基于eclipse的MapReduce并发计算框架
此项目基于Zookeeper集群集群之上
集群
加上Eclipse Hadoop 扩展
使用Eclipse 中MapReduce模块 创建java项目
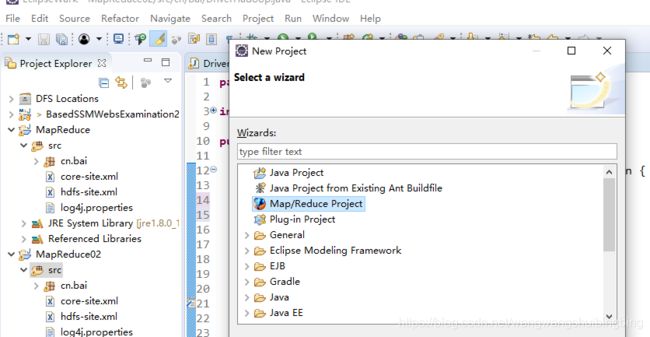 添加配置文件 建包
添加配置文件 建包
(从Master机上导出)
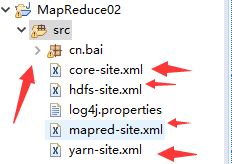
注意配置文件的位置
导出的配置core-site.xml将
hadoop.tmp.dir
files:/usr/hadoop/hadoop-3.1.2/tmp
删除
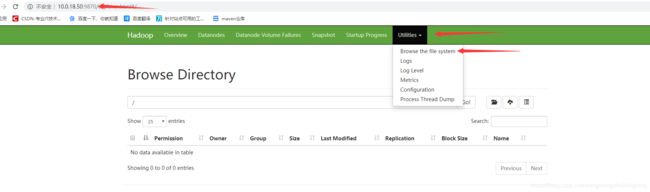
向服务器导入数据
通过web导入(服务器ip:9870)
 在刚刚创建的包中添加Reducer
在刚刚创建的包中添加Reducer
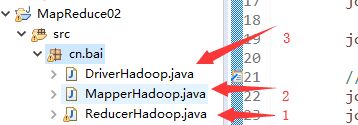
注意文件创建顺序 1与2 可以换 但是 Driver必须是最后一个
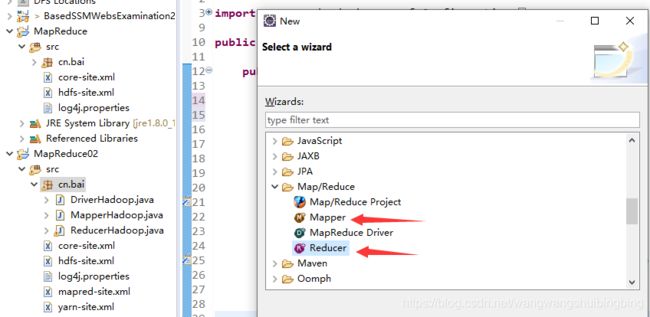
这两个创建注意 位置 一定是在 刚刚创建的包内
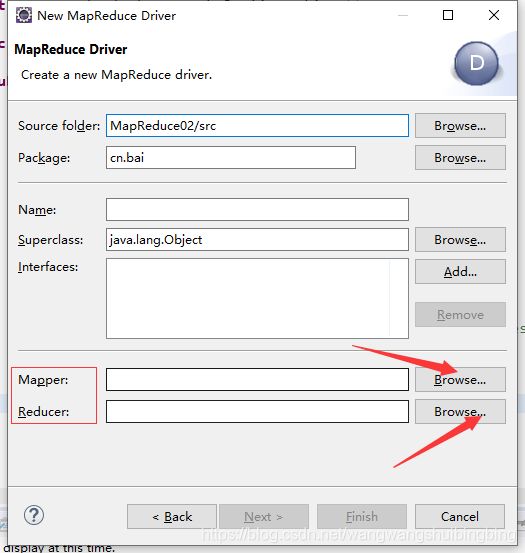
创建Driver 注意选择 Mapper与Reducer 一定是自己刚刚创建的
现在基本完成
代码
Driver
public class Driver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "医疗数据");
//设置启动器
job.setJarByClass(Driver.class);
//设置mapper
job.setMapperClass(cn.bai.Mapper.class);
//指定Reduce处理代码
job.setReducerClass(cn.bai.Reduec.class);
// TODO: specify output types
//设置key value 输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// TODO: specify input and output DIRECTORIES (not files)
//待分析的数据位置 与 分析完成以后的输出目的地
FileInputFormat.setInputPaths(job, new Path("hdfs://anna/data/data02.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://anna/data/bybout"));
if (!job.waitForCompletion(true))
return;
}
}
Driver 在启动的时候就拿到 服务器上的数据(data02.txt ) 将数据发送给Mapper
Mapper
public class Mapper extends org.apache.hadoop.mapreduce.Mapper {
//框架加载数据源 数据块中每一行数据都会调用一次Mapper ikey数据平移量 ivalue
public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException {
String lineString = ivalue.toString();
String[] dataStrings = lineString.split("\t");
if(dataStrings!=null) {
if("Treatment_department".equals(dataStrings[1])){
//无效数据
}else {
//有效数据
// String c1 = dataStrings[1];
// Text text = new Text(c1);
context.write(new Text(dataStrings[1]), new Text("1"));
}
}
}
}
Mapper 根据数据块 进行并发 (分发给worker机 进行计算 ) mapper中的
context.write(new Text(dataStrings[1]), new Text(“1”));
发送是 key value 结构
就是发送给Reducer进行总结
注意:每一条数据都会执行一次Mapper
如果数据量很大 可以把数据分发给多台Worker机 数据处理速度就会很快
将处理完的数据交给Reducer
Reducer
public class Reduec extends Reducer {
public void reduce(Text _key, Iterable values, Context context) throws IOException, InterruptedException {
// process values 每一个key调用一次reduce
Integer cout = 0;
for (Text val : values) {
cout+=Integer.valueOf(val.toString());
}
//
context.write(_key, new Text(cout.toString()));
}
}
处理完成 输出到在
Driver中定义的位置:
FileOutputFormat.setOutputPath(job, new Path(“hdfs://anna/data/bybout”));
提示HDFS访问或写入无权限问题:
1、 客户端提权
2、 服务器降权
a) 直接给hdfs指定目录配置权限列表
i. hdfs dfs -chmod -R 777 hdfs://anna/
b) 直接在hadoop配置文件中,将权限禁用
i.
ii. dfs.permissions.enabled
iii. false
iv.