一天一个统计小知识——常见的几种概率分布
本文聊一下生活中常见的几种概率分布
一、二项分布
(1)来源:在说二项分布前,先介绍一下0-1分布。其实0-1分布就是n=1下的二项分布,即只进行一次事件试验,该事件发生的概率为p,不发生的概率为1-p。二项分布就是独立进行n次实验,恰好成功m次的概率。
(2)具体表达:用 X X X~ B ( n , p ) B(n,p) B(n,p)表示变量X服从二项分布。
P ( X = m ) = C n m × p m × ( 1 − p ) ( n − m ) P(X=m) = C_{n}^{m}×p^m×(1-p)^{(n-m)} P(X=m)=Cnm×pm×(1−p)(n−m)表示将实验重复n次,然后恰好成功m次的概率。
(3)性质:期望 E ( X ) = n p E(X) = np E(X)=np, 方差 V a r ( X ) = n p q Var(X) = npq Var(X)=npq
(4)生活中的二项分布: 保险公司的收入。假设有10000个人购买了公司的保险,其中保费为100元。如果发生意外,那么公司将赔偿10000元。假设每个人发生意外的概率是0.005,求公司的利润情况?
利润 = 收入 - 成本
收入 = 10000 * 100
成本需要求出大概会有多少个人发生事故,由于每个人是否发生事故这件事是相互独立,所以10000个人里面多少个人发生事故服从二项分布 X X X~ B ( 10000 , 0.005 ) B(10000, 0.005) B(10000,0.005). 求得期望 = n*p = 50人,所以:
成本 = 发生事故人数 * 赔偿金额 = 50 * 10000 = 500000
利润 = 收入 - 成本 = 50万
不过这也只是期望收入,真实收入会围绕这个均值有所波动
下面用python对二项分布进行一个模拟。
import numpy as np
import matplotlib.pyplot as plt
n = 100
p = 0.333
q = 1-p
size = 100000
X = np.random.binomial(n,p,size) # 生成100000个服从B(100, 0.333)的点
# 计算概率
p_x = {}
X.sort()
for i in X:
if i not in p_x:
p_x[i] = 1
else:
p_x[i] += 1
plt.bar(list(p_x.keys()), np.array(list(p_x.values()))/size, color='k')
print('np=%f, 均值=%f'%(n*p, np.mean(X)))
print('npq=%f, 方差=%f'%(n*p*q, np.std(X)**2))
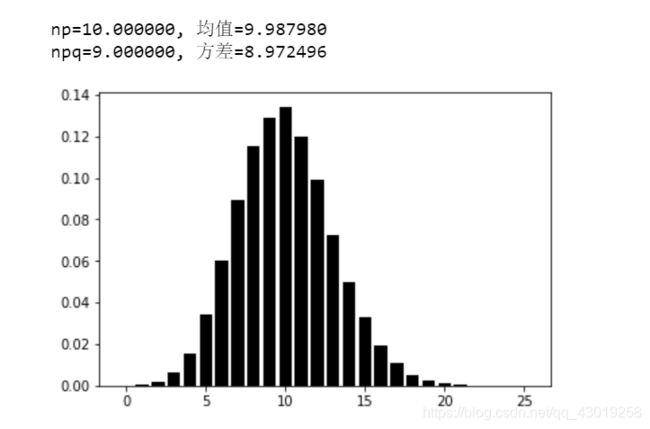
图形大概就是长这样了(跟正态分布有点像?后面会说到两者的关系),用numpy直接算出来的均值和方差跟用经验公式原出来的基本相同。
二、几何分布
(1)来源:几何分布跟二项分布有点类似,也是独立重复进行n次实验,但是这里的m不是恰好成功m次,而是实验m次才获得第一次成功的概率,换言之,就是前m-1次都失败,第m次才成功的概率。
(2)具体表达: X X X~ G E ( p ) GE(p) GE(p)表示X服从概率为p的几何分布。
P ( X = m ) P(X=m) P(X=m) = p q m − 1 pq^{m-1} pqm−1
(3)性质:期望 E ( X ) = 1 / p E(X) = 1/p E(X)=1/p, 方差 V a r ( X ) = q / p 2 Var(X) = q/p^2 Var(X)=q/p2
(4)生活中的几何分布:假设上班路上会经过10个红绿灯,每次在路口碰到绿灯的概率是0.5,那么前9个都是红灯,最后一个是绿灯的概率是多少?
