//先记录一个想法……java实在是太臃肿了,纯面向对象也有不少弊端……
//能不能把java精简一下啊!
先上结论:
Array:认真看api索引的话,Array有两个。一个是sql中的接口,一个是类,我们在这里说的是这个类。
Arrays:对数组的一些列操作。
ArrayList:一个容器。
零/概述
在学Java以前,一说到存放东西,第一个想到的就是使用数组,使用数组,在数据的存取方面的却也挺方便,其存储效率高访问快,但是它也受到了一些限制,比如说数组的长度以及数组的类型,当我需要一组string类型数据的同时还需要Integer类型的话,就需要定义两次,同时,数组长度也受到限制,即使是动态定义数组长度,但是长度依然需要固定在某一个范围内,不方便也不灵活。
如果说我想要消除上面的这个限制和不方便应该怎么办呢?Java是否提供了相应的解决方法。答案是肯定的,这就是Java容器,java容器是javaAPI所提供的一系列类的实例,用于在程序中存放对象,主要位于Java.util包中,其长度不受限制,类型不受限制,你在存放String类的时候依然能够存放Integer类,两者不会冲突。
java类库中为我们定义了很多类。可以划分成 容器类(也称集合类) 工具类//大体我现在就知道这三种分类……我也不知道还有没有其他类型
集合类是来实现集合操作的;工具类是对集合功能的扩展,其中大部分是static函数,一般不必实例化创建对象,而直接调用对集合进行操作。
一/集合类
集合类存放于java.util包中。
集合类存放的都是对象的引用,而非对象本身,出于表达上的便利,我们称集合中的对象就是指集合中对象的引用(reference)。
1.集合框架

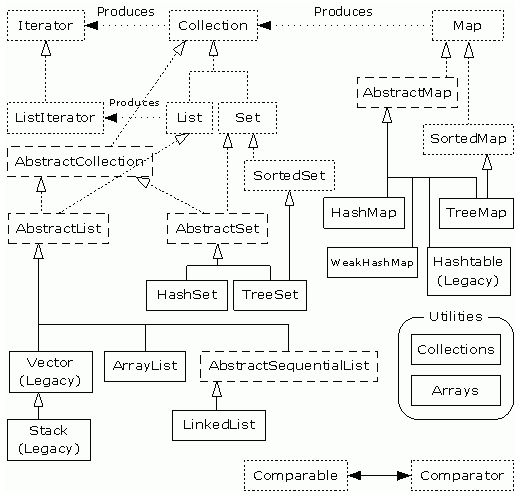
//以上 图一
//以上 图二

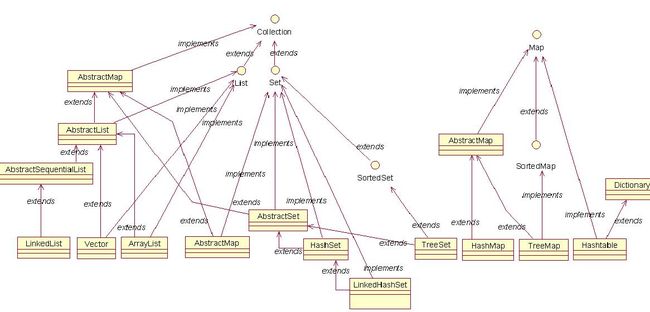
//以上 图三
//以上 图四
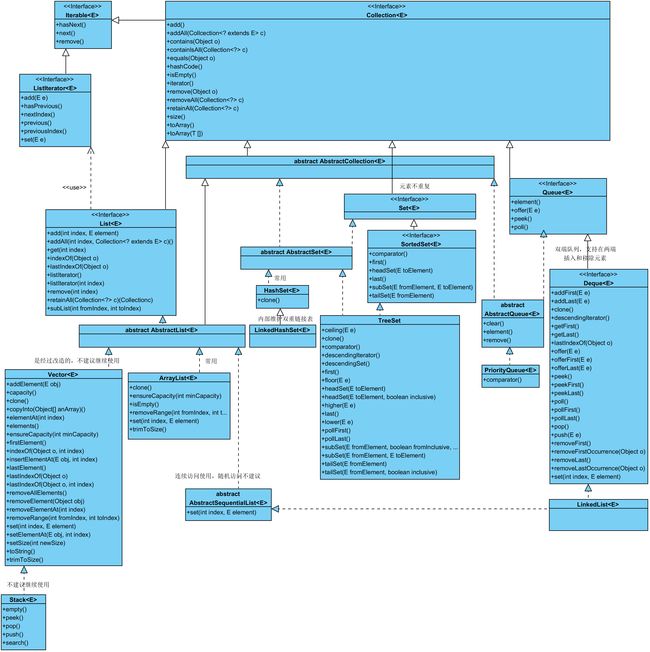
//以上 图五
从图二中可以看出
集合接口:6个接口(短线表示),表示不同集合类型,是集合框架的基础。主要是 list列表 map映射 set集 三大类。
抽象类:5个抽象类(长虚线表示),对集合接口的部分实现。可扩展为自定义集合类。//一般不用,一般直接使用实现类。
实现类:8个实现类(实线表示),对接口的具体实现。ArrayList HashMap 等等
在很大程度上,一旦您理解了接口,您就理解了框架。虽然您总要创建接口特定的实现,但访问实际集合的方法应该限制在接口方法的使用上;因此,允许您更改基本的数据结构而不必改变其它代码。
· Collection 接口是一组允许重复的对象。
· Set 接口继承 Collection,但不允许重复,使用自己内部的一个排列机制。
· List 接口继承 Collection,允许重复,以元素安插的次序来放置元素,不会重新排列。
· Map接口是一组成对的键-值对象,即所持有的是key-value pairs。Map中不能有重复的key。拥有自己的内部排列机制。
