【数据结构与算法Python描述】——Python列表实现原理深入探究及其常用操作时间复杂度分析
文章目录
- 一、使用动态数组实现列表
- 1. 动态数组概念引入
- 2. 验证列表实现策略
- 3. 动态数组算法实现
- 二、摊销法分析时间复杂度
- 1. 摊销法使用示例
- 2. 数组容量指数增长
- 3. 数组容量等差增长
- 三、列表常见操作时间复杂度
- 1. 非列表修改类操作
- 2. 列表修改类操作
- 2.1 添加元素
- 2.2 删除元素
- `pop()`
- `remove()`
- 2.3 扩充列表
- 3. 创建列表类操作
由文章【数据结构与算法Python描述】——字符串、元组、列表内存模型简介中的讨论可知,对于Python的str、list和tuple三种序列类型,不论连续内存空间是直接存储对象数据(如:str)还是对象数据的引用(如:list、tuple),连续内存的大小都需要在序列创建时根据计划保存的元素数量就指定。
然而,Python的解释器内部一定针对列表的实现做了特殊处理,否则,如果后续希望使用append()或extend()方法向列表中添加元素就可能会有问题,因为系统可能已经将列表序列临近的内存空间分配用于存储其他数据了,这对于字符串或元组则不会有问题,因为二者均为不可变类型,这意味着二者也不用支持类似列表中方法来实现容量的增长。
针对上述疑问,本文将探究Python中列表的实现原理,以及列表支持的常见操作如append()、insert()等的时间复杂度。
一、使用动态数组实现列表
1. 动态数组概念引入
实际上,Python底层实现列表的算法为动态数组,通过该算法实现的列表特点为:
- 列表实例的底层维护了一个容量大于当前列表长度的数组,如:开发者可能创建的是一个含有5个元素的列表,但实际上支持列表的数组容量实际为8;
- 当数组容量已满时,系统会先创建一个新的、容量更大的数组,接着使用容量已满的旧数组中的元素来从头开始初始化新数组,最后旧数组会被解释器垃圾回收。
2. 验证列表实现策略
为了验证列表底层的确是基于动态数组实现,现使用下列代码。需要说明的是,下列代码中使用的getsizeof(object)方法来自sys模块,其功能是以字节为单位返回对象占用的内存大小,但对于采用引用型数组的列表而言,该方法的特殊性在于:只会返回列表底层数组以及列表对象实例属性的字节数,而不会考虑数组每一个元素所引用具体数据对象的字节数。
import sys
lst = list()
for each in range(27):
lst_length = len(lst)
lst_size = sys.getsizeof(lst)
print('列表长度:{0:2d}; 占用字节大小:{1:4d}'.format(lst_length, lst_size))
lst.append(None)
上述代码的执行结果为:
列表长度: 0; 占用字节大小: 56
列表长度: 1; 占用字节大小: 88
列表长度: 2; 占用字节大小: 88
列表长度: 3; 占用字节大小: 88
列表长度: 4; 占用字节大小: 88
列表长度: 5; 占用字节大小: 120
列表长度: 6; 占用字节大小: 120
列表长度: 7; 占用字节大小: 120
列表长度: 8; 占用字节大小: 120
列表长度: 9; 占用字节大小: 184
列表长度:10; 占用字节大小: 184
列表长度:11; 占用字节大小: 184
列表长度:12; 占用字节大小: 184
列表长度:13; 占用字节大小: 184
列表长度:14; 占用字节大小: 184
列表长度:15; 占用字节大小: 184
列表长度:16; 占用字节大小: 184
