知识图谱基础Part2_图数据处理算法与模型
//2019.05.22
一、图概述
1、图是由顶点集合以及顶点之间的关系集合组成的一种数据结构:G=(V,E)
2、分类:有向图(Directed graph)、无向图(Undirected graph)
(带权图(weighted graph)\属性图)
3、图数据处理的挑战
(1)结点和边可变大小
(2)结点无序(CNN\RNN)
(3)不同结点的局部连接不同
(4)结点之间相互依赖
(在这里区分节点和结点:节点被认为是一个实体,有处理能力,比如网络中的一台计算机;结点只是一个交叉结点,一般认为数据结构中的点都是结点)
二、基本图算法
1、基本遍历算法
(1)遍历的概念:从图的某一个顶点开始,按照某种算法不重复的访问图的所有顶点
(2)遍历算法
- 广度优先算法(BFS):引入队列解决
- 深度优先算法(DFS):引入链表
2、路径搜索算法
(1)最短路径问题:在带权图中,求两个顶点间所有可达路径中,边的权值之和最小的那一条路径。
(2)最短路径问题的经典算法:
- Dijkstra
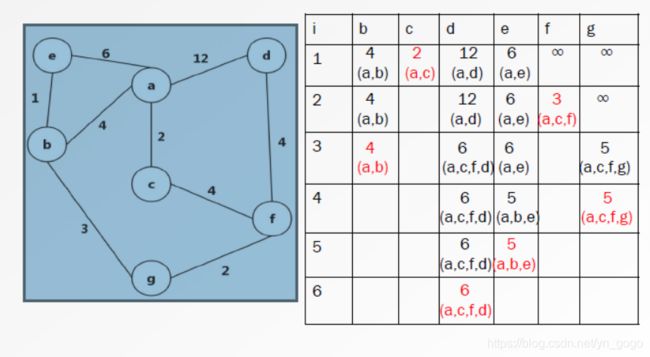
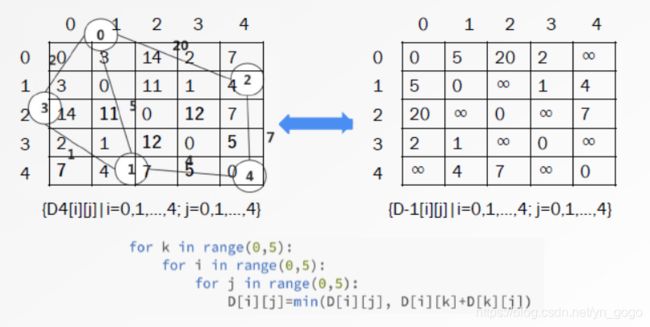
- Floyd
3、图匹配算法
(1)基本概念
- 二分图
- 匹配:图论中,一个匹配是一个边的集合,其中任意两条边都没有公共顶点。
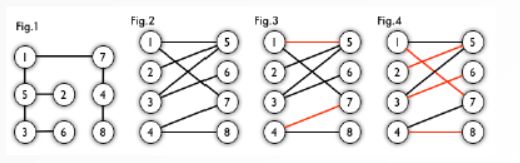
- 匹配边、匹配点
- 最大匹配:一个图的所有匹配中元素最多的匹配称之为最大匹配
- 完美匹配:一个图的最大匹配所对应的匹配点所构成的集合等于图的点集V,则称该匹配为完美匹配
- 增广路:从一个未匹配点v1出发,依次经过非匹配边、匹配边、非匹配边...最后一直到达另一个非匹配点v2,所组成的路称之为增广路(特性:可以将这个曾广路的匹配边和非匹配边互换,得到的最新的路径的匹配边数n比原来增加了1)
(2)算法:匈牙利算法
a)从图中选取未匹配点,并寻找增广路l;
b)对增广路上的未匹配边和匹配边进行互换,并将原增广路两端的未匹配点改为匹配点;
c)重复1,2,知道找不到增广路为止
4、图算法的应用
(1)最小生成树(引入贪心算法)
- Prim算法(加边法)
- Kruskal算法(加点法)
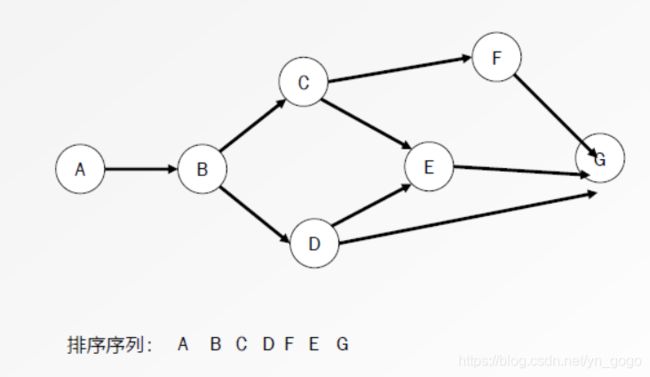
(2)拓扑排序
*对于一个DGA(有向无环图,不存在环的有向图),找到一个有顶点组成的序列,要求该序列应包含G的所有顶点组成的序列,要求该序列应包含G的所有顶点,且每个顶点只出现一次,且在后面的顶点一定没有通向前面所有顶点的路径。
*算法过程:a)从DGA图G中选取一个入度为0的顶点,删去除其所有的临边;b)将该顶点作为排序序列新的尾结点;c)重复1、2直到所有顶点进入序列中。
三、图信息传播算法
*典型应用:链接预测;权威度评估;商品推荐
*相关定义:
- n*n 邻接矩阵 A:A(i,j)表示结点i到结点j的权重,如果A(i,j)=A(j,i),则A是对称矩阵
- n*n 转移矩阵 P:P行和为1(概率分布,随机变量);P(i,j)表示结点i跳到结点j的概率
- n*n Laplacian矩阵 L:L(i,j)=
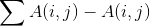 ;无向图中是半正定对称矩阵;奇异矩阵
;无向图中是半正定对称矩阵;奇异矩阵
(理解拉普拉斯矩阵,它的定义是度矩阵-邻接矩阵,奇异矩阵就是对应行列式等于0的方阵)
1、随机游走算法


