搭建 Hadoop 集群详细教程
1. 准备工作
1.1 环境
- Centos 7
- JDK 1.8
- Hadoop 2.10.0
1.2 集群部署规划
| hadoop1 | hadoop2 | hadoop3 | |
|---|---|---|---|
| HDFS | NameNode, DataNode | DataNode | SecondaryNameNode, DataNode |
| Yarn | NodeManager | ResourceManager, NodeManager | NodeManager |
2. 配置主节点
2.1 创建虚拟机
- 选择新建虚拟机
- 选择典型类型
- 选择稍后安装操作系统
- 选择 Linux,Centos 7 64位
- 命名虚拟机 hadoop1
- 使用默认 20G 磁盘大小
- 不修改虚拟机硬件配置,完成创建虚拟机
- 选择创建好的虚拟机,点击编辑虚拟机
- 移除 USB 控制器、声卡、打印机
- 选择 CD/DVD,使用 ISO 映像文件,选择 ISO 文件位置
- 开启并安装虚拟机
- 时区选 Asia Shanghai
- 需创建 root 用户
2.2 配置
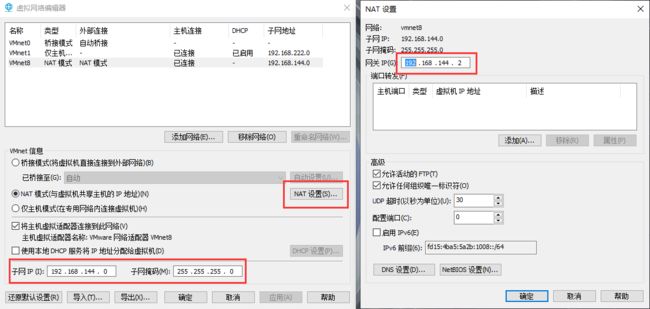
- 「编辑」->「虚拟网络编辑器」->「VMnet8」->「设置 NAT」,如下图
-
虚拟机网络配置选择 NAT 模式
-
配置静态 ip
切换到 root 用户
su root
编辑配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens32
也有可能是 eth0、ens33 等,跟 Centos 版本有关
配置文件内容如下,其中需要修改 BOOTPROTO 字段值为 static;ONBOOT 字段值为 yes,表示开机启动网络;IPADDR 字段为 ip 地址,需与 NAT 子网 ip 在同一网段;GATEWAY 字段为网关,需与 NAT 网关相同
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens32
UUID=4d0b744b-8ebf-4c75-b35c-324d9f671ce6
DEVICE=ens32
ONBOOT=yes
IPADDR=192.168.144.101
GATEWAY=192.168.144.2
DNS1=8.8.8.8
DNS2=8.8.4.4
重启网络
systemctl restart network
查看 ip
ip addr
- 关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service
systemctl status firewalld
- 修改 hostname
echo hadoop1 > /etc/hostname
编辑文件
vi /etc/sysconfig/network
写入以下内容
NETWORKING=yes # 使用网络
HOSTNAME=hadoop1 # 设置主机名
- 配置 Host
vi /etc/hosts
追加以下内容
192.168.144.101 hadoop1
192.168.144.102 hadoop2
192.168.144.103 hadoop3
- 重启
reboot
- 切换回普通用户
su shenke
创建安装目录
sudo mkdir /opt/module
修改安装目录所有者
sudo chown shenke:shenke /opt/module
2.3 安装 JDK
- 将在
/tmp目录下的jdk-8u261-linux-x64.tar.gz解压
tar -zxvf jdk-8u261-linux-x64.tar.gz
- 移动到
/opt/module目录下,并重命名为jdk
mv jdk1.8.0_261 /opt/module/jdk
- 配置环境变量
sudo vi /etc/profile
追加以下内容
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效
source /etc/profile
- 验证是否安装成功
java -version
2.4 安装 Hadoop
- 将在
/tmp目录下的hadoop-2.10.0.tar.gz解压
tar -zxvf hadoop-2.10.0.tar.gz
- 移动到
/opt/module目录下,并重命名为hadoop
mv hadoop-2.10.0 /opt/module/hadoop
- 配置环境变量
sudo vi /etc/profile
追加以下内容
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
使环境变量生效
source /etc/profile
- 验证是否安装成功
hadoop
2.5 安装其他包
sudo yum install -y net-tools rsync
3. 配置从节点
3.1 克隆虚拟机
先将 hadoop1 关机,「右键」->「管理」->「克隆」
-
选择创建完整克隆
-
修改虚拟机名称为 hadoop2
3.2 配置网络
如 2.2 中第 3 步,修改 /etc/sysconfig/network-scripts/ifcfg-ens32 文件中的 IPADDR 为 192.168.144.102,并删除 UUID
如 2.2 中第 5 步,修改 hostname 为 hadoop2
重复以上步骤,克隆一个 hadoop3 节点
3.3 测试