列表长度:17; 占用字节大小: 256
列表长度:18; 占用字节大小: 256
列表长度:19; 占用字节大小: 256
列表长度:20; 占用字节大小: 256
列表长度:21; 占用字节大小: 256
列表长度:22; 占用字节大小: 256
列表长度:23; 占用字节大小: 256
列表长度:24; 占用字节大小: 256
列表长度:25; 占用字节大小: 256
列表长度:26; 占用字节大小: 336
分析上述代码的执行结果:
- 由第一行可知,即使列表长度为0时,该列表对象就已经占用了一定的字节数(在笔者的系统上为56个字节),实际上这是因为每一个Python中的对象都会保存一些状态信息,如:
- 表明创建该对象的类的引用;
- 表明当前列表元素个数的长度
_array_length; - 表明当前列表底层数组的容量
_array_capacity; - 代表当前列表底层数组的引用
_array。
- 由第二行可知,当插入第一个元素时,底层数组的容量增长了32个字节,在本64位的机器上(即内存地址占8个字节),这意味着此时列表底层的数组可保存4个对象的引用,这和插入第2,3,4个元素后并未见容量变化这一现象是一致的;
- 由第六行可知,插入第5个元素后,底层数组的容量又增长了32个字节,从而使得其又可以多存储4个对象的引用;
- 后续底层数组的容量继续增长,区别是增长得更快了,即从单次增长32个字节到64个字节,再到72个字节,进而到80个字节。
3. 动态数组算法实现
尽管Python的list类基于动态数组已经提供了高度优化的实现,但通过亲自实现一个类似功能的类,对于开发者大有裨益。
为了实现类似list的类,关于在于如何“扩充”底层数组 A A A的容量。实际上,当底层数组已满,可采用下列算法实现底层数组容量的“扩充”:
- 新分配一个容量更大的底层数组 B B B,如下图步骤
(a)所示; - 当 i = 0 , ⋅ ⋅ ⋅ , n − 1 i=0, \cdot\cdot\cdot, n-1 i=0,⋅⋅⋅,n−1时,设置 B [ i ] = A [ i ] B[i]=A[i] B[i]=A[i],其中 n n n是 A A A中元素个数,如下图步骤
(b)所示; - 设置 A = B A=B A=B,则后续底层数组 B B B代表的内存空间将承担对象数据引用(references of objects)的存储任务,如下图步骤
(c)所示; - 至此,后续新的元素将会被插入更大容量的新底层数组中。

上述算法的Python代码实现如下所示:
import ctypes
from time import time
class DynamicArray:
"""Python list类的简化版本"""
def __init__(self):
"""初始化方法,用于创建空数组"""
self._array_length = 0 # 实际元素数量
self._array_capacity = 1 # 底层数组容量
self._array = self._create_array(self._array_capacity) # 底层数组引用
def __len__(self):
"""
返回数组已存储数据的数量
:return: 当前DynamicArray实例对象的长度
"""
return self._array_length
def __getitem__(self, idx):
"""
返回索引为idx的元素
:param idx:
:return:
"""
if not 0 <= idx < self._array_length:
raise IndexError('索引越界!')
