慕课心得---python网络爬虫及技术
1.环境搭建:pycharm 也安装了anocode便于后期数据分析
2.搭建web网站;自己编的客户端来访问。
Flask安装-----自己写一个页面
通过urllib requests来访问该页面----之后可以看到爬取的内容
3.web网站的get方法:客户端发送------>服务器获取
客户端:编码---发送 urllib.request.urlopen(url)来访问服务器返回的数据
flsk.requeddst.args.get("字段名") 服务器获取到客户端的
web网站的post方法:【可发送大量数据 相比get】
flsk.request.form.get("字段名") 服务器获取到客户端的
4.web下载文件:客户端通过URLopen()打开网址,其read方法读取下来,open()打开要保存的地址,write()保存到指定路径。
5.web上传文件:
服务器端 获取上传名称flask.request.values.get();获取上传的二进制数据flask.request.get_data().
客户端 打开要上传的文件并读取其内容,设置文件头信息 用headers字典,通过URLopen传到服务器端
6.web学生信息管理程序来练习:
客户端:创建student对象,增删改查的sql语句在服务器端-----这里只写入口方法
服务器:数据库放在服务器端。openDB来打开数据库,之后通过游标对数据看进行增删改查操作,根据客户端的操作值来匹配 决定调用哪个方法。通过json对象将内容传到客户端
7.正则表达式:
import re;//引入包
reg=r"\d"r表示正则表达式的原始数据
re.search(reg,st)会在st中找出符合reg的内容
[]匹配里面任意一个,^在里面表示“否定”
\b表示单词的结尾
\s匹配任何空白符
8.html文档结构和文档树:BeautifulSoup是一个函数库,BeautifulSoup(content,"lxml")这就是一个BeautifulSoup对象,打点调用prettify就是吧content的BeautifulSoup对象整理好 打印出来-----就是文档结构类型。
9.BeautifulSoup的函数来查找元素:将网页代码转载成BeautifulSoup对象,BeautifulSoup对象有find/find_all方法 其中find_all方法功能强大,因为find方法只返回符合条件的第一个,而厚重返回的是列表
找元素find(name【=None时表示匹配所有的】,attrs={里面是键值对})
找元素的属性值find(元素[属性名])
获取文本值元素.text
高级搜索:可以设置自己查找的函数
获取元素父节点:tag.parent
获取元素的直接子节点:tag.children
获取元素的子孙节点:tag.desentent
获取节点的兄弟节点:tag.next_sibling / tag.previous_sibling
使用css语法查找:类似jq选择器
二、深入
1.网页爬取的遍历方法(多个网页)
树: 递归、深度优先---栈 、广度优先---队列
图:深度优先----spi()方法----如果链接范文过,就加到urls里 每次判断当前url,不在urls中就继续访问 找到里面还有url 就spi()方法继续----最后直至访问玩跳出
广度优先-----队列的每个点组成一个数组,数组的的每个点(对每个点一个一个访问与其相邻的点)访问过就出站,数组为空时 就已经访问完了。
2.python实现多线程:效率高,可靠性高
当一个数据爬取时间过长时,其他数据的爬取不受影响
t=Thread();t.start()就启动了一个线程
t.setDaemon(FALSE)设置这个线程是后台的线程,即当主程序结束运行时线程还可以继续运行
3.复杂爬取:多网站.....保存到数据库.....
URLopen().read().decode()------创建bs4对象;soup.select(tagName)来获取标签的内容;request.urlretrive(url,保存的图片名称) 将url的图像保存下来;-----当这里有许多图片需要下载时,不能一个一个下载,得同步来提高效率:
解决:设置图片的下载时间 URLopen(url,多少秒),在这段时间内没有下载 下放弃下载;设置下载 程为与主线程不同的子线程(更可取)
4.request.urljoin(a,b)将url作出绝对地址
open(url)打开要保存的地址
write(data)将数据写入对应地址
有许多图片要下载时,每个图像的url不调用doenload()直接下载,而是将其创建一个线程:t=Threading.Thread(target=download,args=(download方法的参数));t.start(),threads.append(t)这句为了等待所有线程都完毕 threads中每一个t:t.join()
三、scrapy框架:访问过的他不会再访问
1.框架的安装:是python中的一个框架,需要很多库的支持
2.创建项目:class MySpider(scrapy.Spider){name="自定义";
def start_requests(self){
yield//返回genrator对象,直到完了所有再执行下一步 ---创建Requests类 scrapy.Request(url=url;callback=self.parse)//访问url网页,回调另一个方法}
def parse(self,response){response.body.decode()//变成了字符串来查看}
3.xpath()方法查找:
from scrapy import Selector//Selector对象可以调用xpath().extract()可以提取出来
s=Selector(text=htmlText)
//全文档搜索
4.scrpy爬取与存储
管道:将数据爬取和数据存储分开做,是异步的
四.Selenium(是一个浏览器,功能强大)----有些动态的、JavaScript的,如果直接在代码中是没有的---所以引入了Selenium
1.使用:
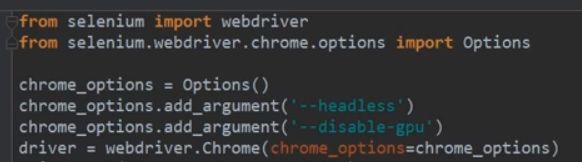
driver.get("url");
result=driver.find_element_by_xpath("").text//找不到元素时会抛出异常,最好写在try--catch中
driver.close()
2.模拟键盘输入:元素.send_keys()
模拟鼠标点击:找到点击的元素,元素.click()
3.爬取有ajax控制的:通过获取来拿,而不是直接在网页上找。调用方法后在进行值的获取
五.Django是Python的Web开放框架