nlp方向研究初步---Python爬虫学习心得
跟着导师做nlp方向的研究刚刚起步,首要任务是走一个中软杯项目的流程。此间,第一阶段是学习python爬虫相关知识,获取一些网页最好是功能性网页的数据,解析成json格式用作于后面的训练集。30+的网课学下来加上自己爬取baidu搜索信息,csdn个人博客,梨视频以及爆米花视频的实战,对Python爬虫有了些初步、浅薄的理解,于此分享一下,也记录下这一个月来的学习经历。
首先,爬虫是什么呢?网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。——摘自百度百科。概况起来是一种获取数据的手段。就我个人初学而言,无论是抓取一些文本内容抑或是视频,爬虫的大框架是一定的,具体有三:
- 进入目标url,获取response
- 解析网页,抓取你想要的数据或进行深入,进入下层你的目标url,循环抓取
- 将获得的数据保存,例如存入数据库etc
以上是写一个一般中小爬虫的常规思路,优点是思路较为清晰,每一步都可以清楚的知道自己在干什么;缺点是代码耦合度高,有一些机械的工程并不需要重复编写。所以灵活的使用一些框架,如scrapy框架等,框架能够解决重复劳动的问题,让你写一些核心代码时候更为简单。
废话多不说,下面就来析解一下我试写的几个爬虫程序。
一、爬取csdn博主的所有博客
1、首先思考写这个程序要用到什么包,开头可以import几个 ‘搭眼一看呼之欲出’ 的包。如图1
import requests
import re
import os
from pyquery import PyQuery as pq
from requests import RequestException
from config import *
import pymongorequests模块一般是必要的,使用它可以对url进行请求,返回一个响应,你可以拿到你想要的html text内同,二进制content内容等等,是第一步进入对应url的工具。
re模块为正则表达式模块,利用re模块的相关方法,可以让你更灵活的解析网页内容,拿到你所需要的数据。同时,它还是很多解析库的根本,例如pyquery、beautifulsoup都是封装好的re类。
os模块开辟文件储存,是保存数据的一种方式。
使用pyquery模块可以更为方便的解析网页数据,它和jquery的语法结构很相像,如果之前你熟悉jquery,那么pyquery对你而言会更好用一些。细微之处可以也使用re方法微调
from requests import RequestException 在try except结构时候可以用到,捕捉一些在进行url请求时候可以预知的错误,使你的程序更加健壮,不会因为一些小情况就报错结束进程。
from config import * 其中,config是我们创建的python文件,我们可以将一些参数写在config文件里,方便spider.py清晰地调用。
import pymongo 导入pymongo模块。pymongo是一个比较好用的轻量型数据库,储存数据的一种选择。
2、接下来我们缕一缕思路,该怎么爬取csdn博主文章呢?随意打开一个博主的文章页面。
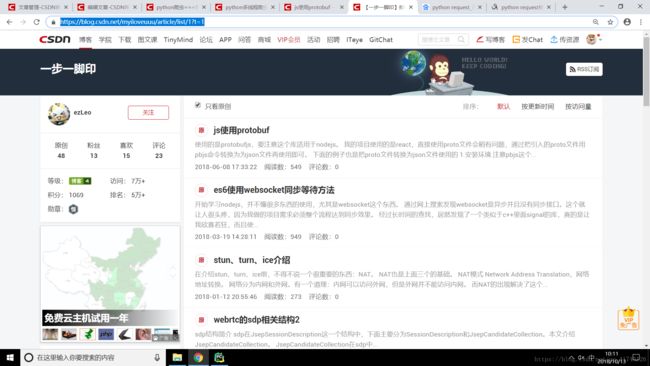
多打开几个博主的blog,会发现url规律:
'https://blog.csdn.net/{}/article/list/{}?t=1
第一个{}是博主id,第二个{}是页码数。好了,现在我们找到了两个直接参数,后续通过传入这两个参数,就可以实现爬取不同博主博客和翻页爬取的效果。
下面进入第一个步骤:请求网页,返回响应。因为csdn网页拒绝爬虫直接访问,我们要把它简单的伪装一下,加一个简易的header即可
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
def get_csdn_page(bloger, page_number):
response = requests.get(('https://blog.csdn.net/{}/article/list/{}?t=1').format(bloger, page_number), headers = header)
try:
if response.status_code == 200:
html = response.text
return html
return None
except RequestException as a:
print(a)
完成了第一步,我们拿到了html = response.text,就拿到了网页上所有数据,接下来就要进行解析,找到我们想要的有效数据。
观察网页结构 https://blog.csdn.net/myiloveuuu/article/list/1?t=1 
Chrome浏览器邮件点击检查,可以看到博客的所在的div标签对非常清晰,他们在 div.article-list 的大div对里,这里直接对div.article-list copy selector,再选择其article-item-box类,定位到我们要的文章块,同时利用Pyquery解析,再以一个循环拿到我们要的各种文章属性。这里,像item('a').attr('href')这样的语句,是pyquery中选择元素,css样式从而抓取到对应内容,有时候标签过大或者过小都会对你抓取的内容产生影响,最好反复试验几次。
有关于pyquery中一些方法规则的使用,可以参考这个链接 https://www.jianshu.com/p/0194db905497
def parse_csdn_page(html):
doc = pq(html)
items = doc('#mainBox > main > div.article-list .article-item-box').items()
for item in items:
product = {
'url': item('a').attr('href'),
'iscreate': item('span').text().strip(),
'content': item('.content').text().strip(),
'title': item('h4').text()[1:].strip()
