Solr笔记
1 课程计划
1、solr介绍
a). 什么是solr
b). Solr和lucene的区别
2、Solr的安装配置(重点)
3、Solr的基本使用(重点)
4、Solrj的使用(重点)
5、京东案例(重点)
2 Solr介绍
2.1 什么是solr
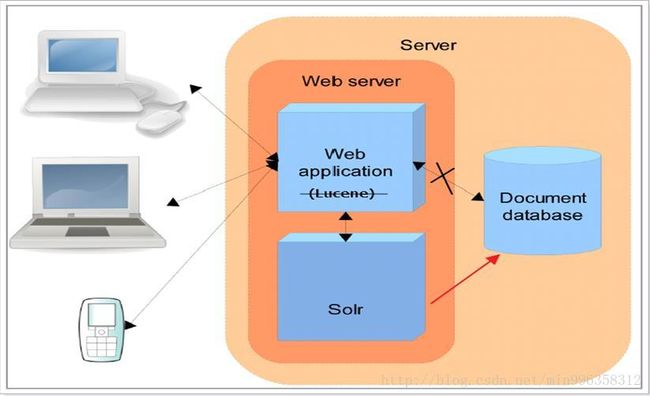
Solr是apache的顶级开源项目,它是使用java开发 ,基于lucene的全文检索服务器。
Solr比lucene提供了更多的查询语句,而且它可扩展、可配置,同时它对lucene的性能进行了优化。
Solr是如何实现全文检索的呢?
索引流程: solr客户端(浏览器、java程序)可以向solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档,通过该文档,solr实现对索引的维护(增删改)
搜索流程: solr客户端(浏览器、java程序)可以向solr服务端发送GET请求,solr服务器返回一个xml文档。
Solr同样没有视图渲染的功能。
2.2 Solr和lucene的区别
Lucene 是一个全文检索引擎工具包,它只是一个jar包,不能独立运行,对外提供服务。
Solr 是一个全文检索服务器,它可以单独运行在servlet容器,可以单独对外提供搜索和索引功能。Solr比lucene在开发全文检索功能时,更快捷、更方便。
3 Solr安装配置
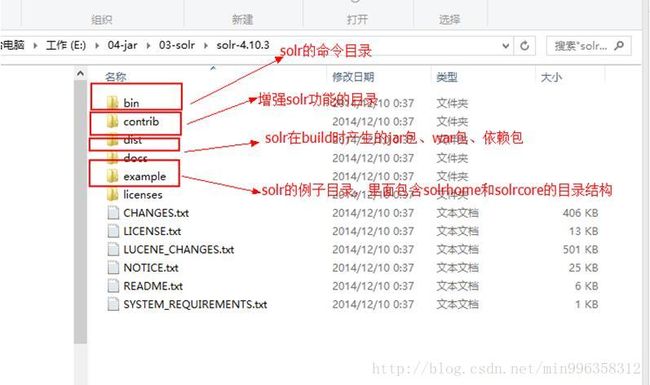
3.1 下载solr
Solr和lucene的版本是同步更新的,最新的版本是5.2.1
本课程使用的版本:4.10.3
下载地址:http://archive.apache.org/dist/lucene/solr/
下载版本:4.10.3
Linux下需要下载lucene-4.10.3.tgz,windows下需要下载lucene-4.10.3.zip。

3.2 运行环境
- Jdk:1.7及以上
- Solr:4.10.3
- Mysql:5X
- Web服务器:tomcat 7
3.2.1 初始化数据库脚本

3.3 Solr安装配置
3.3.1 Solr的安装部署
第一步:安装tomcat
第二步:将以下的war包,拷贝到tomcat的webapps目录下

第三步:解压缩war包
解压缩之后,将war包删掉

第四步:添加solr的扩展服务包

将以上jar包,添加到以下目录
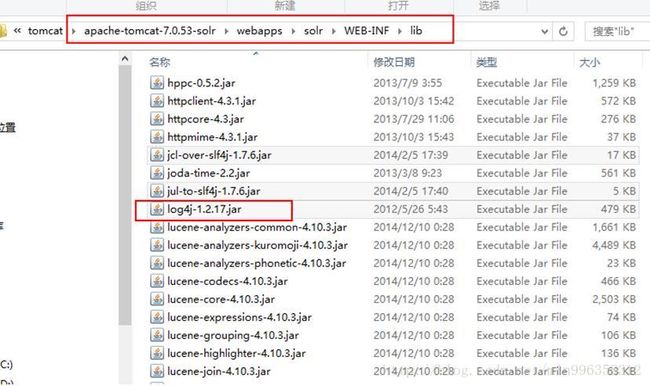
第五步:添加log4j.properties
将以下目录的文件进行拷贝