概率 P ( x = 10 ) = 0.5 ∗ ( 1 − 0.5 ) 9 P(x=10) = 0.5 * (1-0.5)^9 P(x=10)=0.5∗(1−0.5)9 = 0.0009765625
下面用python对几何分布进行一个模拟。
p = 0.10
q = 1- p
size = 100000
X = np.random.geometric(p,size)
p_x = {}
X.sort()
for i in X:
if i not in p_x:
p_x[i] = 1
else:
p_x[i] += 1
plt.bar(list(p_x.keys()), np.array(list(p_x.values()))/100000, color='k')
print('np=%f, 均值=%f'%(1/p, np.mean(X)))
print('npq=%f, 方差=%f'%(q/(p**2), np.std(X)**2))

三、泊松分布
(1)**来源:**泊松分布是用来求某个时间范围内,发生某件事情m次的概率是多大。它是二项分布的极限情况(n趋于无穷大)。二项分布也是求某件事情发生m次的概率,那么它跟泊松分布的区别在哪里呢?其实主要区别在于二项分布是给定实验次数n的情况下,求发生m次的概率。而泊松分布是求某一段时间内发生m次的概率,它们主要区别在于二项分布是知道了实验次数,而泊松分布并不知道,某一段时间内,实验次数并不清楚,所以说泊松分布是次数接近无穷大的时候的二项分布。
(2)具体表达:用 X X X~ P ( λ ) P(λ) P(λ)表示X服从泊松分布。
P ( X = m ) = e − λ λ m / m ! P(X=m) = e^{-λ} λ^{m} / m! P(X=m)=e−λλm/m! 表示某段时间内事件发生m次的概率。
(3)**特征:**期望 E ( X ) = λ E(X) = λ E(X)=λ, 方差 V a r ( X ) = λ Var(X) = λ Var(X)=λ
(4)**生活中的泊松分布:**假设某段事件内,汽车经过某路口发生事故的平均次数 ( λ ) (λ) (λ)为0.001,请问事故发生两次的概率?
P(X=2) = 4.995002499166875e-07
下面用python对泊松分布进行一个模拟。
fig = plt.figure(figsize=(10,10))
n = 10
p = 0.10
size = 100000
X = np.random.binomial(n,p,size)
p_x = {}
X.sort()
for i in X:
if i not in p_x:
p_x[i] = 1
else:
p_x[i] += 1
ax1 = fig.add_subplot(2,2,1)
plt.bar(list(p_x.keys()), np.array(list(p_x.values()))/size, color='k')
plt.title('binomial, n=10')
lambda_ = n*p
size = 100000
X = np.random.poisson(lam=lambda_, size=size)
p_x = {}
X.sort()
for i in X:
if i not in p_x:
p_x[i] = 1
else:
p_x[i] += 1
ax1 = fig.add_subplot(2,2,2)