}
url = product.get('url')
if(get_csdn_detail(url)):
parse_csdn_detail(get_csdn_detail(url))
if (product):
save_to_mongo(product)
else:
break
拿到了文章大略信息,我们还不满足,想进入每一个文章链接,爬取文章全部内容,所以我在后面编写了parse_csdn_detail (html) get_csdn_detail(url)这两个方法去拿到文章本身,其原理是类似的。
def get_csdn_detail(url):
response = requests.get(url, headers=header)
try:
if response.status_code == 200:
html = response.text
return html
return None
except RequestException as a:
print(a)
def parse_csdn_detail(html):
doc = pq(html)
items = doc('#article_content > div.markdown_views').items()
for item in items:
content = {
'article': item('.markdown_views') .text().strip().replace('\n', ' ')
}
save_to_mongo2(content)
items = doc('#article_content > div.htmledit_views').items()
for item in items:
content = {
'article2': item('.htmledit_views').text().strip().replace('\n', ' ')
}
save_to_mongo2(content)
csdn有个比较刁钻的地方,它的博主文章主页的结构会有不同,目前我见到了三种版本,文章块对应的div标签对主要有两种

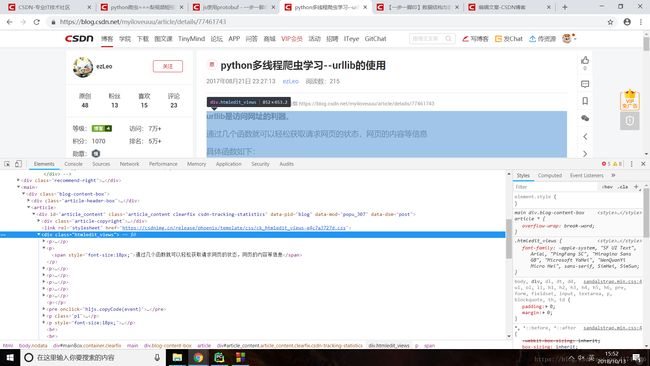
如上图所示连个文段的大DIV标签对是不同的,要特别注意这个坑。我第一次测试的时候,只能爬到一部分的文章,代码段也没有报错,找了半天想到了可能是网页结构的细微变化,导致 items = doc('#article_content > div.markdown_views').items() 只能有定位到一部分网页的文章块。
可以看到,几段代码块中都调用了save_to_mongo或save_ton_mongo2函数,这是将拿到的数据存入数据库中的操作。
这样,通过外层的循环,遍历博客页中的每一条文章的基本信息('url', 'iscreate', 'content' 'title'),将4项信息存入数据库中,同时对于每一条url进行请求,爬取文章全部内容,并存入数据库中,如果一页被爬完,则利用循环执行翻页操作。实现个人博客的全部爬取。
全部代码如下:
import requests
import re
import os
from pyquery import PyQuery as pq
from requests import RequestException
from config import *
import pymongo
i = 1
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
def get_csdn_page(bloger, page_number):
response = requests.get(('https://blog.csdn.net/{}/article/list/{}?t=1').format(bloger, page_number), headers = header)
try:
if response.status_code == 200:
html = response.text
return html
return None
except RequestException as a:
print(a)
def parse_csdn_page(html):
doc = pq(html)
items = doc('#mainBox > main > div.article-list .article-item-box').items()
for item in items:
product = {
'url': item('a').attr('href'),
'iscreate': item('span').text().strip(),
'content': item('.content').text().strip(),
'title': item('h4').text()[1:].strip()
}
url = product.get('url')
if(get_csdn_detail(url)):
parse_csdn_detail(get_csdn_detail(url))
if (product):
save_to_mongo(product)
else:
break
def get_csdn_detail(url):
response = requests.get(url, headers=header)
try:
if response.status_code == 200:
html = response.text
return html
return None
except RequestException as a:
print(a)
def parse_csdn_detail(html):
doc = pq(html)
items = doc('#article_content > div.markdown_views').items()
for item in items:
content = {
'article': item('.markdown_views') .text().strip().replace('\n', ' ')
}
save_to_mongo2(content)