复制到以下目录

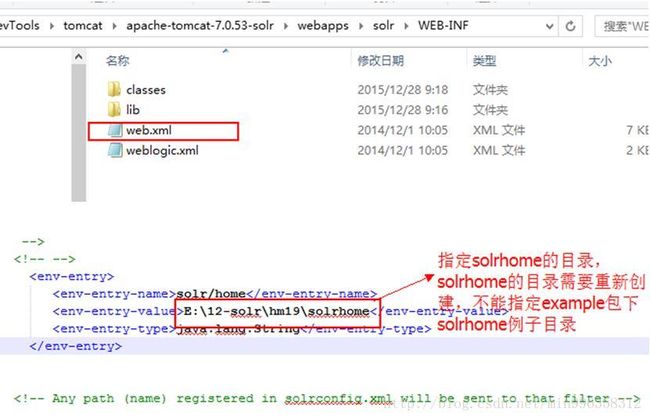
第六步:在web.xml中指定solrhome的目录
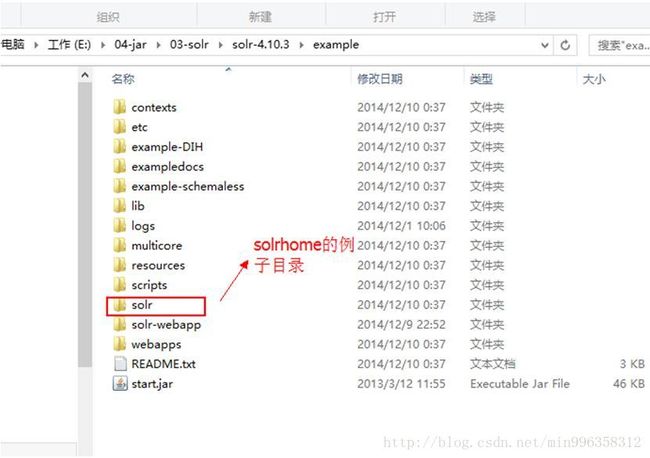
3.3.2 Solrcore的安装
3.3.2.1 Solrcore和solrhome
Solrhome是solr服务运行的主目录,一个solrhome目录里面包含多个solrcore目录,一个solrcore目录里面包含了一个solr实例运行时所需要的配置文件和数据文件。
每一个solrcore都可以单独对外提供搜索和索引服务。
多个solrcore之间没有关系。
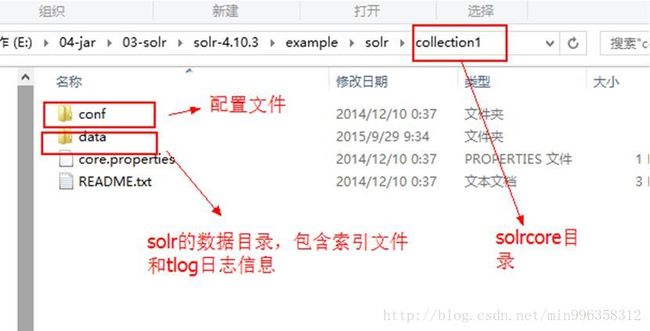
3.3.2.2 Solrcore和solrhome的目录结构
Solrhome的目录结构

Solrcore目录
3.3.2.3 Solrcore的安装
安装solrcore需要先安装solrhome
将以下目录的文件进行拷贝

复制到以下目录

这样solrhome和solrcore就安装成功了。
3.3.2.4 Solrcore配置
在solrcore的conf目录下,有一个solrconfig.xml的配置文件,该配置文件,配置来solrcore的运行信息

在该文件中,主要配置三个标签:lib标签、datadir标签、requestHandler标签
如果对该文件不进行配置也可以,即使用默认的配置项。
3.3.2.4.1 Lib 标签
Solrcore需要添加一个扩展依赖包,通过lib标签来指定依赖包的地址
solr.install.dir: 表示solrcore的安装目录
将以下目录的文件进行拷贝