· 容器中的元素类型都为Object。从容器取得元素时,必须把它转换成原来的类型。
Collection是List和Set两个接口的基接口
List在Collection之上增加了"有序"
Set在Collection之上增加了"唯一"
而ArrayList是实现List的类...所以他是有序的.它里边存放的元素在排列上存在一定的先后顺序,而且ArrayList是采用数组存放元素。另一种List LinkedList采用的则是链表。
Collection和Map接口之间的主要区别在于:Collection中存储了一组对象,而Map存储关键字/值对。在Map对象中,每一个关键字最多有一个关联的值。
Map:不能包括两个相同的键,一个键最多能绑定一个值。null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示Map中没有该键,也可以表示该键所对应的值为null。因此,在Map中不能由get()方法来判断Map中是否存在某个键,而应该用containsKey()方法来判断。
继承Map的类有:HashMap,HashTable
HashMap:Map的实现类,缺省情况下是非同步的,可以通过Map Collections.synchronizedMap(Map m)来达到线程同步
HashTable:Dictionary的子类,缺省是线程同步的。不允许关键字或值为null
当元素的顺序很重要时选用TreeMap,当元素不必以特定的顺序进行存储时,使用HashMap。Hashtable的使用不被推荐,因为HashMap提供了所有类似的功能,并且速度更快。当你需要在多线程环境下使用时,HashMap也可以转换为同步的
2.数组与容器
数组与其它容器的区别体现在三个方面:效率,类型识别以及可以持有primitives。数组是Java提供的,能随机存储和访问reference序列的诸多方法中的,最高效的一种。数组是一个简单的线性序列,所以它可以快速的访问其中的元素。但是速度是有代价的;当你创建了一个数组之后,它的容量就固定了,而且在其生命周期里不能改变。也许你会提议先创建一个数组,等到快不够用的时候,再创建一个新的,然后将旧的数组里的reference全部导到新的里面。其实(我们以后会讲的)ArrayList就是这么做的。但是这种灵活性所带来的开销,使得ArrayList的效率比起数组有了明显下降。
还有一些泛型容器类包括List,Set和Map。他们处理对象的时候就好像这些对象都没有自己的具体类型一样。也就是说,容器将它所含的元素都看成是(Java中所有类的根类)Object的。这样你只需要建一种容器,就能把所有类型的对象全都放进去。从这个角度来看,这种作法很不错(只是苦了primitive。如果是常量,你还可以用Java的primitive的Wrapper类;如果是变量,那就只能放在你自己的类里了)。与其他泛型容器相比,这里体现数组的第二个优势:创建数组的时候,你也同时指明了它所持有的对象的类型(这又引出了第三点--数组可以持有primitives,而容器却不行)。也就是说,它会在编译的时候作类型检查,从而防止你插入错误类型的对象,或者是在提取对象的时候把对象的类型给搞错了。Java在编译和运行时都能阻止你将一个不恰当的消息传给对象。所有这并不是说使用容器就有什么危险,只是如果编译器能够帮你指定,那么程序运行会更快,最终用户也会较少收到程序运行异常的骚扰。
