OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks论文阅读笔记
文章目录
- OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks论文阅读笔记-2014
- Abstract
- 1.Introduction
- 2.Vision Tasks
- 3.Classification
- 3.1Model Design and Training
- 3.2Feature Extractor
- 3.3Multi-Scale Classification
- 3.4Results
- 3.5ConvNets and Sliding Window Efficiency
- 4.Localization
- 4.1Generation Predictions
- 4.2Regressor Training
- 4.3Combining Predictions
- 4.4Experiments
- 5.Detection
- 6.Discussion
OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks论文阅读笔记-2014
Abstract
我们提出了一个使用CNN用于分类、定位、检测的集成框架,展示了如何将多尺度以及滑窗方法有效的应用在一个卷积网络中,同时介绍了一种新的基于深度学习的定位方法(通过学习去预测目标的边界)。bbox之后被累积而不是抑制,以便提升检测结果的信度,我们也展示了,**可以同时使用一个shared network学习多个不同任务。**集成网络取得了ILSVRC2013定位任务的冠军,对于检测与分类任务取得很好结果。最后,我们从我们最好的模型中提出一个特征提取器,叫做OverFeat。
1.Introduction
从图片中识别出最主要的目标的类别这一任务一直以来都是一个很重要的任务。CNN在小的数据集比如Caltech-101的准确率尽管不错,但没有达到破纪录的水平。然而,大型数据集的到来使得卷积网络极大地提升了效果,比如ImageNet。
ConvNet在这些任务上的主要优点在于,整个系统是端到端训练的,输入raw pixels,输出最后categories,从而不用人工设计特征提取器。主要的不足在于,它们需要非常非常多的标注数据。
本文主要贡献点在于,展示训练一个CNN网络同时完成分类、定位以及检测,这样可以对这些任务的分类准确率和定位准确率都有所提升。文章**提出了一种新的整合方法,将目标检测、识别、定位整合到一个ConvNet中,提出了一种通过积累预测的box来完成定位和检测的方法。我们认为,通过将许多次定位的预测结果进行组合,探测过程就可以在不在背景样本训练的情况下进行,这样可以避免时间消耗以及复杂的bootstraping过程。**不在背景中训练也是的网络只关心positive classes来取得更高准确率。
虽然ImageNet分类数据集中的图像都包含一个大致位于中间且占据图像大部分的目标,但是我们感兴趣的目标有时在尺寸以及图像中的位置上变化范围很大。解决这个问题的第一个方法是在图像中多个位置使用ConvNet处理,使用滑窗的这种方式,并且多尺度处理。尽管使用这种方式,也可能会出现,滑窗正好包含一个可识别目标的一部分(比如狗的头),**而不是整个目标,也不是目标的中心。这就导致分类结果很好,但是检测和定位结果较差。**因此,第二种想法是训练一个系统,不止对每个窗口进行分类,而且生成包含与这个窗口相关的目标的位置以及bbox预测。第三种想法是在每个位置和尺寸上对每一类目标是否在该位置存在积累证据。
ImageNet在定位和分类任务都取得了很好的效果,但是并没有解释为什么会奏效,我们的文章是第一篇清晰解释为什么ConvNets可以在ImageNet上被用来定位和检测。在本文中,定位与检测这两个术语的意思与ImageNet2013竞赛中的一致,它们的唯一区别在于评估准则的(evaluation criterion)不同,都包含了对图像中每个目标预测bbox。
2.Vision Tasks
我们按照难度把CV任务排序:分类、定位、检测,每一个优势后面任务的一个子任务。我们把所有任务集合到一个框架中,共享学习到的feature。接下来将分别介绍。
我们在参加了ILSVRC2013竞赛。
比赛中的分类任务是:每张图片与一个label相连接,标签指出图像中的主要目标,允许5次猜测(top-5 error rate),这是因为图像中可能存在许多小的未标记目标。
比赛中的定位任务是:同样是每张图片5次猜测,对每一个猜测返回一个预测的bbox,IoU>0.5认,同时label为正确类才为正确(每次猜测返回一个label和对应的一个bbox),一般就只有一个目标,对分类的结果的bbox进行预测。
检测任务:与定位任务的主要不同在每张图可能有很多不同的目标(也可能是0)。通过平均准确率均值(mAP)来惩罚假阳性。
下图展示了我们在定位和检测中的一些例子,分类和定位任务share同一个dataset,而检测任务由于可能包含多种目标,需要额外标注。