return self._array[idx]
@property
def capacity(self):
"""
返回动态数组容量
:return:
"""
return self._array_capacity
def append(self, obj):
"""
向数组尾部追加对象数据
:param obj:
:return:
"""
if self._array_length == self._array_capacity: # 如果数组容量已满
self._resize(2 * self._array_capacity) # 底层数组容量翻倍
self._array[self._array_length] = obj
self._array_length += 1
def _resize(self, capacity): # 私有工具方法
"""
将数组容量调整为capacity
:param capacity: 底层数组容量
:return: None
"""
resized_array = self._create_array(capacity) # 新的容量更大底层数组
for idx in range(self._array_length):
resized_array[idx] = self._array[idx] # 将旧数组元素拷贝至新数组
self._array = resized_array # 使用新的数组
self._array_capacity = capacity
def _create_array(self, _array_capacity): # 私有工具方法
"""
返回容量为_array_capacity的新数组
:param _array_capacity: 指定创建的底层数组容量
:return: “扩容”后的新底层数组
"""
return (_array_capacity * ctypes.py_object)() # 创建并返回新的数组
def main():
dyn_arr = DynamicArray()
for each in range(19):
dyn_arr_length = len(dyn_arr)
dyn_arr_capacity = dyn_arr.capacity
print('列表长度:{0:2d}; 数组当前容量:{1:4d}'.format(dyn_arr_length, dyn_arr_capacity))
dyn_arr.append(None)
if __name__ == '__main__':
main()
上述代码的运行结果为:
列表长度: 0; 数组当前容量: 1
列表长度: 1; 数组当前容量: 1
列表长度: 2; 数组当前容量: 2
列表长度: 3; 数组当前容量: 4
列表长度: 4; 数组当前容量: 4
列表长度: 5; 数组当前容量: 8
列表长度: 6; 数组当前容量: 8
列表长度: 7; 数组当前容量: 8
列表长度: 8; 数组当前容量: 8
列表长度: 9; 数组当前容量: 16
列表长度:10; 数组当前容量: 16
列表长度:11; 数组当前容量: 16
列表长度:12; 数组当前容量: 16
列表长度:13; 数组当前容量: 16
列表长度:14; 数组当前容量: 16
列表长度:15; 数组当前容量: 16
列表长度:16; 数组当前容量: 16
列表长度:17; 数组当前容量: 32
列表长度:18; 数组当前容量: 32
分析算法实现的上述运行结果,可知底层数组的容量的确是在每次旧数组已满的情况下翻倍增长。
需要注意的是:
- 由于需要遵循封装的思想,即使用者无需了解
DynamicArray底层的实现原理,所以诸如底层数组扩容方法_resize(),创建新的底层数组方法_create_array()均为私有方法; - 由于需要仿照
list类使得DynamicArray支持len()测长度,支持通过非负整数索引访问元素,故分别实现了__len__()和__getitem__()方法。
二、摊销法分析时间复杂度
在上述实现的和list功能相似的DynamicArray类中,我们提供了一个和list中功能一样的append()方法,下面以此方法为例介绍一种分析算法时间复杂度的策略——摊销法1。
1. 摊销法使用示例
首先,通过上述实现append()的代码你可能注意到,每次当底层数组容量已满,此时如果向底层数组插入元素时,由于需要先创建容量翻倍的底层数组,然后进行 n n n次由旧数组向新数组的拷贝操作,故此次插入成本很高;但是在此次操作之后,直至底层数组容量需要再次翻倍之前,每次调用append()插入元素只需要1次基本操作,即采用上述算法实现的append()操作,其一系列插入操作的平均时间复杂度较高。
为了分析上述append()操作的具体时间复杂度,我们介绍这样一个技巧:假设计算机是一个接收算力币来运行的机器:
- 每一个算力币可以让计算机完成一次基本操作;
- 如果一次给计算机投递的算力币大于所需其进行的基本操作次数,那么结余的算力币算作寄存在计算机中供后续使用;
- 最终,计算 n n n次
append()操作花费的平均算力币数量即为该方法的摊销时间复杂度。
基于上述假设,对于初始长度为_array_length = 0,容量为_array_capacity = 1的DynamicArray实例,我们通过下列示意图来逐步推演append()方法的时间复杂度:
- 初始长度为 _ a r r a y _ l e n g t h = 2 0 \_array\_length = 2^0 _array_length=20,容量为 _ a r r a y _ c a p a c i t y = 2 0 \_array\_capacity = 2^0 _array_capacity=20时,第 ( 2 0 = 1 ) (2^0=1) (20=1)次追加操作使用3个算力币,索引为0处结余2个算力币;
- 长度为 _ a r r a y _ l e n g t h = 2 0 \_array\_length = 2^0 _array_length=20,容量为 _ a r r a y _ c a p a c i t y = 2 0 \_array\_capacity = 2^0 _array_capacity=20时,第 ( 2 0 + 1 = 2 ) (2^0+1=2) (20+1=2)次追加操作使用3个算力币,索引为0处结余1算力币(其中一个用于底层新旧数组拷贝),索引为1处结余2个算力币;
- 长度为 _ a r r a y _ l e n g t h = 2 1 \_array\_length = 2^1 _array_length=21,容量为 _ a r r a y _ c a p a c i t y = 2 1 \_array\_capacity = 2^1 _array_capacity=21时,第 ( 2 1 + 1 = 3 ) (2^1+1=3) (21+1=3)次追加操作使用使用3个算力币,此时仅索引为0处和2处个结余1个和2个算力币,1处的2个算力币用于底层新旧数组拷贝;
- 长度为 _ a r r a y _ l e n g t h = 2 2 \_array\_length = 2^2 _array_length=22,容量为 _ a r r a y _ c a p a c i t y = 2 2 \_array\_capacity = 2^2 _array_capacity=22时,第 ( 2 2 + 1 = 5 ) (2^2+1=5) (22+1=5)次追加操作使用使用3个算力币,此时仅索引为0处和4处结余1个和2个算力币;2,3处的4个算力币用于底层新旧数组拷贝;
- 长度为 _ a r r a y _ l e n g t h = 2 3 \_array\_length = 2^3 _array_length=23,容量为 _ a r r a y _ c a p a c i t y = 2 3 \_array\_capacity = 2^3 _array_capacity=23时,第 ( 2 3 + 1 = 9 ) (2^3+1=9) (23+1=9)次追加操作使用使用3个算力币,此时仅索引为0处和8处结余1个和2个算力币;4,5,6,7处的8个算力币用于底层新旧数组拷贝;
- ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ \cdot\cdot\cdot\cdot\cdot\cdot\cdot ⋅⋅⋅⋅⋅⋅⋅
- 长度为 _ a r r a y _ l e n g t h = 2 n \_array\_length = 2^n _array_length=2n,容量为 _ a r r a y _ c a p a c i t y = 2 n \_array\_capacity = 2^n _array_capacity=2n时,第 ( 2 n + 1 ) (2^n+1) (2n+1)次追加操作使用使用3个算力币,此时仅索引为0处和 2 n 2^n 2n处分别结余1个和2个算力币; 2 n − 1 , ⋅ ⋅ ⋅ , 2 n − 1 2^{n-1}, \cdot\cdot\cdot, 2^n-1 2n−1,⋅⋅⋅,2n−1的 2 n 2^n 2n个算力币用于底层新旧数组拷贝。
由上述分析可知,前 n n n次追加操作耗费的算力币为 3 n 3n 3n个,因此:
结论1:如果一个序列底层使用初始容量
_array_capacity为1的空序列实现,且每次底层数组容量满溢后都翻倍,那么对该序列进行 n n n次追加操作的时间复杂度为 O ( n ) O(n) O(n)。

2. 数组容量指数增长