(理解:下一时刻所在点的概率,就是把所有能跳过去的可能累加)
这里涉及一个平稳分布:对象按照转移概率游走一定步数,当对象所在结点的位置不再改;对于正常图,该平稳分布不依赖于初始分布
算法:迭代算法

(上面算法即是PageRank)
2、PageRank,HITS
(1)由1得PageRank,由PageRank演化出PopRank
*主要模拟图中各个类型之间不同关系的权重
*概念:
- Homogeneous Graph :一个图只有一种结点,如利用pagerank对网页排序中的网页
- Bi-Graph:图中有两种类型A、B,A与B之间有关系,A与A,B与B之间没有关系
- Heterogeneous Graph :一个图中有大于三种类型的结点,如作者、论文、会议
*计算:X、Y是同种不同类型的结点
 (其中
(其中![]() )
)
(2)DivRank
*传统的RandomWalk:高degree的结点控制了整个随机游走的过程,同时缺乏diversity(应该从每个clique中选出最有代表性的结点,而不是在单个最大的clique中选出最popular的结点)
(3)SimRank
*动机:SimRank提出了一种互补的方法,适用于具有对象到对象关系的任何领域,该方法根据对象与其它对象的关系来衡量对象发生时的结构上下文的相似性。实际上,其计算出一个度量值,表示“如果两个对象与相似的对象相关,那么它们是相似的”
*方法:构建一个图G^2,这个图里面的结点由原图G中任意两个结点的pair组成
(4)Co-Ranking:
*动机:以前的应用大多局限于同构网络,如出版物之间的引用网络。而Co-Ranking是一种利用多个网络对作者机器出版物进行联合排序的新方法,作者之间的社会网络连接、出版物之间的引文网络连接以及将前两个网络连接在一起的作者身份网络。新的Co-Ranking框架基于耦合的两个随机游走,分别按照PageRank范式对作者和文档进行排名。
*作用:解决了bi-graph的相互rank的问题
(5)子集传播模型-HITS
*子集传播模型:把互联网网页按照一定规则划分成两个甚至是多个子集,其中,某个子集具有特殊性质,很多算法会从这些具有特殊性质的子集出发,给予子集内网页初始值,之后根据这个特殊子集内网页和其它网页的链接关系,按照一定方式将权值传递到其它网页
*HIST算法:是子集传播算法的代表算法,其将网页分为Hub页面和Authority页面
(Hub页面:即很多指向高质量Authority页面链接的网页;Authority页面:与某个领域或者某个话题相关的高质量网页)
说的比较抽象,直白的说网址导航,就是一个Hub页面;而某个领域,如视频领域,腾讯或者优酷首页,就是个高质量的Authority页面。
假设1:一个好的Authority页面会被很多Hub页面指向;
假设2:一个好的hub页面会指向很多好的Authority;
假设3:判断扩展集中的Hub和Authority
*计算过程:
对每个网页设定两个初始值a0 = 1,h0 = 1,迭代计算两个权值
(Authority权值ai即为所有指向该页面的hi-1之和;Hub权值hi即为所有指向该网页的ai-1之和)

3、Label Propagation(标签传播算法:基于图的半监督算法)
(1)基于图的半监督多分类算法
- 大量的未标注的数据:低成本,易获取
- 少量的标注数据:高成本
(2)如何通过有监督的数据标注无监督的数据?
- 节点分类方法:使用一些局部节点的特征,不需要图结构信息
- 结合图信息的分类:如临近节点信息、节点的度、连接形式
(3)*LP的简单假设:样本间具有相关性
*基本方法:计算样本之间的相似度;将未标记的样本连接到相近已标注样本的类别上
---->但是这样会带来一些问题,如冲突样本如何判断标签
(4)LP算法:节点权重越大,表示两个节点越相似,那么label越容易传播过去,定义n*n概率转移矩阵p