尝试能否 ping 通其他节点
ping hadoop2
4. 配置集群
4.1 设置 SSH 无密码登录
- 生成公钥
ssh-keygen -t rsa
- 分发公钥
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
在三个节点上重复以上命令
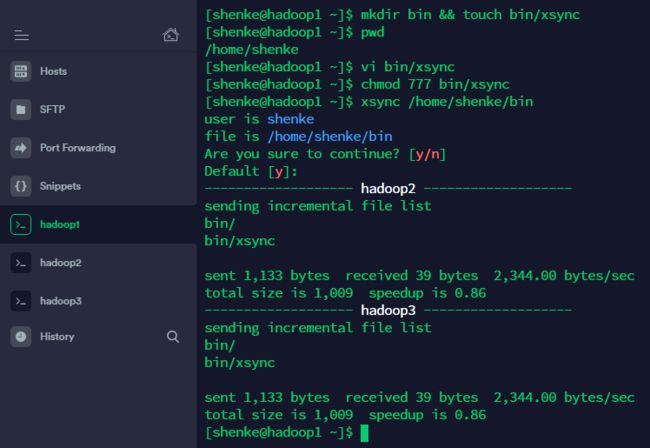
4.2 编写集群分发脚本 xsync
- 在 hadoop1 的
/home/user/bin目录下创建xsync文件
mkdir bin && touch bin/xsync
如果是 root 用户则可将脚本放在
/usr/local/bin目录下
编辑脚本
vi bin/xsync
内容参考 xsync.sh,主要是通过以下命令实现文件同步,其中,-r 表示递归处理子目录,-v 表示以详细模式输出,-l 表示保留软链接,--delete 表示同步删除,--ignore-errors 表示即使出现 IO 错误也进行删除
rsync -rvl --delete --ignore-errors $directory/$file $user@$host:$directory
- 赋予执行权限
chmod 777 bin/xsync
- 使用
xsync $file
# 例如
xsync /home/shenke/bin
5. 配置集群
配置文件均在 hadoop 安装目录下的 etc/hadoop 目录下
5.1 核心配置文件
- 编辑
core-site.xml
vi core-site.xml
在 configuration 标签中写入以下内容
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/module/hadoop/data/tmpvalue>
property>
configuration>
- 创建存储目录
mkdir -p /opt/module/hadoop/data/tmp
5.2 HDFS 配置文件
- 配置
hadoop-env.sh
vi hadoop-env.sh
在文件末尾追加以下内容
export JAVA_HOME=/opt/module/jdk
- 配置
hdfs-site.xml
vi hdfs-site.xml
在 configuration 标签中写入以下内容
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop3:50090value>
property>
configuration>
5.3 Yarn 配置文件
- 配置
yarn-env.sh
vi yarn-env.sh
在文件末尾追加以下内容
export JAVA_HOME=/opt/module/jdk
- 配置
yarn-site.xml
vi yarn-site.xml
在 configuration 标签中写入以下内容
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop2value>
property>
configuration>
5.4 MapReduce 配置文件
- 配置
mapred-env.sh
vi mapred-env.sh
在文件末尾追加以下内容
export JAVA_HOME=/opt/module/jdk
- 配置
mapred-site.xml
cp mapred-site.xml.template mapred-site.xml && vi mapred-site.xml
在 configuration 标签中写入以下内容
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
5.5 配置 slaves
编辑 slaves
vi slaves
写入以下内容
hadoop1
hadoop2
hadoop3
5.6 同步配置文件
xsync /opt/module/hadoop
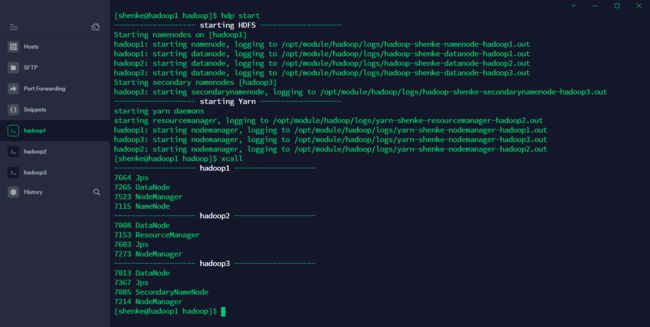
6. 启动集群
在 hadoop 安装目录下
- 格式化
bin/hdfs namenode -format
如果需要重新格式化 NameNode,需要先将
data/tmp和logs下的文件全部删除
- 启动 HDFS
sbin/start-dfs.sh
- 启动 Yarn
sbin/start-yarn.sh
注意:需在 ResouceManager 所在节点启动 Yarn,本例中在 hadoop2 中启动
- 查看进程
jps
- 查看 web 端
- NameNode: hadoop1:50070
- SecondaryNameNode: hadoop3:50090
- 停止 HDFS
sbin/stop-dfs.sh
- 停止 Yarn
sbin/stop-yarn.sh
7. 编写群起脚本
- 启动和关闭脚本
同样是在 /home/shenke/bin 目录下,新建并编辑脚本
vi ~/bin/hdp
内容参考 hadoop.sh
- 查看进程脚本
新建并编辑脚本
vi ~/bin/xcall
内容参考 xcall.sh
8. HDFS 测试
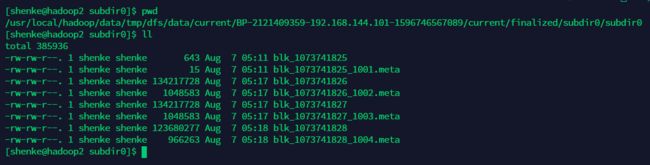
- 上传文件
上传一个小文件到根目录
bin/hdfs dfs -put /home/shenke/bin/xsync /
上传一个大文件到根目录
bin/hdfs dfs -put /tmp/hadoop-2.10.0.tar.gz /

- 查看文件存储路径