得出上述结论1的前提是:序列的底层数组在每次满溢时容量都乘以2。实际上,只要序列底层数组在每次满溢时容量都乘以一个常量(底数),即容量以指数级增长,则可证明对序列进行的追加操作,其摊销时间复杂度都是 O ( 1 ) O(1) O(1)。
3. 数组容量等差增长
可能有人会想,每次底层数组容量满溢时让其呈指数级增长会很浪费内存,因此考虑当容量满溢时让其按照等差量级增长。实际上,这种算法的时间复杂度要差很多。
我们考虑极限情况:如果底层数组每次容量满溢时仅增加1,那么追加前 n n n个元素所需要的基本操作总数(新旧数组拷贝和追加操作)为: 1 + ( 1 + 1 ) + ( 2 + 1 ) + ( 3 + 1 ) + ⋅ ⋅ ⋅ + ( n − 1 + 1 ) = n ( n + 1 ) / 2 1+(1+1)+(2+1)+(3+1)+\cdot\cdot\cdot+(n-1+1)={\left. n(n+1)\middle/ 2\right.} 1+(1+1)+(2+1)+(3+1)+⋅⋅⋅+(n−1+1)=n(n+1)/2,即此时 n n n次追加操作的时间复杂度为 O ( n 2 ) O(n^2) O(n2)。
三、列表常见操作时间复杂度
1. 非列表修改类操作
列表常见的非修改类操作及其时间复杂度如下表所示。实际上,下表所有这些操作在元组中也都支持,且其时间复杂度和列表对应操作一致,但从内存利用率来看,元组更加高效,因为元组的长度一般等于其容量。
| 操作 | 时间复杂度 |
|---|---|
len(data) |
O ( 1 ) O(1) O(1) |
data[j] |
O ( 1 ) O(1) O(1) |
data.count(value) |
O ( n ) O(n) O(n) |
data.index(value) |
O ( k + 1 ) O(k+1) O(k+1) |
value in data |
O ( k + 1 ) O(k+1) O(k+1) |
data1 == data2 |
O ( k + 1 ) O(k+1) O(k+1) |
data[j:k] |
O ( k − j + 1 ) O(k-j+1) O(k−j+1) |
data1 + data2 |
O ( n 1 + n 2 ) O({n_1}+{n_2}) O(n1+n2) |
c * data |
O ( c n ) O(cn) O(cn) |
2. 列表修改类操作
因为大多数的列表修改类操作(除data[j] = value外)都可能导致底层数组的容量扩充,所以下多数修改类的时间复杂度均为摊销时间复杂度。
| 操作 | 时间复杂度 |
|---|---|
data[j] = value |
O ( 1 ) O(1) O(1) |
data.append(value) |
O ( 1 ) O(1) O(1)2 |
data.insert(k, value) |
O ( n − k + 1 ) O(n−k + 1) O(n−k+1)2 |
data.pop() |
O ( 1 ) O(1) O(1)2 |
data.pop(k)del data[k] |
O ( n − k ) O(n-k) O(n−k)2 |
data.remove(value) |
O ( n ) O(n) O(n)2 |
data1.extend(data2)data1 += data2 |
O ( n 2 ) O(n_2) O(n2)2 |
data.reverse() |
O ( n ) O(n) O(n) |
data.sort() |
O ( n l o g n ) O(nlogn) O(nlogn) |
2.1 添加元素
Python列表中除了支持向尾部追加元素外,还支持insert(k, value)向列表任意位置k处插入值value,而此方法在执行插入(1次)前会将k右侧所有元素向右平移一个单元(共计平移 ( n − k ) (n-k) (n−k)次),从而先为待插入元素空出位置。以下是该插入算法的示意图,显然该操作的时间复杂度为 O ( n − k + 1 ) O(n-k+1) O(n−k+1)。
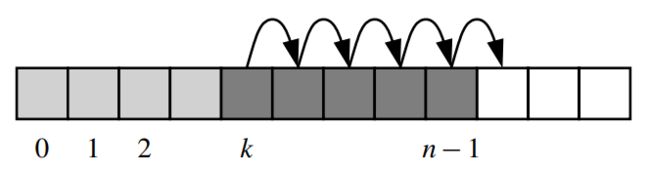
下列代码在上述DynamicArray类中实现了insert(pos, value)方法:
def insert(self, position, value):
"""
在指定位置插入值,并将后续值向右平移
:param position: 指定位置
:param value: 待插入的值
:return: None
"""
if self._array_length == self._array_capacity: # 当前底层数组容量已满
self._resize(2 * self._array_capacity) # 创建容量翻倍的底层数组
for i in range(self._array_length, position, -1): # 从最右边的元素开始移动