注意,权重初始值,在构建图时计算给出,

*简化计算

四、图神经网络
1、图神经网络缘起
(1)传统神经网路处理的数据典型特点:平移等价性(图片)、层次组合性(句子)、稳定栅格结构(围棋、图片像素)
(2)图数据常见特点--->传统前馈网络、RNN、CNN难以处理这样的数据
- 结构可变(除图片像素外都没有固定排列的邻居;有的图为有向边,有的为无向边;)
- 扩展度和并行化(很多图数据有巨大模型)
2、图数据的常见任务
- 图的表示学习(得到整个图的向量表示;得到每个节点的向量表示)
- 图数据上的自编码器
- 图结构的生成
- 图上的分类、链接预测任务(典型任务:节点分类;链接预测;子图分类)
3、图数据的简便处理方法
- 遍历图结构得到节点序列,当做普通序列使用神经网络处理(----Neural AMR)
- 依照图中边的方向传播隐层状态(句法树作为输入)
4、图神经网络的概念
*特指输入数据为图的模型,而不是本身构建为图的模型
*流行框架将神经网络实现为一个计算图(节点表示函数,边表示反向传播路径;神经网络可以输入普通数据或者图数据)
5、图卷积网络
(1)谱聚类:从图论角度来说,聚类问题相当于一个图分割问题
*具体含义:给定一个图G=(V,E),顶点集V表示各个样本,带权的边表示各个样本之间的相似度,谱聚类的目的,便是要找到一种合理的分割图的方法,使得分割后形成若干个子图(连接不同子图的边的权重相似度尽可能低;同子图内的变得权重相似度尽可能高)
*如何把图的顶点集分割/切割为不相交的子图(并满足上面的要求)?---->可以让被割掉各边的*最小
*图切割
- RatioCut
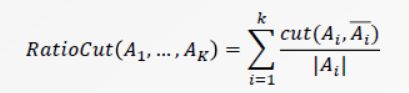
- NormalizedCut
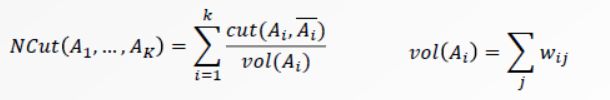
*图切割的等价形式

*具体操作步骤
- 求特征值并取前k个最小的,并将对应的特征向量排列起来,再按行进行k-means聚类
- 根据数据构造一个Graph,Graph的每个节点对应一个数据点,将相似的点连接起来,并且边的权重用于表示数据间的相似度,把这个Graph用邻接矩阵的形式表示出来,记为W
- 把W的每一列元素加起来得到N个数,把他们放在对角线上(其它地方为0),组成一个n*n的矩阵记为D,令L=D-W;
- 求出L的前k个特征值(从小到大),以及对应的特征向量{vk}
- 把这k个特征向量排列在一起组成N*k的矩阵,将其中每一行看作k维空间中的一个向量,并使用k-means算法进行聚类。
(2)图卷积模型:基于谱学习的方法
*动机:图的L矩阵描述了图结构-->可以利用图拉普拉斯矩阵的特征值和特征向量来研究图的性质
*目标:学习图中结点的向量表示(输入:结点特征;邻接矩阵;输出:结点表示;关键操作:Aggregator,Updater)
*问题及解决

*卷积核定义
 (但是要计算真个图的拉普拉斯矩阵的特征矩阵分解,对于大规模图,谱学习模型难以应用)
(但是要计算真个图的拉普拉斯矩阵的特征矩阵分解,对于大规模图,谱学习模型难以应用)
*改进


*谱算法缺陷

(3)基于空间的模型
*图模型的目标就是给出每个节点的表示;类比CNN,对每个点,基于空间的模型仅使用它的空间上的邻居计算卷积
*基于空间的模型可一般性的定义为

*基于空间的模型的组合方式
- 循环图神经网络(Gated GNN(GGNN))

- 消息传递网络(Message Passing NN,MPNN):是组合型网络,不同的图网络层叠而来
*消息传递步骤:
**消息传递(Aggregate/Propagation):负责传递邻居间的消息
**读出输出最终结果
*不同的消息传递网络

6、门控图网络
(1)Graph-LSTM:用来处理图结构信息
*LSTM:处理序列信息
*Tree-LSTM处理树结构信息

(2)图的处理:
图中如果存在环会导致无法训练;将图拆分成两个有向无环图,其中每一个有向无环图都可以用一个Graph-LSTM来处理(当图是一个链式结构时,等价于双向LSTM)
7、其它网络
(1)GraphSage
(2)其它模型:
- 时空模型:同时考虑时间和空间的影响
- 非局部模型:尤其对于非结构的数据,使用类似关注机制对整个图的任意位置计算权重