Pytorch迁移学习小技巧 以及 Pytorch小技巧的一些总结
迁移学习技巧
内容概要:
- 迁移学习的概念
- Pytorch预训练模型以及修改
- 不同修改预训练模型方式的情况
- 一些例子:只针对dense layer的重新训练 ,冻结初始层的权重重新训练
迁移学习的概念
神经网络需要用数据来训练,它从数据中获得信息,进而把它们转换成相应的权重。这些权重能够被提取出来,迁移到其他的神经网络中,我们“迁移”了这些学来的特征,就不需要从零开始训练一个神经网络了 。
Pytorch预训练模型以及修改
卷积神经网络的训练是耗时的,很多场合不可能每次都从随机初始化参数开始训练网络。
pytorch中自带几种常用的深度学习网络预训练模型,如VGG、ResNet等。往往为了加快学习的进度,在训练的初期我们直接加载pre-train模型中预先训练好的参数,model的加载如下所示:
import torchvision.models as models
#resnet
model = models.ResNet(pretrained=True)
model = models.resnet18(pretrained=True)
model = models.resnet34(pretrained=True)
model = models.resnet50(pretrained=True)
#vgg
model = models.VGG(pretrained=True)
model = models.vgg11(pretrained=True)
model = models.vgg16(pretrained=True)
model = models.vgg16_bn(pretrained=True) 预训练模型的修改(具体何种情况下需要用到哪种修改方式,我们后面说)
1. 参数修改
对于简单的参数修改,这里以resnet预训练模型举例,resnet源代码在Github。 resnet网络最后一层分类层fc是对1000种类型进行划分,对于自己的数据集,如果只有9类,修改的代码如下:
# coding=UTF-8
import torchvision.models as models
#调用模型
model = models.resnet50(pretrained=True)
#提取fc层中固定的参数
fc_features = model.fc.in_features
#修改类别为9
model.fc = nn.Linear(fc_features, 9) 2. 增减卷积层
前一种方法只适用于简单的参数修改,有的时候我们往往要修改网络中的层次结构,这时只能用参数覆盖的方法,即自己先定义一个类似的网络,再将预训练中的参数提取到自己的网络中来。这里以resnet预训练模型举例。
# coding=UTF-8
import torchvision.models as models
import torch
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
class CNN(nn.Module):
def __init__(self, block, layers, num_classes=9):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
#新增一个反卷积层
self.convtranspose1 = nn.ConvTranspose2d(2048, 2048, kernel_size=3, stride=1, padding=1, output_padding=0, groups=1, bias=False, dilation=1)
#新增一个最大池化层
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
#去掉原来的fc层,新增一个fclass层
self.fclass = nn.Linear(2048, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
#新加层的forward
x = x.view(x.size(0), -1)
x = self.convtranspose1(x)
x = self.maxpool2(x)
x = x.view(x.size(0), -1)
x = self.fclass(x)
return x
#加载model
resnet50 = models.resnet50(pretrained=True)
cnn = CNN(Bottleneck, [3, 4, 6, 3])
#读取参数
pretrained_dict = resnet50.state_dict()
model_dict = cnn.state_dict()
# 将pretrained_dict里不属于model_dict的键剔除掉
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
# 更新现有的model_dict
model_dict.update(pretrained_dict)
# 加载我们真正需要的state_dict
cnn.load_state_dict(model_dict)
# print(resnet50)
print(cnn) 不同修改预训练模型方式的情况
1. 特征提取
我们可以将预训练模型当做特征提取装置来使用。具体的做法是,将输出层去掉,然后将剩下的整个网络当做一个固定的特征提取机,从而应用到新的数据集中。
2. 采用预训练模型的结构
我们还可以采用预训练模型的结构,但先将所有的权重随机化,然后依据自己的数据集进行训练。
3. 训练特定层,冻结其它层
另一种使用预训练模型的方法是对它进行部分的训练。具体的做法是,将模型起始的一些层的权重保持不变,重新训练后面的层,得到新的权重。在这个过程中,我们可以多次进行尝试,从而能够依据结果找到frozen layers和retrain layers之间的最佳搭配。
如何使用与训练模型,是由数据集大小和新旧数据集(预训练的数据集和我们要解决的数据集)之间数据的相似度来决定的。
下图表展示了在各种情况下应该如何使用预训练模型:
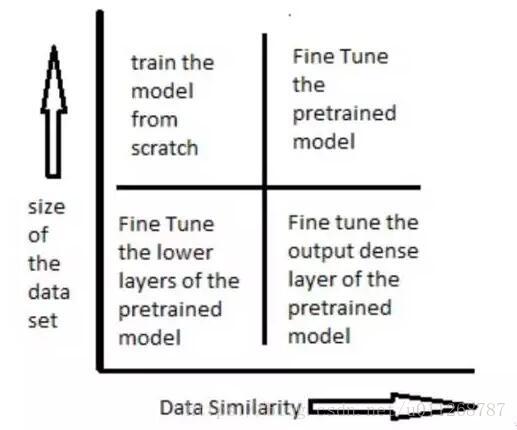
一些例子
这个例子也是我从量子位上面看来的,感觉很有借鉴意义。他这个原先是我曾经使用vgg16作为预训练的模型结构,并把它应用到手写数字识别上。尝试了两种方法。
1. 只重新训练输出层 & dense layer
这里我们采用vgg16作为特征提取器。随后这些特征,会被传递到依据我们数据集训练的dense layer上(这里需要注意的是dense layer其实就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加)。输出层同样由与我们问题相对应的softmax层函数所取代。
在vgg16中,输出层是一个拥有1000个类别的softmax层。我们把这层去掉,换上一层只有10个类别的softmax层。我们只训练这些层,然后就进行数字识别的尝试。
# importing required librariesfrom keras.models import Sequentialfrom scipy.misc import imread
get_ipython().magic('matplotlib inline')import matplotlib.pyplot as pltimport numpy as npimport kerasfrom keras.layers import Denseimport pandas as pdfrom keras.applications.vgg16 import VGG16from keras.preprocessing import imagefrom keras.applications.vgg16 import preprocess_inputimport numpy as npfrom keras.applications.vgg16 import decode_predictions
