python-re模块
1.使用示例
def re_test():
# 匹配SA:后面的数字
re_pattern = re.compile(r'(?<=(SA:))\d{0,2}[.]\d{0,2}m2')
data = "$SA:1.42m2$体能状况评分(KPS)$"
# 获得所有匹配项
match_list = re.finditer(re_pattern, data)
for match in match_list:
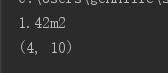
print(match.group())
print(match.span())输出:
2. 几种方法说明
1)匹配方法
# 从文本开始位置进行匹配,有则返回一个match类
re.match(data)
# 文中全部位置匹配,返回对应search类
re.search(data)
# 返回所有匹配的迭代器
re.finditer(re_pattern, data)2) 获取匹配
# group()获取组内匹配项参数1-99表示匹配的第几个()匹配内容,参数0表示返回整个re匹配的字符串
match.group() # 所有匹配
match.group(1) # 拿到第一个元祖匹配内容,若re_pattern中没有元祖,则报错
match.span(1) # 拿到第一个匹配的、元素的index3)替换和分割
re.sub(re_pattern, new_str, data) # new_str要替换的字符(函数)
re.split(re_split_pattern,data) # re_split_pattern分隔符