当你事先不知道要存放数据的个数,或者你需要一种比数组下标存取机制更灵活的方法时,你就需要用到集合类。
3.详细介绍
| 有序否 |
允许元素重复否 |
||
| Collection |
否 |
是 |
|
| List |
是 |
是 |
|
| Set |
AbstractSet |
否 |
否 |
| HashSet |
|||
| TreeSet |
是(用二叉树排序) |
||
| Map |
AbstractMap |
否 |
使用key-value来映射和存储数据,Key必须惟一,value可以重复 |
| HashMap |
|||
| TreeMap |
是(用二叉树排序)
|
||
(1)集 (Set):口袋
集(set)是最简单的一种集合,它的对象不按特定方式排序,只是简单的把对象加入集合中,就像往口袋里放东西。
对集中成员的访问和操作是通过集中对象的引用进行的,所以集中不能有重复对象。
集也有多种变体,可以实现排序等功能,如TreeSet,它把对象添加到集中的操作将变为按照某种比较规则将其插入到有序的对象序列中。它实现的是SortedSet接口,也就是加入了对象比较的方法。通过对集中的对象迭代,我们可以得到一个升序的对象集合。
(2)列表 (List):列表
列表的主要特征是其对象以线性方式存储,没有特定顺序,只有一个开头和一个结尾,当然,它与根本没有顺序的集是不同的。
列表在数据结构中分别表现为:数组和向量、链表、堆栈、队列。
关于实现列表的集合类,是我们日常工作中经常用到的,将在后边的笔记详细介绍。
(3)映射 (Map):键值对
映射与集或列表有明显区别,映射中每个项都是成对的。映射中存储的每个对象都有一个相关的关键字(Key)对象,关键字决定了对象在映射中的存储位置,检索对象时必须提供相应的关键字,就像在字典中查单词一样。关键字应该是唯一的。
关键字本身并不能决定对象的存储位置,它需要对过一种散列(hashing)技术来处理,产生一个被称作散列码(hash code)的整数值,散列码通常用作一个偏置量,该偏置量是相对于分配给映射的内存区域起始位置的,由此确定关键字/对象对的存储位置。理想情况下,散列处理应该产生给定范围内均匀分布的值,而且每个关键字应得到不同的散列码。
集合类简介
java.util中共有13个类可用于管理集合对象,它们支持集、列表或映射等集合,以下是这些类的简单介绍
集:
HashSet: 使用HashMap的一个集的实现。虽然集定义成无序,但必须存在某种方法能相当高效地找到一个对象。使用一个HashMap对象实现集的存储和检索操作是在固定时间内实现的.
TreeSet: 在集中以升序对对象排序的集的实现。这意味着从一个TreeSet对象获得第一个迭代器将按升序提供对象。TreeSet类使用了一个TreeMap.
