用最少的公式看懂Attention机制原理
Attention
Encoder-Decoder模型
enco-deco模型是seq2seq任务的一种实现方式,比如在英翻中任务中,encoder模块用来编码一句英文句子,在最后一个时刻用一个context-vector存储整句话的信息。
在decoder部分,通过context-vector解码出每个时刻对应的中文单词。
因为这一结构,encoder-decoder有一些固有的弊端:
1: context-vector可能不能覆盖输入句子的所有信息,先输入的信息会被后输入的信息覆盖。
2: 在decoder中,解码每个时刻的单词应该是对encoder每个时刻的vector有不同权重,
比如翻译I have a pen -> 我有一只笔。实际上翻译 ‘笔’ 的时候自然的应该多关注pen,但是enco-deco结构中只能做到把I have a pen整句话压缩到一个vector中。不能做到对不同时刻有不同的关注度。
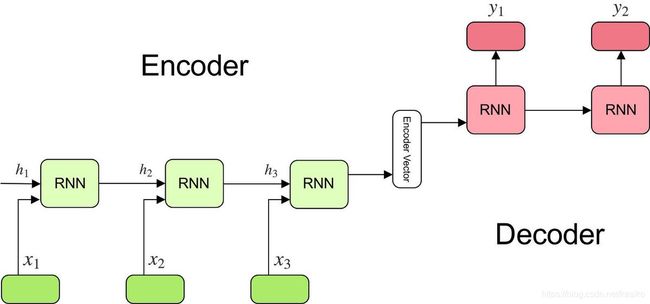
为解决上述问题,attention思想被提出。
attention机制本质上是,在计算decoder中的 t时刻的隐藏状态时(记为query), 对输入序列的信息做加权求和。
那权重是怎么计算的呢?t时刻的输入信息分成key 和value对,计算query和key的相似度, 这个相似度即为权重,再乘对应的value,就得到了解码器t时刻的隐藏状态对输入序列t时刻的注意程度。
A t t e n t i o n ( q u e r y , i n p u t ) = ∑ i = 1 L S i m i l a r i t y ( q u e r y , k e y i ) ∗ V a l u e i Attention(query, input) = \sum_{i=1}^{L}Similarity(query,key_{i}) *Value_{i} Attention(query,input)=∑i=1LSimilarity(query,keyi)∗Valuei
相似度的计算一般通过点积或者余弦相似实现。
Transformer中的encoder部分
图片来源
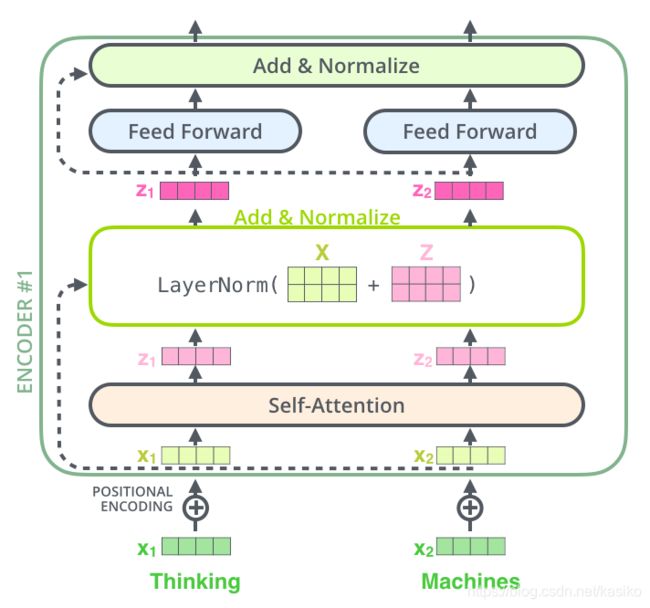
解释一下这幅图的整个流程:
x1 是词向量,可以由word2vec等静态词向量直接抽取出来,也可以随机初始化值,在做有标签任务时候通过反向传播当作一些参数来更新。
positional encoding是位置编码,通过上边的解释我们可以发现attention虽然可以对不同时刻由不同的关注度,但是输入序列本身没有可以表示顺序的方法,比如上图所示,Thnking machines 有个前后顺序,需要加位置编码来表示thinking的位置和machines的位置。
这个编码的实现:
P E ( p o s , 2 i ) = s i n ( p o s 100 0 2 i d m o d e l ) ) PE(pos, 2i) = sin(\frac{pos}{1000^{\frac{2i}{d_{model}}}})) PE(pos,2i)=sin(1000dmodel2ipos))
P E ( p o s , 2 i + 1 ) = c o s ( p o s 100 0 2 i d m o d e l ) ) PE(pos, 2i+1) = cos(\frac{pos}{1000^{\frac{2i}{d_{model}}}})) PE(pos,2i+1)=cos(1000dmodel2ipos))
pos 代表当前单词在input句子中的位置,i 代表vector中每个值的下标, 在偶数位置使用sin编码,奇数位置使用cos编码。
词向量+位置编码 = x1
x1 通过 self-attention 层发生了什么呢?