3.Classification
我们的分类网络结构与AlexNet类似,但是提升了网络设计和inference step。
3.1Model Design and Training
我们在ImageNet2012训练集上进行训练(1.2million,1000类),与AlexNet一样,我们训练时固定输入图像尺寸,多尺度训练在下部分介绍。每张图像下采样到最小维度256像素,随机取5个crop(221 * 221)以及它们的水平翻转,batchsize = 128,网络的权重随机初始化服从分布 ( μ , σ ) = ( 0 , 1 ∗ 1 0 − 2 ) (\mu,\sigma)=(0,1*10^{-2}) (μ,σ)=(0,1∗10−2),之后使用SGD进行优化,动量0.6,权值衰减参数1*10-5。学习率初始化为0.05,在(30,50,60,70,80)个epoah之后减半。FC层(6,7层)使用Dropout(0.5)。

在表1和表3中我们详细列出了网络结构,注意到,在训练过程中,==我们的结构输出是非空间的(non-spatial),因为输出是1 * 1 *channels的,与之相反,测试阶段,我们输出是空间的(spatial)。==前五层与AlexNet结构相似,使用了ReLU和最大池化。不同点如下,没使用对比归一化(前者的LRN?),池化层是不重叠的,在前两层我们使用更小的步长2得到了更大的特征图,更大的步长提升了速度但是影响了准确率。
图二中我们展示了前两层卷积层,第一层主要获取了方向边缘、图案样式、斑点。第二层由许多形式,一些扩散了,一些是粗线条结构和边缘。

3.2Feature Extractor
我们与论文一起发布了一个特征提取器“OverFeat”,用来为CV任务提供powerful features,有两个版本,fast/accurate。每种结构都在表1和表3中列出,表4中我们比较了它们的参数量和连接量。accurate模型比fast更准确(14.18%相比于16.39%,表2),但是它需要接近两倍的连接。使用7种accurate模型组合可以达到13.6%分类错误率。


3.3Multi-Scale Classification
AlexNet中,使用固定的10个crop(4个角+1个中间以及它们的水平翻转)的结果平均,来加强表现。然而,这种方法可能会忽略图像中的某些区域,而且这些crop的重叠也会导致计算的冗余。另外,它只使用在单一尺度,这个尺度可能不是网络表现最好的尺度。
我们将整张图像放入网络,多尺度进行处理。尽管滑窗法在一些种类的模型上不可用,但在卷积网络还是很有效的。这种方法可以使得更多的views进行投票得出最好结果,在保持效率的同时提升了鲁棒性。对任意输入尺寸的图像,在每个尺度处理之后得到的是一个C-channels的空间图,C为类别数。
总体的下采样率大概为2 * 3 * 2 *3 =36,因此,当densely处理之后,同一坐标轴方向,输入图像每36个像素最后生成一个分类向量。这种输出的粗略分布比原来10个crop的方法相比降低了表现,因为网络滑窗没有与图像中的目标很好的对齐。为了解决这个问题,我们在最后一个池化层每个偏移处使用下采样操作,这就移除了这一层对分辨率的损失,使得下采样率由36变成了12。
下面具体解释如何完成这个分辨率提升操作。我们将输入图像rescale到6种尺度,导致在第五层的池化之前有多种分辨率(表5)。这些特征图之后进行池化操作然后送入分类器,按照图3中的流程进行处理。

(a)对给定尺度这张图像,从layer 5 池化前开始。
(b)对每个未池化的maps,进行一个3 * 3的非重叠最大池化操作,一共3 * 3次池化,每次对池化操作的位置有一个偏移,对{x,y}分别偏移{0,1,2}。
(c)经过上面操作之后一共得到了3 * 3 = 9个池化之后的特征图。
**(d)分类器(6、7、8层)的输入是固定的尺寸5 * 5,对每一个池化后的输入都生成C-维的输出向量。把分类器当作滑窗(5 * 5),对(c)之后的每个图进行操作,生成一系列二维的 * 9(上面生成9个图) * C的输出。**相当于把FC层当作卷积。
(e)最后把九个输出进行组合,reshape成一个二维图 * C通道的输出。
上述过程的一维解释过程见图三。

这些操作可以看作是把最后一层池化层和FC层在每个可能的偏移位置近几年行出来,然后把这些输出交错来得到融合的结果。
上面的过程对每张图像的水平翻转同样进行一遍。我们通过下面的方法得到最后的分类结果:**首先对图片以及翻转图片的所有尺度的结果,找到每一类的空间最大值,把每个输出变成1 * 1 * C,之后对这些若干个1 *1 *C结果进行平均,得到一个1 1 C结果,最后根据评价规则找到top-1或top-5结果。
直观来看,网络的两部分,特征提取层与分类层,以相反的方式工作。在特征提取阶段,filters一次将整个图像进行卷积操作,从计算角度看,这比使用固定尺寸滑窗再将不同位置的结果汇集到一起有效率得多。然而这些在分类阶段正好相反,分类阶段我们要在最后一层卷积层输出的不同尺寸位置的特征图中找到一个固定尺寸的表示(representation),因此分类器使用固定的5 * 5,并且在所有的特征图上使用。上面的策略可以使得特征图中的特征表示与分类器的特征表很好的完成对齐(fine alignment)。
3.4Results
在表2中,我们使用不同的方法进行实验,并且将它们与AlexNet效果进行对比。使用上面的6个尺度的方法,进行fine stride,取得了16.27%的top-5错误率。如预想的一样,使用更少的尺度训练会降低表现。图3中展示的fine stride方法在单尺度中带来相对小的提升,但是对于多尺度来说也很重要。