train=pd.read_csv("R/Data/Train/train.csv")
test=pd.read_csv("R/Data/test.csv")
train_path="R/Data/Train/Images/train/"test_path="R/Data/Train/Images/test/"from scipy.misc import imresize# preparing the train datasettrain_img=[]for i in range(len(train)):
temp_img=image.load_img(train_path+train['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
train_img.append(temp_img)#converting train images to array and applying mean subtraction processingtrain_img=np.array(train_img)
train_img=preprocess_input(train_img)# applying the same procedure with the test datasettest_img=[]for i in range(len(test)):
temp_img=image.load_img(test_path+test['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
test_img.append(temp_img)
test_img=np.array(test_img)
test_img=preprocess_input(test_img)# loading VGG16 model weightsmodel = VGG16(weights='imagenet', include_top=False)# Extracting features from the train dataset using the VGG16 pre-trained modelfeatures_train=model.predict(train_img)# Extracting features from the train dataset using the VGG16 pre-trained modelfeatures_test=model.predict(test_img)# flattening the layers to conform to MLP inputtrain_x=features_train.reshape(49000,25088)# converting target variable to arraytrain_y=np.asarray(train['label'])# performing one-hot encoding for the target variabletrain_y=pd.get_dummies(train_y)
train_y=np.array(train_y)# creating training and validation setfrom sklearn.model_selection import train_test_split
X_train, X_valid, Y_train, Y_valid=train_test_split(train_x,train_y,test_size=0.3, random_state=42)# creating a mlp modelfrom keras.layers import Dense, Activation
model=Sequential()
model.add(Dense(1000, input_dim=25088, activation='relu',kernel_initializer='uniform'))
keras.layers.core.Dropout(0.3, noise_shape=None, seed=None)
model.add(Dense(500,input_dim=1000,activation='sigmoid'))
keras.layers.core.Dropout(0.4, noise_shape=None, seed=None)
model.add(Dense(150,input_dim=500,activation='sigmoid'))
keras.layers.core.Dropout(0.2, noise_shape=None, seed=None)
model.add(Dense(units=10))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['accuracy'])# fitting the model model.fit(X_train, Y_train, epochs=20, batch_size=128,validation_data=(X_valid,Y_valid))2. 冻结最初的几层网络权重
还有一种方案是这里我们将会把vgg16网络的前8层进行冻结,然后对后面的网络重新进行训练。这么做是因为最初的几层网络捕获的是曲线、边缘这种普遍的特征,这跟我们的问题是相关的。我们想要保证这些权重不变,让网络在学习过程中重点关注这个数据集特有的一些特征,从而对后面的网络进行调整。
from keras.models import Sequentialfrom scipy.misc import imread
get_ipython().magic('matplotlib inline')import matplotlib.pyplot as pltimport numpy as npimport kerasfrom keras.layers import Denseimport pandas as pdfrom keras.applications.vgg16 import VGG16from keras.preprocessing import imagefrom keras.applications.vgg16 import preprocess_inputimport numpy as npfrom keras.applications.vgg16 import decode_predictionsfrom keras.utils.np_utils import to_categoricalfrom sklearn.preprocessing import LabelEncoderfrom keras.models import Sequentialfrom keras.optimizers import SGDfrom keras.layers import Input, Dense, Convolution2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D, Dropout, Flatten, merge, Reshape, Activationfrom sklearn.metrics import log_loss
train=pd.read_csv("R/Data/Train/train.csv")
test=pd.read_csv("R/Data/test.csv")
train_path="R/Data/Train/Images/train/"test_path="R/Data/Train/Images/test/"from scipy.misc import imresize