列表:
Vector: 实现一个类似数组一样的表,自动增加容量来容纳你所需的元素。使用下标存储和检索对象就象在一个标准的数组中一样。你也可以用一个迭代器从一个Vector中检索对象。Vector是唯一的同步容器类??当两个或多个线程同时访问时也是性能良好的。(同步的含义:即同时只能一个进程访问,其他等待)
Stack: 这个类从Vector派生而来,并且增加了方法实现栈??一种后进先出的存储结构。
LinkedList: 实现一个链表。由这个类定义的链表也可以像栈或队列一样被使用。
ArrayList: 实现一个数组,它的规模可变并且能像链表一样被访问。它提供的功能类似Vector类但不同步。
映射:
HashTable: 实现一个映象,所有的键必须非空。为了能高效的工作,定义键的类必须实现hashcode()方法和equal()方法。这个类是前面java实现的一个继承,并且通常能在实现映象的其他类中更好的使用。
HashMap: 实现一个映象,允许存储空对象,而且允许键是空(由于键必须是唯一的,当然只能有一个)。
WeakHashMap: 实现这样一个映象:通常如果一个键对一个对象而言不再被引用,键/对象对将被舍弃。这与HashMap形成对照,映象中的键维持键/对象对的生命周期,尽管使用映象的程序不再有对键的引用,并且因此不能检索对象。
TreeMap: 实现这样一个映象,对象是按键升序排列的。
下图是集合类所实现的接口之间的关系:
Set和List都是由公共接口Collection扩展而来,所以它们都可以使用一个类型为Collection的变量来引用。这就意味着任何列表或集构成的集合都可以用这种方式引用,只有映射类除外(但也不是完全排除在外,因为可以从映射获得一个列表。)所以说,把一个列表或集传递给方法的标准途径是使用Collection类型的参数。
List接口
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。
和下面要提到的Set不同,List允许有相同的元素。
除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,返回一个ListIterator接口,和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
实现List接口的常用类有LinkedList,ArrayList,Vector和Stack。
ArrayList类
ArrayList实现了可变大小的数组。它允许所有元素,包括null。ArrayList没有同步。
size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。ArrayList当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。
和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
Map接口
请注意,Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射。
HashMap类
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。,但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。
----------------------------------------------------------------------------
1.-------------------->
List是接口,List特性就是有序,会确保以一定的顺序保存元素.
ArrayList是它的实现类,是一个用数组实现的List.
Map是接口,Map特性就是根据一个对象查找对象.
HashMap是它的实现类,HashMap用hash表实现的Map,就是利用对象的hashcode(hashcode()是Object的方法)进行快速(Hash)散列查找.(关于散列查找,可以参看<<数据结构>>)
2.-------------------->
一般情况下,如果没有必要,推荐代码只同List,Map接口打交道.
比如:List list = new ArrayList();
这样做的原因是list就相当于是一个泛型的实现,如果想改变list的类型,只需要:
List list = new LinkedList();//LinkedList也是List的实现类,也是ArrayList的兄弟类
这样,就不需要修改其它代码,这就是接口编程的优雅之处.
另外的例子就是,在类的方法中,如下声明:
private void doMyAction(List list){}
这样这个方法能处理所有实现了List接口的类,一定程度上实现了泛型函数.
3.--------------------->
如果开发的时候觉得ArrayList,HashMap的性能不能满足你的需要,可以通过实现List,Map(或者Collection)来定制你的自定义类
二/工具类——“低耦合”
其实理解了集合框架也就差不多了。工具类,正如上面说过的,是对集合功能的扩展,其中大部分是static函数,一般不必实例化创建对象,而直接调用对集合进行操作。
接下来为了方便理解,以Array Arrays ArraysList
Array:认真看api索引的话,Array有两个。一个是sql中的接口,一个是类,我们在这里说的是这个类。
Arrays:对数组的一些列操作。
ArrayList是一个容器。
1)精辟阐述:
可以将 ArrayList想象成一种“会自动扩增容量的Array”。
2)Array([]):最高效;但是其容量固定且无法动态改变;
ArrayList: 容量可动态增长;但牺牲效率;
3)建议:
基于效率和类型检验,应尽可能使用Array,无法确定数组大小时才使用ArrayList!