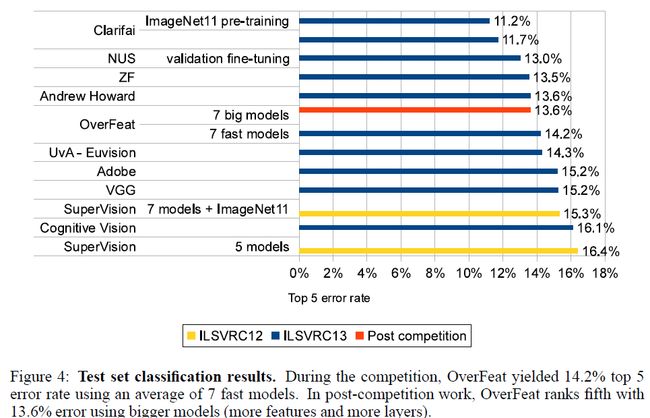
在图4中,我们给出了我们在2013比赛中的测试结果,我们的模型(OverFeat)取得了14.2%准确率(使用了7个网络综合,每个都由不同的初始化进行训练的),获得了第五名。**在比赛之后,我们通过使用更大的模型(更多特征以及更多层数)使得结果提升到13.6%的错误率。**由于时间限制,这些大的模型未被完全训练,之后还会有提升。
3.5ConvNets and Sliding Window Efficiency
与许多滑窗方法对输入的每个滑窗进行计算整个pipeline相反,卷积网络滑窗时十分高效,因为它对重叠的区域的计算自然共享。
对于网络中的FC层,我们也可以替换为卷积层,方法就是将卷积核的大小,设置为输入的大小,channel数为原本线性输出的维度,之后的FC层可以更换成1 * 1的卷积核。这样网络就是一个全卷积网络,这样做的好处在于:
原来网络是固定尺寸输入,最后卷积层要打平,连接FC层,这块的全连接操作输入输出维度都是固定的。对于测试时,尺寸不同就无法进行,也要随机crop到这个尺寸(AlexNet),效果不好。
**经过修改之后,都变成卷积操作,训练时最后的输出是1 * 1 * C,测试时,根据输入尺度不同,输出可能是x * y * C,再对 x*y 进行某种池化操作变成1 * 1,即可得到输出,实现了对不同尺寸输入都可以完成测试。**如图5所示,由于卷积是bottom-up,相邻窗口共有的计算只需要执行一次。

4.Localization
对训练好的分类网络,把分类器替换成regression回归网络,使它在每个空间位置和尺度来预测目标的bbox。之后将这些回归的预测结果以及分类结果进行组合。
4.1Generation Predictions
在所有的位置和尺度上同时运行分类器以及回归网络,因为它们共享特征提取层,所以只有最后的回归层需要在分类层计算之后,再进行计算。最后softmax输出层,对每一种类别calss,会对每一个位置的框中是否存在这个类别的目标给出一个信度分数,因此我们可以给每一个bbox分配一个信度。
4.2Regressor Training
回归层将第五层之后经过池化的特征图作为输入,**有两层隐层的FC层,分别为4096和1024通道。最后的输出是四维的,分别对应左上角和右下角的坐标,**与分类一样,由于使用fine stride,结果也是有3 * 3的copies。具体结构如图8所示。

我们从分类网络固定前面的特征提取层,并且使用L2 loss(预测bbox与ground truth之间)来训练回归网络。最后的回归层是class-specific,有1000个不同的版本,每一类一种,我们使用与3.1中一致的尺度设置来训练回归网络。**将ground truth移入到最后一层3 * 3offset中与输出的预测结果进行对比。如图8(d),输出为:2 *3 的map中(共9层shifts),每个位置有一个四维输出;将ground trut移到该层进行对比,求L2loss。**当然,只对2 * 3块中,生成的预测bbox与输入视野重叠大于0.5的进行回归,因为小于0.5就不太可能包含物体。
使用多尺度训练和回归网络对于跨尺度预测结果的组合很重要,单尺度训练可能在这个尺度表现很好但是在其他尺度表现不佳。**多尺度训练将使预测在各个尺度之间正确匹配,并指数增加合并的预测的置信度。**但是反过来,这也使得网络只在这几个尺度表现比较好,而不是在各种尺度上表现都不错(这是检测所要应对的问题)。
4.3Combining Predictions