复制到以下目录
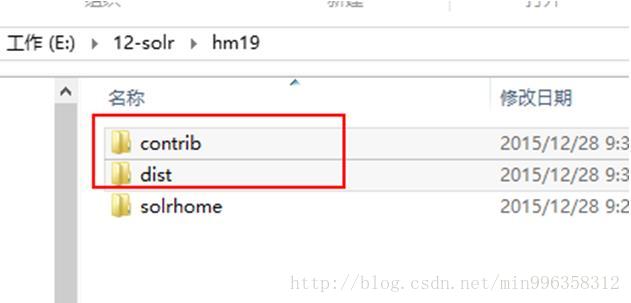
修改lib标签

3.3.2.4.2 datadir标签
每个SolrCore都有自己的索引文件目录 ,默认在SolrCore目录下的data中。

data数据目录下包括了index索引目录 和tlog日志文件目录。
如果不想使用默认的目录也可以通过solrConfig.xml更改索引目录 ,如下:
![]()
3.3.2.4.3 requestHandler标签
requestHandler请求处理器,定义了索引和搜索的访问方式。
通过/update维护索引,可以完成索引的添加、修改、删除操作。
![]()
提交xml、json数据完成索引维护,索引维护小节详细介绍。
通过/select搜索索引。
![]()
设置搜索参数完成搜索,搜索参数也可以设置一些默认值,如下:
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="echoParams">explicitstr>
<int name="rows">10int>
<str name="wt">jsonstr>
<str name="df">textstr>
lst>
requestHandler>3.4 solr界面介绍
启动solr服务
http://localhost:8080/solr

3.4.1 Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
3.4.2 Logging
Solr运行日志信息
3.4.3 Cloud
Cloud即SolrCloud,即Solr云(集群),当使用Solr Cloud模式运行时会显示此菜单,该部分功能在第二个项目,即电商项目会讲解。
3.4.4 Core Admin
Solr Core的管理界面。在这里可以添加SolrCore实例。
3.4.5 java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。
3.4.6 Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
3.4.7 Core selector(重点)
选择一个SolrCore进行详细操作,如下:

3.4.7.1 Analysis(重点)

通过此界面可以测试索引分析器和搜索分析器的执行情况。
注:solr中,分析器是绑定在域的类型中的。
3.4.7.2 dataimport
可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。
默认没有配置,需要手工配置。
3.4.7.3 Document(重点)
通过/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
通过此菜单可以创建索引、更新索引、删除索引等操作,界面如下:
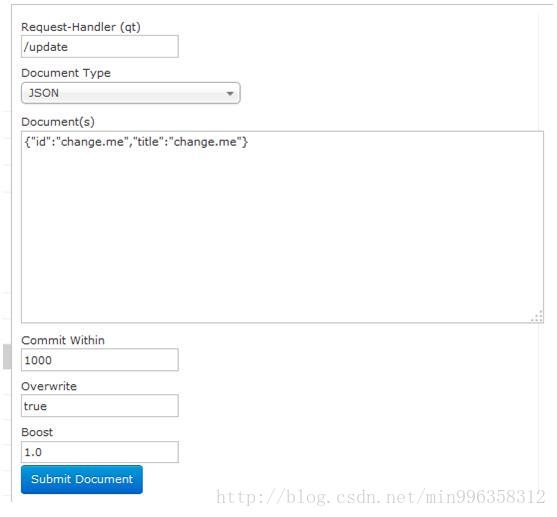
- overwrite=”true” : solr在做索引的时候,如果文档已经存在,就用xml中的文档进行替换。
- commitWithin=”1000” : solr 在做索引的时候,每个1000(1秒)毫秒,做一次文档提交。为了方便测试也可以在Document中立即提交,< /doc>后添加< commit />。
3.4.7.4 Query(重点)
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。

3.5 多solrcore的配置
配置多solrcore的好处:
1、 在进行solrcloud的时候,必须配置多solrcore
2、 每个solrcore之间是独立的,都可以单独对外提供服务。不同的业务模块可以使用不同的solrcore来提供搜索和索引服务。
添加
第一步:复制solrhome下的collection1目录到本目录下,修改名称为collection2