self._array[i] = self._array[i - 1]
self._array[position] = value # 将value插入指定位置
self._array_length += 1
2.2 删除元素
pop()
Python的list类提供了若干个从列表中删除元素的方式,其中调用pop()可以将列表最后一个元素删除。这种删除方式最高效,因为所有其他元素的位置都保持不变,显然这是 O ( 1 ) O(1) O(1)时间复杂度的操作,但需要注意的是该复杂度是经摊销后的,因为Python解释器可能会缩小底层数组的容量以节省内存。
该方法还可以接收一个非负整数作为参数,调用pop(k)会删除索引为 k k k的元素值,然后将该元素所有右边的值左移一个单元(如下图所示),这种形式的方法调用,其时间复杂度为 O ( n − k ) O(n-k) O(n−k),因为左移的操作量取决于 k k k,这也意味着pop(0)的效率最低。
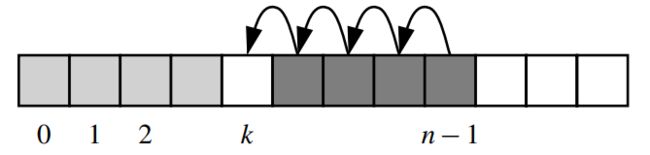
remove()
Python的list类还提供了另外一个删除用的操作remove(value),该方法可以直接指定想要删除的值(而非通过索引先找到value再对其删除),该方法会删除其找到的第一个value值,如果列表中不存在value,则抛出ValueError异常,基于此,下面是算法的Python实现。
值得注意的是,对于任何value值,该方法的时间复杂度都是 O ( n ) O(n) O(n),因为:
- 如果列表中存在
value,则对于value值,该方法的调用都分为两部分:- 从左至右找到位于 k k k处的
value,复杂度为 O ( k ) O(k) O(k); - 将位置 k k k右边所有元素向左移动一个单元,复杂度为 O ( n − k ) O(n-k) O(n−k)。
- 从左至右找到位于 k k k处的
- 如果列表中不存在
value,则算法依然要遍历列表的所有元素。
def remove(self, value):
"""
删除左起第一个出现的value,如不存在则抛出ValueError异常
:param value: 待删除的值
:return: None
"""
for i in range(self._array_length):
if self._array[i] == value: # 在动态数组中找到了待删除的value
for j in range(i, self._array_length - 1): # 将value右边每个元素左移一个位置
self._array[j] = self._array[j+1]
self._array[self._array_length - 1] = None # 协助进行垃圾回收
self._array_length -= 1
return
raise ValueError('不存在指定要删除的', value)
2.3 扩充列表
Python的列表还提供一个名为extend()的方法,该方法用于将一个一个列表中的所有元素挨个追加到另一个列表后,实际上lst1.extend(lst2)就等价于:
for element in lst2:
lst1.append(element)
该方法的时间复杂度也是经摊销后的,因为其也可能导致底层数组的容量扩增。
实际上虽然我们说extend()方法在很大程度上等价于重复调用append()方法,但使用extend()方法的效率通常要比重复调用append()方法效率高很多,原因在于:
- 调用单个
extend()方法通常比重复调用append()少了很多额外的开销,如for循环状态的保持等; - 使用
extend()方法能够是的解释器提前知道最终序列的长度,从而可能仅需一次扩容,而重复使用append()方法可能导致反复的扩容,则会引起多次新旧数组拷贝过程。
3. 创建列表类操作
Python中支持多种生成新列表的语法,如+,*和列表推导式等,虽然在绝大数情况下,这些操作的时间复杂度都是和待创建列表的长度成正比,但是就像功能类似的extend()和重复调用append()方法的关系,实际创建列表操作之间的时间复杂度也有较大差别。
例如,虽然:
squares = [k * k for k in range(1, n+1)]
可以视为:
squares = []
for k in range(1, n+1):
squares.append(k*k)
的简写,但是实验证明前者的速度要远快于后者。
类似地,通过语法[0] * n创建一个长度为n且元素初始值均为0的列表,其速度也远快于重复调用n次append()方法。
所谓摊销可以简单理解为平均之意。 ↩︎
经摊销后的时间复杂度。 ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