违背基本假设的几种情况——异方差性(R语言)
在建立实际问题的回归模型时,经常存在于此假设想违背的情况,一种是计量经济模型中常说的异方差性,即
v a r ( ε i ) ≠ v a r ( ε j ) , 当 i ≠ j 时 var(\varepsilon _{i})\neq var(\varepsilon _{j}),当i\neq j时 var(εi)̸=var(εj),当i̸=j时
诊断方法
1.残差图分析法
data4.3<-read.csv("C:/Users/Administrator/Desktop/data4.3.csv",head=TRUE)
lm4.3<-lm(y~x,data=data4.3)
summary(lm4.3)
e<-resid(lm4.3) # 计算残差
attach(data4.3)
plot(x,e,ylim=c(-500,500))
abline(h=c(0),lty=5) # 添加虚线e=0
detach(data4.3)
输出结果为:

从残差图看出,误差项具有明显的异方差性,误差随着 x x x的增加呈现出增加态势。
2.等级相关系数法
等级相关系数法又称为斯皮尔曼(Spearman)检验,是一种应用较广泛的方法。进行等级相关系数检验通常有三个步骤:
1.做 y y y关于 x x x的普通最小二乘回归,求出 e i e_{i} ei的值;
2.取 e i e_{i} ei的绝对值,分别把 ∣ e i ∣ \left | e_{i} \right | ∣ei∣和 x i x_{i} xi按递增或者递减的次序排列后分成等级。按照下面公式计算出等级相关系数
r s = 1 − 6 n ( n 2 − 1 ) ∑ i = 1 n d i 2 r_{s}=1-\frac{6}{n(n^{2}-1)}\sum_{i=1}^{n}d_{i}^{2} rs=1−n(n2−1)6∑i=1ndi2
式中, d i d_{i} di为对应于 x i x_{i} xi和 ∣ e i ∣ \left | e_{i} \right | ∣ei∣的等级的差数。
3.做等级相关系数的显著性检验。在 n > 8 n>8 n>8的情况下,用下面公式对样本等级相关系数 r s r_{s} rs进行 t t t检验。检验的统计量为
t = n − 2 r s 1 − r s 2 t=\frac{\sqrt{n-2}r_{s}}{\sqrt{1-r_{s}^{2}}} t=1−rs2n−2rs
如果 ∣ t ∣ ≤ t α / 2 ( n − 2 ) \left | t \right |\leq t_{\alpha /2}(n-2) ∣t∣≤tα/2(n−2),可以认为异方差性问题不存在;反之则存在问题。
代码实现如下:
abse<-abs(e)
cor.test(data4.3$x,abse,alternative="two.sided",method="spearman",conf.level=0.95)
输出结果如下:
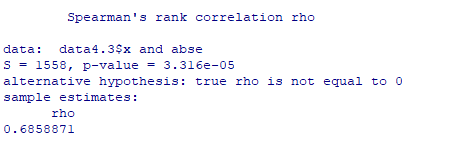
从以上结果中看到,等级相关系数 r s = 0.6858871 r_{s}=0.6858871 rs=0.6858871, P P P值为 3.316 e − 5 3.316e-5 3.316e−5,认为残差绝对值与自变量显著相关,存在异方差。
消除异方差的方法
1.一元加权最小二乘估计
加权最小二乘法(Weighted Least Square,WLS)是一种常用的消除异方差性的方法。
对于一元线性回归方程来说,普通最小二乘法的离差平方和为
Q ( β 0 , β 1 ) = ∑ i = 1 n ( y i − E ( y i ) ) 2 Q(\beta_{0},\beta _{1})=\sum_{i=1}^{n}(y_{i}-E(y_{i}))^{^{2}} Q(β0,β1)=∑i=1n(yi−E(yi))2
其中,每个观测值的权值相同。
在等方差的条件下,平方和总的每一项的地位是相同的。
然而,在异方差的条件下,平方和中的每一项的地位是不同的,误差项方差 σ i 2 \sigma _{i}^{2} σi2大的项,在上式平方和中的作用就偏大,因而普通最小二乘估计的回归线就被拉向方差大的项,而方差小的项的拟合程度就差。加权最小二乘法是在平方和中加入一个适当的权值 w i w_{i} wi以调整各项在平方和中的作用。
一元线性回归的加权最小二乘的离差平方和为
Q w ( β 0 , β 1 ) = ∑ i = 1 n w i ( y i − E ( y i ) ) 2 Q_{w}(\beta_{0},\beta _{1})=\sum_{i=1}^{n}w_{i}(y_{i}-E(y_{i}))^{^{2}} Qw(β0,β1)=∑i=1nwi(yi−E(yi))2
另外,如果所有的权值相等,即 w i w_{i} wi都等于某个常数,该方法就成为普通最小二乘法。
在使用加权最小二乘法时,为了相处异方差的影响,可知观测值的权值应该是观测值误差项方差的倒数,即
w i = 1 σ i 2 w_{i}=\frac{1}{\sigma _{i}^{2}} wi=σi21
在实际问题的研究种,误差项的方差 σ i 2 \sigma _{i}^{2} σi2通常识未知的,但是当武昌项方差随自变量水平以系统的形式变化时,我们可以利用这种关系。
例如,已知误差项方差 σ i 2 \sigma _{i}^{2} σi2与 x i 2 x_{i}^{2} xi2成比例时,那么 σ i 2 = k x i 2 \sigma _{i}^{2}=kx_{i}^{2} σi2=kxi2,其中 k k k为比例系数。
权值就为
w i = 1 k x i 2 w_{i}=\frac{1}{kx_{i}^{2}} wi=kxi21
因为比例系数 k k k在参数估计中可以小区,所以可以直接使用权值
w i = 1 x i 2 w_{i}=\frac{1}{x_{i}^{2}} wi=xi21
在社会、经济研究中,经常会遇到这种特殊的权值,即误差项方差与 x x x的幂函数 x m x^{m} xm成比例,此时权函数为
w i = 1 x i m w_{i}=\frac{1}{x_{i}^{m}} wi=xim1
代码实现如下:
s<-seq(-2,2,0.5)
result1<-vector(length=9,mode="list")
# 生成一个列表向量,以存储下面循环中回归方程估计的似然统计结果
result2<-vector(length=9,mode="list")
# 生成一个列表向量,以存储下面循环中回归方程的估计系数及显著性检验等结果
for(j in 1:9)
{w<-data4.3$x^(-s[j]) # 计算权向量
lm4<-lm(y~x,weights=w,data4.3) # 使用加权最小二乘估计建立回归方程
result1[[j]]<-logLik(lm4)
# 将第j次计算的对数似然统计量保存到result1的第j个元素中
result2[[j]]<-summary(lm4)}
# 将第j次建立的回归方程的结果保存到result2的第j个元素中
输出结果如下:

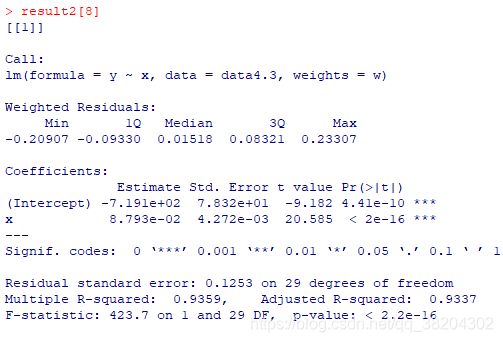
根据上述输出结果可知, m m m取到第8个值即 m = 1.5 m=1.5 m=1.5时对数似然函数达到极大值,因而指数 m m m的最优取值为1.5。
残差图如下所示:
比较普通残差图和加权最小残差图,我们可能看不出两张图之间的差异。但通过残差的比较得知,加权二乘估计照顾小残差项是以牺牲大残差项为代价的。
这里需要注意的是当回归模型存在异方差性时,加权最小二乘估计只是对普通最小二乘估计的改进,这种改进可能是细微的,不能理解为加权最小二乘估计一定会得到与普通最小二乘估计渐染不同的回归方程,或者一定有大幅度的改进。
2.多元加权最小二乘估计
data3.2<-read.csv("C:/Users/Administrator/Desktop/data3.2.csv",head=TRUE)
lm3.2<-lm(y~x1+x2,data=data3.2)
summary(lm3.2)
e<-resid(lm3.2)
abse<-abs(e)
输出结果:


从输出结果中看出,残差绝对值与自变量 x 1 x1 x1的等级相关系数为 r e 1 = 0.45 r_{e1}=0.45 re1=0.45,残差绝对值与自变量 x 2 x2 x2的等级相关系数为 r e 2 = 0.7142857 r_{e2}=0.7142857 re2=0.7142857,因而选择 x 2 x2 x2构造权函数。
s<-seq(1,5,0.5)
result1<-vector(length=9,mode="list")
# 生成一个列表向量,以存储下面循环中回归方程估计的似然统计结果
result2<-vector(length=9,mode="list")
# 生成一个列表向量,以存储下面循环中回归方程的估计系数及显著性检验等结果
for(j in 1:9)
{w<-data3.2$x2^(-s[j]) # 计算权向量
lm4<-lm(y~x1+x2,weights=w,data3.2) # 使用加权最小二乘估计建立回归方程
result1[[j]]<-logLik(lm4)
# 将第j次计算的对数似然统计量保存到result1的第j个元素中
result2[[j]]<-summary(lm4)}
# 将第j次建立的回归方程的结果保存到result2的第j个元素中
输出结果:

可以知道当 m = 2.5 m=2.5 m=2.5时,取得最优值。
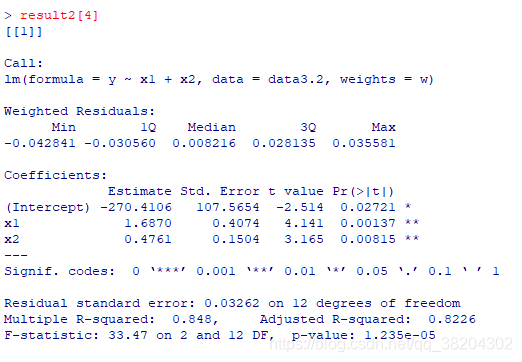
根据以上输出结果,加权最小二乘的 R 2 = 0.848 , F = 33.47 R^{2}=0.848,F=33.47 R2=0.848,F=33.47;而普通最小二乘估计的 R 2 = 0.8419 , F = 31.96 R^{2}=0.8419,F=31.96 R2=0.8419,F=31.96。这说明对该例子中的数据进行加权最小二乘估计的拟合效果好于普通最小二乘估计的效果。