第二步:修改solrcore目录下的core.properties

这样多solrcore就配置完成了。
4 Solr的基本使用
4.1 Schema.xml
在schema.xml文件中,主要配置了solrcore的一些数据信息,包括Field和FieldType的定义等信息,在solr中,Field和FieldType都需要先定义后使用。
4.1.1 Filed
定义Field域
"id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> Name:指定域的名称
Type:指定域的类型
Indexed:是否索引
Stored:是否存储
Required:是否必须
multiValued:是否多值,比如商品信息中,一个商品有多张图片,一个Field像存储多个值的话,必须将multiValued设置为true。
4.1.2 dynamicField
动态域
"*_i" type="int" indexed="true" stored="true"/> Name:指定动态域的命名规则
4.1.3 uniqueKey
指定唯一键
<uniqueKey>iduniqueKey>其中的id是在Field标签中已经定义好的域名,而且该域要设置为required为true。
一个schema.xml文件中必须有且仅有一个唯一键
4.1.4 copyField
复制域
source="cat" dest="text"/> Source: 要复制的源域的域名
Dest: 目标域的域名
由dest指的的目标域,必须设置multiValued为true。

4.1.5 FieldType
定义域的类型
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.LowerCaseFilterFactory"/>
analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
analyzer>
fieldType>Name: 指定域类型的名称
Class: 指定该域类型对应的solr的类型
Analyzer: 指定分析器
Type: index、query,分别指定搜索和索引时的分析器
Tokenizer: 指定分词器
Filter: 指定过滤器
4.2 中文分词器
使用ikanalyzer进行中文分词
第一步:将ikanalyzer的jar包拷贝到以下目录

第二步:将ikanalyzer的扩展词库的配置文件拷贝到 目录

第三步:配置FieldType

第四步:配置使用中文分词的Field

第五步:重启tomcat

4.3 配置业务Field
4.3.1 需求
对京东案例中的products表的数据进行索引,所以需要先定义对应的Field域。
4.3.2 分析配置
Products的表结构

需要往索引库添加的字段有:
pid、name、catalog、catalog_name、price、description、picture
FieldType:
经分析,由于中文分词器已经配置完FieldType,所以目前FieldType已经满足需要,无需配置。
Field:
Pid:
由于pid在products表中是唯一键,而且在solr的shema.xml中已有一个id的唯一键配置,所以不需要再重新定义pid域。
Name:
"product_name" type="text_ik" indexed="true" stored="true"/> Catalog、catalog_name:
<field name="product_catalog" type="string" indexed="true" stored="true"/>
<field name="product_catalog_name" type="string" indexed="true" stored="false"/>
Price:
<field name="product_price" type="float" indexed="true" stored="true"/>
Description:
<field name="product_description" type="text_ik" indexed="true" stored="false"/>
Picture:
<field name="product_picture" type="string" indexed="false" stored="true"/>

4.4 Dataimport
该插件可以将数据库中指定的sql语句的结果导入到solr索引库中。
4.4.1 第一步:添加jar包
Dataimport的jar包
复制以下目录的jar包

添加到以下目录

修改solrconfig.xml文件,添加lib标签
"${solr.install.dir:../..}/contrib/dataimporthandler/lib" regex=".*\.jar" /> MySQL数据库驱动包
将mysql的驱动包,复制到以下目录

修改solrconfig.xml文件,添加lib标签
"${solr.install.dir:../..}/contrib/db/lib" regex=".*\.jar" /> 4.4.2 第二步:配置requestHandler
在solrconfig.xml中,添加一个dataimport的requestHandler

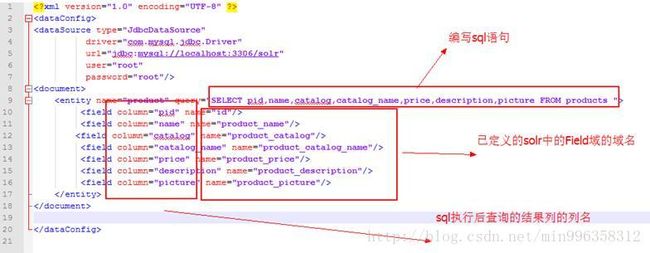
4.4.3 第三步:创建data-config.xml
在solrconfig.xml同级目录下,创建data-config.xml
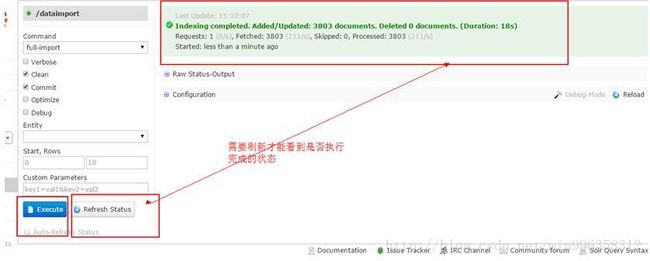
4.4.4 重启tomcat
5 Solrj的使用
5.1 什么是solrj
Solrj就是solr服务器的java客户端。

