概率基础_贝叶斯算法_交叉验证网格搜索
贝叶斯算法
- 概率基础
- 朴素贝叶斯算法
- 精确率和召回率
- 交叉验证和网格搜索
概率基础
概率就是一件事情发生的可能性
- 扔出一个硬币 结果头像朝上
- 某天是晴天
联合概率和条件概率

注: 所有条件之间是相互独立的
朴素贝叶斯算法
P(科技|文档) 文档1: 词1 词2 词3 --> P(科技|词1 词2 词3)
P(娱乐|文档) 文档2: 词1‘ 词2 ’ 词3‘
贝叶斯公式:


举例:

为了防止某个类别为零: 我们引入拉普拉斯平滑

sklearn朴素贝叶斯实现API

里面有个参数:

朴素贝叶斯算法流程:

code:
def naviebayes2():
"""
朴素贝叶斯进行文本分类
:return: None
"""
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计['a','b','c','d']
x_train = tf.fit_transform(x_train)
print(tf.get_feature_names())
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
print(x_train.toarray())
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print("预测的文章类别为:", y_predict)
# 得出准确率
print("准确率为:", mlt.score(x_test, y_test))
# print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
return None
if __name__ == "__main__":
# knncls()
naviebayes2()
注:
- 不需要调参
优缺点



精确率和召回率

分类模型评估的API:


print("每个类别的精确率和召回率:",classification_report(y_test,y_predict,target_names=news.target_names))
交叉验证和网格搜索

交叉验证过程:
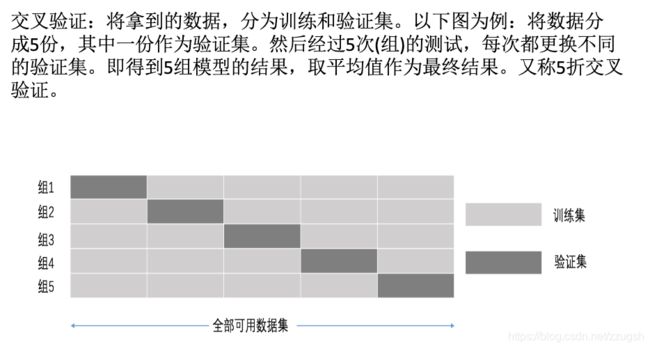
超参数搜索-网格搜索
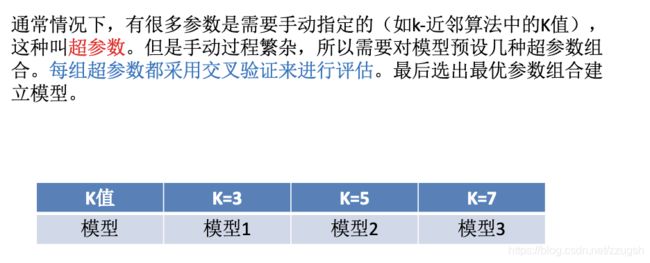
超参数搜索-网格搜索API


将刚才的k-近邻算法案例改成网格搜索
def knncls():
'''K近邻预测用户签到'''
# 读取数据
data = pd.read_csv("/Users/guosihan/Desktop/ml/train.csv")
# print(data.head(10))
# 处理数据
# 1.缩小数据的范围 条件方法 查询、筛选数据
data = data.query("x > 1.0 & x < 1.2 & y > 2.5 & y < 2.75")
# 处理时间数据
time_value = pd.to_datetime(data['time'],unit = 's')
# print(time_value)
# 把日期格式转换成字典格式
time_value = pd.DatetimeIndex(time_value)
# 构造一些特征
data["day"] = time_value.day
data["hour"] = time_value.hour
data["weekday"] = time_value.weekday
# 把时间戳特征删除
data = data.drop(["time"],axis = 1) # 1 表示 列
# print(data)
# 把签到数量少于3个的目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 取出数据当中的特征值和目标值
y = data['place_id']
# print(y)
x = data.drop(['place_id'],axis = 1)
# print(x)
# 进行数据的分割训练集合测试集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)
# 特征工程(标准化)
std = StandardScaler()
# 要对测试集合训练集特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进行算法流程
knn = KNeighborsClassifier() # 这里是K值等于5
# 构造一些参数的值进行搜索
param = {"n_neighbors":[3,5,10]}
# 进行网格搜索
gc = GridSearchCV(knn,param_grid=param,cv = 2)
gc.fit(x_train,y_train)
# 预测准确率
print("测试集上的准确率:",gc.score(x_test,y_test))
print("交叉验证当中验证结果:",gc.best_score_)
print("选择最好的模型是:", gc.best_estimator_)
print("每个超参数交叉验证的结果:",gc.cv_results_)
# # fit,predict,score
# knn.fit(x_train,y_train)
# # 得出预测结果
# y_predict = knn.predict(x_test)
# print("预测的目标签到位置:",y_predict)
# # 得出准确率
# print("预测的准确率:",knn.score(x_test,y_test))
return None
if __name__ == "__main__":
knncls()
# naviebayes()
输出:
测试集上的准确率: 0.4452488687782805
交叉验证当中验证结果: 0.4048481190907262
选择最好的模型是: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=10, p=2,
weights='uniform')
每个超参数交叉验证的结果: {'mean_fit_time': array([0.00453806, 0.0024606 , 0.00240445]), 'std_fit_time': array([2.06398964e-03, 7.51018524e-06, 1.33514404e-04]), 'mean_score_time': array([0.17572606, 0.18804896, 0.21286154]), 'std_score_time': array([0.00485814, 0.00154102, 0.00298357]), 'param_n_neighbors': masked_array(data=[3, 5, 10],
mask=[False, False, False],
fill_value='?',
dtype=object), 'params': [{'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 10}], 'split0_test_score': array([0.36446923, 0.39075881, 0.4039036 ]), 'split1_test_score': array([0.36476326, 0.38996139, 0.40581183]), 'mean_test_score': array([0.36461477, 0.39036411, 0.40484812]), 'std_test_score': array([0.00014701, 0.00039869, 0.00095406]), 'rank_test_score': array([3, 2, 1], dtype=int32)}