plt.bar(list(p_x.keys()), np.array(list(p_x.values()))/size, color='k')
plt.title('poisson')
n = 100
p = 0.10
X = np.random.binomial(n,p,size)
p_x = {}
X.sort()
for i in X:
if i not in p_x:
p_x[i] = 1
else:
p_x[i] += 1
ax1 = fig.add_subplot(2,2,3)
plt.bar(list(p_x.keys()), np.array(list(p_x.values()))/size, color='k')
plt.title('binomial, n=1000')
lambda_ = n*p
X = np.random.poisson(lam=lambda_, size=size)
p_x = {}
X.sort()
for i in X:
if i not in p_x:
p_x[i] = 1
else:
p_x[i] += 1
ax1 = fig.add_subplot(2,2,4)
plt.bar(list(p_x.keys()), np.array(list(p_x.values()))/size, color='k')
plt.title('poisson')
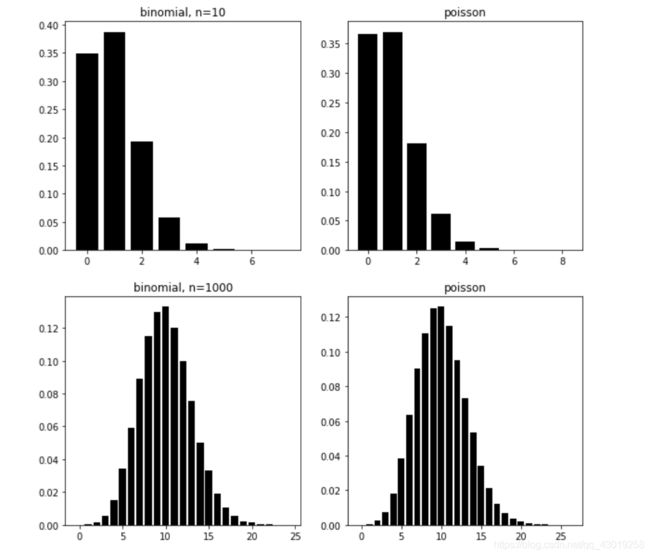
四、正态分布
(1)来源: 当n很大时,可以用正态分布近似二项分布,跟泊松分布很像?其实最主要的区别在于不管是几何分布、二项分布还是泊松分布,它们都是离散分布,即m只能取整数,而正态分布是连续分布,m的取值范围没有限制。
(2)具体表达: 用 X X X~ N ( μ , σ ) N(μ, σ) N(μ,σ)表示X服从均值为 μ μ μ,方差为 σ σ σ的正态分布。
P ( X = x ) = f ( x ) = 1 2 π σ exp ( − ( x − μ ) 2 2 σ 2 ) P(X=x) = f(x)=\frac{1}{\sqrt{2 \pi} \sigma} \exp \left(-\frac{(x-\mu)^{2}}{2 \sigma^{2}}\right) P(X=x)=f(x)=2πσ1exp(−2σ2(x−μ)2) 表示X取x得概率。
(3)特征: 期望 E ( X ) = μ E(X) = μ E(X)=μ,方差 V a r ( X ) = σ Var(X) = σ Var(X)=σ
(4)生活中的正态分布: 人的身高基本就是服从正态分布。
下面用python对泊松分布进行一个模拟。
X = np.random.normal(0,1, size=size)
plt.hist(X,bins=100,normed=True,histtype='step',color='k')

思考一个问题,个人财富服从正态分布吗或者说平均收入能衡量大部分的收入水平吗?
事实上,个人财富并不服从正态分布,个人的财富分布具有严重的偏态,平均收入并不能较好的衡量大部分人的收入水平,其分布大概长这样:
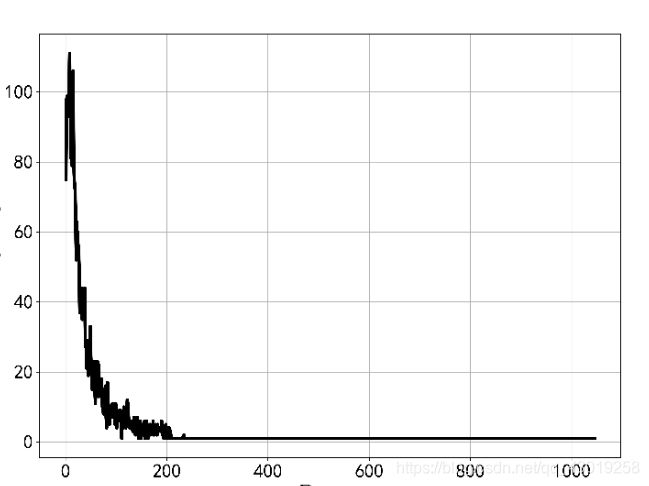
横轴是人数(随便画的,量纲不具有参考性),纵轴是收入。极少数人占据了绝大部分财富,我们管这叫“二八定律”或者是“马太效应”。事实上这种分布叫做“幂律分布”。