5.2 环境准备
- Jdk
- Ide
- Tomcat
- Solrj
5.3 搭建工程
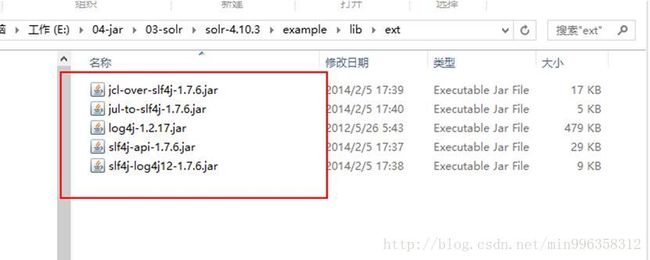
Solrj的依赖包和核心包

Solr的扩展服务包

5.4 使用solrj完成索引维护
5.4.1 添加/修改索引
在solr中,索引库中都会存在一个唯一键,如果一个Document的id存在,则执行修改操作,如果不存在,则执行添加操作。

5.4.2 删除索引
5.4.2.1 根据指定ID来删除

5.4.2.2 根据条件删除
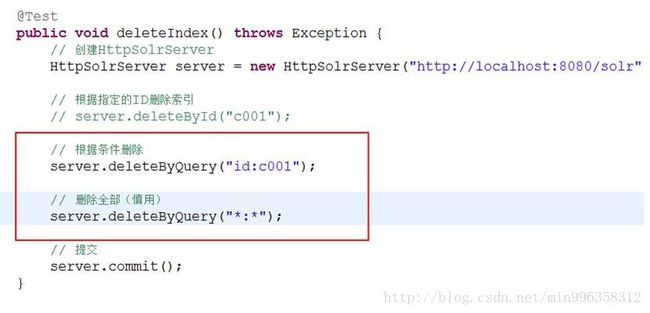
5.4.3 查询索引
5.4.3.1 简单查询

5.4.3.2 复杂查询
5.4.3.2.1 solr的查询语法
(1). q - 查询关键字,必须的,如果查询所有使用:。
请求的q是字符串

(2). fq - (filter query)过虑查询,作用:在q查询符合结果中同时是fq查询符合的,例如::
请求fq是一个数组(多个值)

过滤查询价格从1到20的记录。
也可以在“q”查询条件中使用product_price:[1 TO 20],如下:

也可以使用“*”表示无限,例如:
20以上:product_price:[20 TO *]
20以下:product_price:[* TO 20]
(3). sort - 排序,格式:sort=
示例:  按价格降序
按价格降序
(4). start - 分页显示使用,开始记录下标,从0开始
(5). rows - 指定返回结果最多有多少条记录,配合start来实现分页。
实际开发时,知道当前页码和每页显示的个数最后求出开始下标。
(6). fl - 指定返回那些字段内容,用逗号或空格分隔多个。

显示商品图片、商品名称、商品价格
(7). df - 指定一个搜索Field

也可以在SolrCore目录 中conf/solrconfig.xml文件中指定默认搜索Field,指定后就可以直接在“q”查询条件中输入关键字。
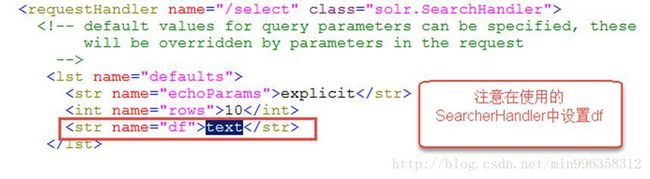
(8). wt - (writer type)指定输出格式,可以有 xml, json, php, phps, 后面 solr 1.3增加的,要用通知我们,因为默认没有打开。
(9). hl - 是否高亮 ,设置高亮Field,设置格式前缀和后缀。

