少磁盘IO操作,也就是,尽量降低树的高度。
B+树
了解了B树后再来了解下它的变形版:B+树,它比B树的查询性能更高。下图就是一颗阶数为4的B+树。
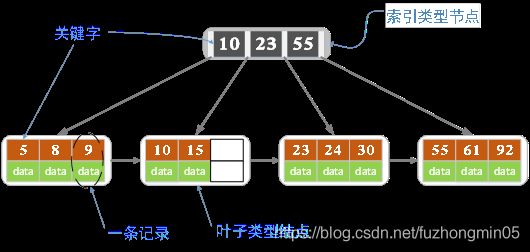
B+树的定义没有找到官方的定义,有些博客中提到的定义还有争议,但是这些并没有多大影响,只是一点小小的差异。
B+树是在B树基础上改造的,用作数据库的索引,它的数据都在叶子结点并且叶子结点之间还加了指针形成链表,为什么要这样设计?使用场景决定设计,B+树经常用作数据库的索引,数据库中的select操作并不是只返回一条数据而是多条。如果用B树的话,可能需要跨层访问,而B+树由于所有数据都在叶子结点,不用跨层,同时链表有序只要找到首尾,就可以定位到所有符合条件的数据。这就是B+树比B树更优的地方。
Hash更快,为什么数据库还用B+树作索引?与业务场景有关,如果只选一个数据,hash确实更快,但是select经常要选择多条,这时由于B+树索引有序并且又有链表相连,它的查询效率比hash更快。而且数据库的索引是存储在磁盘上的,数据量大的情况下无法一次性装入内存,B+树的多路设计可以允许索引数据分批加载到内存,树的高度也很低,提高查找效率。