items = doc('#article_content > div.htmledit_views').items()
for item in items:
content = {
'article2': item('.htmledit_views').text().strip().replace('\n', ' ')
}
save_to_mongo2(content)
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print('保存到MongoDB成功', result)
except Exception:
print('存储到MongoDB时发生错误', result)
def save_to_mongo2(result):
try:
if db[MONGO_TABLE2].insert(result):
print('保存到MongoDB成功', result)
except Exception:
print('存储到MongoDB时发生错误', result)
def main():
for i in range(1, 20):
parse_csdn_page(get_csdn_page('myiloveuuu',i))
if __name__ =='__main__':
main()此上代码也有很多需要改进的地方,如果使用selenium模块模拟操作,则可以使用
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_TSearchForm > div.search-button > button'))) input.send_keys(KEYWORD) submit.click()
模拟点击“下一页”实现更好的翻页操作,而不是像我这里简化省事,用for循环去做,直到获取不了相应内容,则break掉。
其次是
'article': item('.markdown_views') .text().strip().replace('\n', ' ')
'article2': item('.htmledit_views').text().strip().replace('\n', ' ')
这两块明显耦合,事实上,对于item来讲,这里一共有两个class,不过用or并没有作用,没想出好方法能够提供析取选择,于是分开写了两遍。很有改进的地方。
二、爬虫爬取梨视频
上面有提及,编写爬虫程序的思路大抵相同,就算不使用框架,也有一种惯用的思路贯穿其中。
- 进入目标url,获取response
- 解析网页,抓取你想要的数据或进行深入,进入下层你的目标url,循环抓取
- 将获得的数据保存,例如存入数据库etc
爬取视频和爬取文本网页区别不大,区别是一些视频的真实url是隐藏的,不会乖乖地束手就爬。但是相对的,拿到视频真实url后,下载视频并保存相对于文本来说并不是很复杂。下面是我爬取梨视频中社会视频的实战。
代码前段的设置header、获取url相应与之前相似。区别是这次的解析使用了beautifulsoup解析库,关于beautifulsoup的一些方法使用,可以参考 https://blog.csdn.net/love666666shen/article/details/77512353
代码如下所示,注释标注在代码里:
import requests
import re
from bs4 import BeautifulSoup
import urllib.request
#用header伪装浏览器
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
#试图爬取梨视频社会视频:http://www.pearvideo.com/category_1
def downloadvideo(url):
html = requests.get(url,headers = headers)
# 解析url
soup = BeautifulSoup(html.text, 'lxml')
# 观察到视频信息集中于vervideo-bd的div中,通过循环拿到有用的id 和 title
for video in soup.select('.vervideo-bd'):
id = video.select('a')[0]['href']
title = video.select('.vervideo-title')[0].text
# 单个视频的详情页
new_url ='http://www.pearvideo.com/{}'.format(id)
resp = requests.get(new_url, headers = headers).text
req = re.compile(r'srcUrl="(.*?)"')
#拿到视频真正url
url_video = re.findall(req, resp)[0]
global i
print('正在下载第{}个小视频'.format(i), title, url_video)
savevideo(url_video)
i+=1
def savevideo(url):
global i
# 保存视频
urllib.request.urlretrieve(url,'F:\pearvideo store\{}.mp4'.format(i))
def loadmorevideo():
n= 12
while True:
url = 'http://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=1&start={}&mrd=0.7947432069877813&hotContIds=1448376,1448374,1448379'.format(n)
downloadvideo(url)
n+=12
# 观察到加载更多时url start={}处数字每次叠加12
if n>48:
return
def main():
loadmorevideo()
if __name__ == '__main__' :
i=1
main()
经此一个月的学习,了解了一下爬虫的相关原理与基础知识,巩固了一下Python语法,初步掌握了一些基本解析库的使用,获取一些防护不强的网页的文本,图片,视频还是可以的。总结这段经历后,前路仍是漫漫,向着更远的地方前行吧!