train_img=[]for i in range(len(train)):
temp_img=image.load_img(train_path+train['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
train_img.append(temp_img)
train_img=np.array(train_img)
train_img=preprocess_input(train_img)
test_img=[]for i in range(len(test)):
temp_img=image.load_img(test_path+test['filename'][i],target_size=(224,224))
temp_img=image.img_to_array(temp_img)
test_img.append(temp_img)
test_img=np.array(test_img)
test_img=preprocess_input(test_img)from keras.models import Modeldef vgg16_model(img_rows, img_cols, channel=1, num_classes=None):
model = VGG16(weights='imagenet', include_top=True)
model.layers.pop()
model.outputs = [model.layers[-1].output]
model.layers[-1].outbound_nodes = []
x=Dense(num_classes, activation='softmax')(model.output)
model=Model(model.input,x)#To set the first 8 layers to non-trainable (weights will not be updated)
for layer in model.layers[:8]:
layer.trainable = False# Learning rate is changed to 0.001
sgd = SGD(lr=1e-3, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss='categorical_crossentropy', metrics=['accuracy']) return model
train_y=np.asarray(train['label'])
le = LabelEncoder()
train_y = le.fit_transform(train_y)
train_y=to_categorical(train_y)
train_y=np.array(train_y)from sklearn.model_selection import train_test_split
X_train, X_valid, Y_train, Y_valid=train_test_split(train_img,train_y,test_size=0.2, random_state=42)# Example to fine-tune on 3000 samples from Cifar10img_rows, img_cols = 224, 224 # Resolution of inputschannel = 3num_classes = 10 batch_size = 16 nb_epoch = 10# Load our modelmodel = vgg16_model(img_rows, img_cols, channel, num_classes)
Pytorch技巧
之前采用keras进行深度学习网络的搭建,取得的效果还不错,但是有一些参数没法更改,同时一些参数也没法实时看到。在师兄的指引下,决定采用pytorch进行深度学习模型的搭建。开始的时候也不是很顺,主要还是自主探索新领域的难吧。
内容概要:
- windows环境下pytorch和tensorboard联合使用
- 修改预训练模型
windows环境下pytorch和tensorboard联合使用
参考链接
过程:
- 运行主函数 ,然后产生logs文件
- 切换到board目录下,运行:
tensorboard --logdir=./logs --port=6006 - 在浏览器地址栏中输入
http://localhost:6006/
修改预训练模型
这个比如说Faster-RCNN基于vgg19提取features,但是只使用了一部分模型提取features,所以需要知道如何修改预训练模型,参考链接
步骤:
- 下载vgg19的pth文件,在anaconda中直接设置
pretrained=True下载一般都比较慢,我用的浏览器或者迅雷直接下载,在model_zoo里面有各种预训练模型的下载链接
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',- 下载好的模型,可以用下面这段代码试着看一下,并且改一下模型。在vgg19.pth同级目录建立一个
test.py
import torch
import torch.nn as nn
import torchvision.models as models
vgg16 = models.vgg16(pretrained=False)
vgg16.load_state_dict(torch.load('vgg16-397923af.pth'))
print('vgg16:\n', vgg16)
modified_features = nn.Sequential(*list(vgg16.features.children())[:-1])
# to relu5_3
print('modified_features:\n', modified_features )具体地,模型的保存与加载,Pytorch有两种方式,上面代码是其中一种方式。
torch.save()实现对网络结构和模型参数的保存。有两种保存方式:
一、是保存年整个神经网络的的结构信息和模型参数信息,save的对象是网络net;
二、是只保存神经网络的训练模型参数,save的对象是net.state_dict()。
torch.save(net1, '7-net.pth') # 保存整个神经网络的结构和模型参数
torch.save(net1.state_dict(), '7-net_params.pth') # 只保存神经网络的模型参数 对应上面两种保存方式,重载方式也有两种。
对应第一种完整网络结构信息,重载的时候通过torch.load(‘.pth’)直接初始化新的神经网络对象即可。
对应第二种只保存模型参数信息,需要首先导入对应的网络,通过net.load_state_dict(torch.load('.pth'))完成模型参数的重载。在网络比较大的时候,第一种方法会花费较多的时间。
# 保存和加载整个模型
torch.save(model_object, 'model.pkl')
model = torch.load('model.pkl')
# 仅保存和加载模型参数(推荐使用)
torch.save(model_object.state_dict(), 'params.pkl')
model_object.load_state_dict(torch.load('params.pkl')) - 修改好之后features就可以拿去做Faster-RCNN提取特征用了。
注意 在Linux系统之下,运行速度是Windows下的快两倍。
参考文献:
- pytorch小技巧
- pytorch中的pre-train函数模型引用及修改(增减网络层,修改某层参数等)
- PyTorch中使用预训练的模型初始化网络的一部分参数
- PyTorch预训练
- Pytorch使用总结