5.4.3.2.2 代码
@Test
public void search02() throws Exception {
// 创建HttpSolrServer
HttpSolrServer server = new HttpSolrServer("http://localhost:8080/solr");
// 创建SolrQuery对象
SolrQuery query = new SolrQuery();
// 输入查询条件
query.setQuery("product_name:小黄人");
// query.set("q", "product_name:小黄人");
// 设置过滤条件
// 如果设置多个过滤条件的话,需要使用query.addFilterQuery(fq)
query.setFilterQueries("product_price:[1 TO 10]");
// 设置排序
query.setSort("product_price", ORDER.asc);
// 设置分页信息(使用默认的)
query.setStart(0);
query.setRows(10);
// 设置显示的Field的域集合
query.setFields("id,product_name,product_catalog,product_price,product_picture");
// 设置默认域
query.set("df", "product_keywords");
// 设置高亮信息
query.setHighlight(true);
query.addHighlightField("product_name");
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");
// 执行查询并返回结果
QueryResponse response = server.query(query);
// 获取匹配的所有结果
SolrDocumentList list = response.getResults();
// 匹配结果总数
long count = list.getNumFound();
System.out.println("匹配结果总数:" + count);
// 获取高亮显示信息
Map>> highlighting = response.getHighlighting();
for (SolrDocument doc : list) {
System.out.println(doc.get("id"));
List list2 = highlighting.get(doc.get("id")).get(
"product_name");
if (list2 != null)
System.out.println("高亮显示的商品名称:" + list2.get(0));
else {
System.out.println(doc.get("product_name"));
}
System.out.println(doc.get("product_catalog"));
System.out.println(doc.get("product_price"));
System.out.println(doc.get("product_picture"));
System.out.println("=====================");
}
} 6 京东案例
6.1 需求
使用Solr实现电商网站中商品信息搜索功能,可以根据关键字、分类、价格搜索商品信息,也可以根据价格进行排序,同时还可以分页。
界面如下:
6.2 分析
6.2.1 UI分析
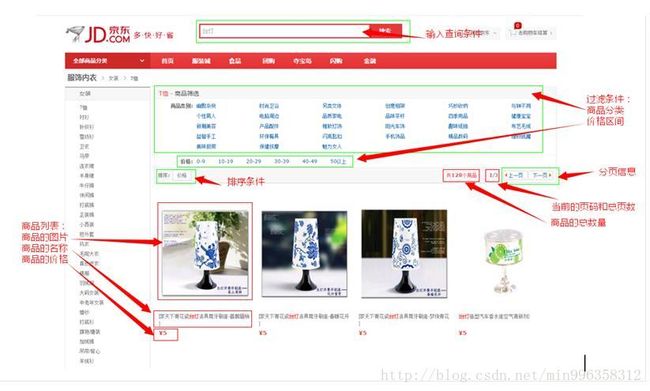
6.2.2 架构分析
应用服务器服务端:
表现层:使用springmvc接收前台搜索页面的查询条件等信息
业务层:调用dao层完成数据库持久化
如果数据库数据发生变化,调用solrj的客户端同步索引库。
Dao层:使用mybatis完成数据库持久化
Solrj服务器:
提供搜索和索引服务
数据库服务器:
提供数据库服务
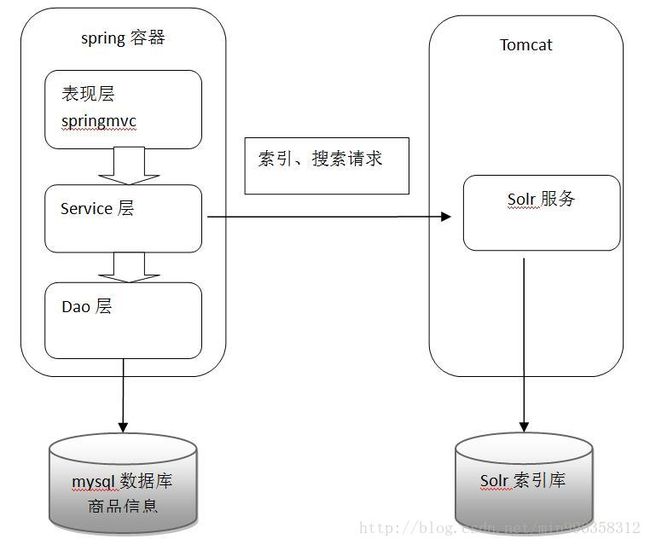
6.3 工程搭建
- Solrj的jar包
- Solr的扩展包
- Springmvc的包
6.4 代码实现
6.4.1 Pojo