在self-attention中, 初始化了3 个共享矩阵 W q , W k , W v W^{q} ,W^{k}, W^{v} Wq,Wk,Wv(在input中每个时刻的单词都公用同一套矩阵), 分别代表前文解释的query, key, values。
分别用x1 与q,k,v 三个矩阵相乘得到 q1, k1, v1三个向量。 注意这不是个时许模型,同一时刻x2 也生成了q2, k2, v2
用 q1 去分别注意k1, k2, 得到相似度,然后分别乘对应的value, 得到最终的权重。
图片来源
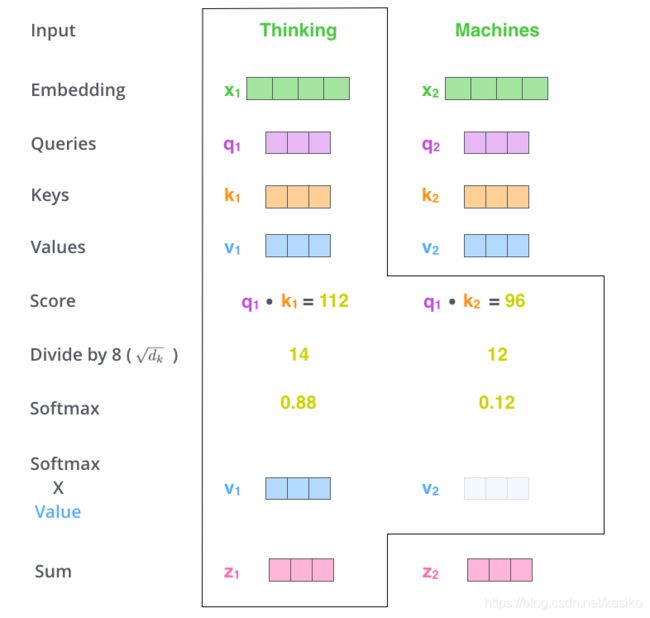
拿到权重数值之后用softmax做归一化,计算出真正的权重。在这之前论文中要除根号key vector的纬度,意味不明。
最后用权重分别乘v1, v2, 结果相加就得到了t1时刻 thinking 的最终的向量表示Z1, 这个向量既包含了thingking本身的信息, 也包含了这个句子中其他时刻的单词的信息。
Machines的Z2也是同样方法得到的。
现在我们在上上个图中, 已经走完了最重要的部分, 从 self-attention层中成功出来了。
下一步是送入 Normalize层, 标准化层通常的目的都是为了把输入转化位均值为0,方差为1的数据。 通常在送入激活函数之前进行这个操作。
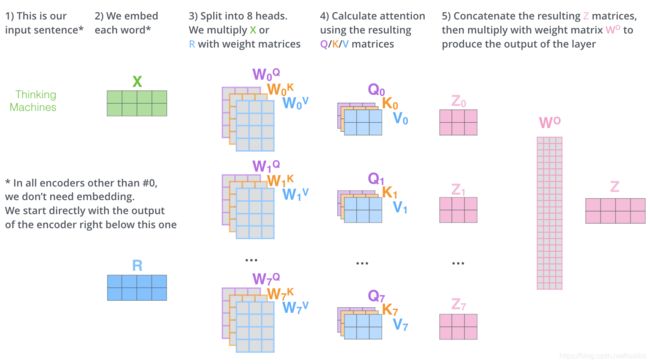
实际在应用self-attention的时候, 通常采用 ’多头注意力机制‘ , 什么是多头呢?
其实就是初始化了多套q,k,v矩阵。
原作者认为多套qkv矩阵可以捕捉多个方面的信息, 注意最后多个空间合成的向量是直接拼接成的,没有计算过程。
总结:
attention 结构其实是比门控制的时序模型LSTM, GRU 等简单的多的一个结构。
由于attention可以并行计算, 没有时序依赖关系,所以计算速度很快。同时又可以像rnn结构一样捕捉到句子中其他位置单词的信息,而且他其实是双向的信息都可以看到的。
基于self-attention训练的bert以及其衍生的一系列模型已经成了一部分自然语言处理任务的base-method解决方法。
链接:
Attention Is All You Need