不过当你试着解决更一般化的问题时,Array的功能就可能过于受限。
4)Java中一切皆对象,Array也是对象。不论你所使用得Array型别为何,
Array名称本身实际上是个reference,指向heap之内得某个实际对象。
这个对象可经由“Array初始化语法”被自动产生,也可以以new表达式手动产生。
5)Array可做为函数返回值,因为它本身是对象的reference;
6)对象数组与基本类型数组在运用上几乎一模一样,唯一差别在于,前者持有得是reference,后者直接持有基本型别之值;
例如:
string [] staff=new string[100];
int [] num=new int[10];
7)容器所持有的其实是一个个reference指向Object,进而才能存储任意型别。当然这不包括基本型别,因为基本型别并不继承自任何classes。
8)面对Array,我们可以直接持有基本型别数值的Array(例如:int [] num;),也可以持有reference(指向对象)的Array;但是容器类仅能持有reference(指向对象),若要将基本型别置于容器内,需要使用wrapper类。但是wrapper类使用起来可能不很容易上手,此外,primitives Array的效率比起“容纳基本型别之外覆类(的reference)”的容器好太多了。
当然,如果你的操作对象是基本型别,而且需要在空间不足时自动扩增容量,Array便不适合,此时就得使用外覆类的容器了。
9)某些情况下,容器类即使没有转型至原来的型别,仍然可以运作无误。有一种情况尤其特别:编译器对String class提供了一些额外的支持,使它可以平滑运作。
10)对数组的一些基本操作,像排序、搜索与比较等是很常见的。因此在Java中提供了Arrays类协助这几个操作:sort(),binarySearch(),equals(),fill(),asList().
不过Arrays类没有提供删除方法,而ArrayList中有remove()方法,不知道是否是不需要在Array中做删除等操作的原因(因为此时应该使用链表)。
11)ArrayList的使用也很简单:产生ArrayList,利用add()将对象置入,利用get(i)配合索引值将它们取出。这一切就和Array的使用方式完全相同,只不过少了[]而已。
2.参考资料:
1)效率:
数组扩容是对ArrayList效率影响比较大的一个因素。
每当执行Add、AddRange、Insert、InsertRange等添加元素的方法,都会检查内部数组的容量是否不够了,如果是,它就会以当前容量的两倍来重新构建一个数组,将旧元素Copy到新数组中,然后丢弃旧数组,在这个临界点的扩容操作,应该来说是比较影响效率的。
ArrayList是Array的复杂版本
ArrayList内部封装了一个Object类型的数组,从一般的意义来说,它和数组没有本质的差别,甚至于ArrayList的许多方法,如Index、IndexOf、Contains、Sort等都是在内部数组的基础上直接调用Array的对应方法。
2)类型识别:
ArrayList存入对象时,抛弃类型信息,所有对象屏蔽为Object,编译时不检查类型,但是运行时会报错。
ArrayList与数组的区别主要就是由于动态增容的效率问题了
3)ArrayList可以存任何Object,如String等。
引用:
http://www.cnblogs.com/mengdd/archive/2013/01/19/2868095.html
http://www.blogjava.net/leishengwei/archive/2012/03/20/372246.html
http://my.oschina.net/wisedream/blog/137045
http://www.cnblogs.com/eflylab/archive/2007/01/20/625216.html
http://www.blogjava.net/EvanLiu/archive/2007/11/12/159884.html
http://www.cnblogs.com/wuyuegb2312/p/3867293.html
http://blog.sina.com.cn/s/blog_5ce1fe770100b0ay.html Java中Array与ArrayList的主要区别
最后,感谢众多优秀的博文给予的帮助,以上内容如有错误欢迎指正