6.4.2 Service
Service接口

Service实现类
@Service
public class ProductServiceImpl implements ProductService {
// 依赖注入HttpSolrServer
@Autowired
private HttpSolrServer server;
@Override
public ResultModel getProducts(String queryString, String catalogName,
String price, String sort, Integer page) throws Exception {
// 创建SolrQuery对象
SolrQuery query = new SolrQuery();
// 输入关键字
if (StringUtils.isNotEmpty(queryString)) {
query.setQuery(queryString);
} else {
query.setQuery("*:*");
}
// 输入商品分类过滤条件
if (StringUtils.isNotEmpty(catalogName)) {
query.addFilterQuery("product_catalog_name:" + catalogName);
}
// 输入价格区间过滤条件
// price的值:0-9 10-19
if (StringUtils.isNotEmpty(price)) {
String[] ss = price.split("-");
if (ss.length == 2) {
query.addFilterQuery("product_price:[" + ss[0] + " TO " + ss[1]
+ "]");
}
}
// 设置排序
if ("1".equals(sort)) {
query.setSort("product_price", ORDER.desc);
} else {
query.setSort("product_price", ORDER.asc);
}
// 设置分页信息
if (page == null)
page = 1;
query.setStart((page - 1) * 20);
query.setRows(20);
// 设置默认域
query.set("df", "product_keywords");
// 设置高亮信息
query.setHighlight(true);
query.addHighlightField("product_name");
query.setHighlightSimplePre("");
query.setHighlightSimplePost("");
QueryResponse response = server.query(query);
// 查询出的结果
SolrDocumentList results = response.getResults();
// 记录总数
long count = results.getNumFound();
List products = new ArrayList<>();
Products prod;
// 获取高亮信息
Map>> highlighting = response
.getHighlighting();
for (SolrDocument doc : results) {
prod = new Products();
// 商品ID
prod.setPid(doc.get("id").toString());
List list = highlighting.get(doc.get("id")).get(
"product_name");
// 商品名称
if (list != null)
prod.setName(list.get(0));
else {
prod.setName(doc.get("product_name").toString());
}
// 商品价格
prod.setPrice(Float.parseFloat(doc.get("product_price").toString()));
// 商品图片地址
prod.setPicture(doc.get("product_picture").toString());
products.add(prod);
}
// 封装ResultModel对象
ResultModel rm = new ResultModel();
rm.setProductList(products);
rm.setCurPage(page);
rm.setRecordCount(count);
int pageCount = (int) (count / 20);
if (count % 20 > 0)
pageCount++;
// 设置总页数
rm.setPageCount(pageCount);
return rm;
}
} 6.4.3 Controller
6.4.3.1 代码
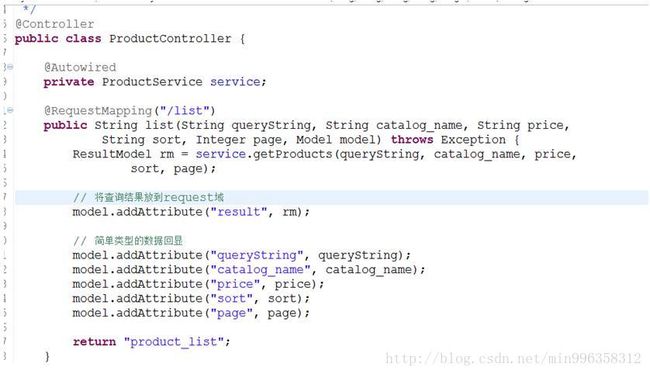
6.4.3.2 Jsp和静态资源
从资料中拷贝


图片信息放到以下目录
6.4.3.3 Web.xml
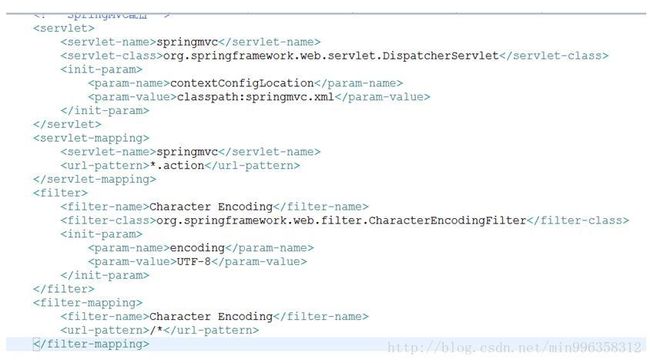
6.4.3.4 配置springmvc.xml

(欧了)