见图7,我们通过一种贪婪融合策略(greedy merge strategy)来对回归的bbox进行组合,算法如下:
(a) C s C_s Cs表示以下这些类别的集合:表示该尺度s(s=1、2、3、4、5、6)下,进行检测的top-k输出类别。
(b) B s B_s Bs表示以下预测bbox的集合:对 C s C_s Cs中的每个类别在对应尺度s上,通过回归网络进行预测,得到的bbox。
(c)合并所有的 B s B_s Bs,得到所有bbox的集合 B B B。
(d)重复merging过程,直到:
(e) ( b 1 ∗ , b 2 ∗ ) = a r g m i n b 1 ≠ b 2 ∈ B m a t c h _ s c o r e ( b 1 , b 2 ) (b^*_1,b^*_2)=argmin_{b_1\ne b_2\in B}match\_score(b_1,b_2) (b1∗,b2∗)=argminb1=b2∈Bmatch_score(b1,b2) (选取匹配分数最小,即最相近的两个bbox进行融合)
(f) 如果 m a t c h _ s c o r e ( b 1 ∗ , b 2 ∗ ) > t match\_score(b^*_1,b^*_2)>t match_score(b1∗,b2∗)>t,停止 (说明两个框匹配程度较差,不进行融合)
(g) 否则,对这两个框进行box_merge,将结果送入B,原来的删除。
计算match_score:将两个bbox的中心坐标距离以及两个box相交区域之和。
计算box_merge:计算bbox坐标的平均值,box融合。
最后将具有最大的class score的融合后的bbox输出为预测结果,这也是不断累积这些bbox对应的输入window进行检测得到的class outputs,最后最大score的融合后的bbox作为结果。


图6就是一个将bboxs融合成一个高信度bbox的例子。例子中,一些乌龟和鲸鱼的bbox在中间的multi-step步骤中出现,但是在最后结果中消失。不只是因为这些bbox信度很低(最大0.11和0.12),同样因为这些bbox没有熊的bbox那么连贯以得到信度的提升。熊的bboxes有很强的信度(每个尺度平均都有0.5)和好的匹配分数,因此在融合之后,大部分熊的bbox融合为一个高信度bbox,而假阳性由于缺少连续性和信度,消失了。这种分析方法通过奖励bbox的连续性,对假阳性更加鲁棒。
4.4Experiments
我们网络在ImageNet2012的验证集上实验结果如图9所示,图10展示了2012和2013定位比赛的结果。
我们的多尺度且multi-view方法取得很好效果,如图9,只是用中间的部分错误率很高。
对每个class使用单独的最后一层(Per-Class Regressor,PCR)令人吃惊地居然没有共享最后一层的效果好。这可能是因为相对来说单独每类的图像还是较少,导致训练未完成。通过对相似的class共享最后一层,可能会取得更好的效果。(比如对于所有类别的狗,训练一种top layer,对于所有交通工具类别,训练一种top layer)。


5.Detection
检测的训练过程与分类的训练过程相似,只不过一张图像的多个位置被同时训练,可能有多个目标。因为模型是卷积的,所以所有位置的权值都是共享的。与定位任务最主要的不同在于当没有目标存在时,预测背景类别(background class)的必要性。通常来说,负样本例子通常在训练中随机出现,然后通过bootstrapping过程添加负样本到训练中,bootstrapping的size需要调整好以免模型在小数据集上过拟合。为了克服以上问题,**我们通过为每个图像选择一些有趣的负面示例(例如随机的或最令人反感的示例)来进行负面的训练。**这种方法虽然更耗计算,但是流程更简单,由于检测的特征提取用的是分类任务的,无需改变,那么负训练这个过程并没有消耗太多时间。
图11中我们给出了ILSVRC2013检测比赛的结果,我们的方法与前三名的其他两个不同,它们最开始使用了一个分割操作来使得候选windows从200000降到2000,这种方法加速了测试,而且减少了假阳性。与dense sliding相比,selective search效果更好,因为它将不太可能的window抛弃,减少了假阳性。

6.Discussion
提出了一种多尺度、滑窗的方法,可以用来分类、定位、检测。目前在ILSVRC2013数据集分别排名4、1、1。第二个贡献在于我们解释了为什么卷积网络可以有效应用在检测和定位任务中。我们提出了一个整合的流程,在共享特征提取的基础上,完成不同的任务。
我们的方法可能在下面几个方面改进:
对于定位,我们没有在整个网络进行反向传播(只在回归网络),这样可能会提升表现。
我们使用的是L2 loss,而不是衡量表现的IoU,直接使用IoU也许会提升。
对bbox增加额外的参数可能会降低输出的相关性,这样可能会对训练有帮助。