Python Code :不同Json文件的数据挖掘、清洗、反写
从Python爬虫爬下来的网页数据,是一堆乱码(Json格式),如何在这一对乱码中找到自己想要的数据,或者说,如何在多个文件中整合出自己想要的新的内容,然后用一个Excel表格来表示呢?
本博客通过记录一个实际问题的解决,阐述相关代码。
问题:
1、从网页上爬取下的Json格式文件包含商品名字、价格,准确找到该两项目,通过csv表格完成一个数据可视化、
2、假设网页上数据小部分有更新,重新爬取到Json格式文件;
3、挖掘出哪些变动;
4、两者规则不一样的情况下再次做数据可视化、并且和前一次做一个对比;
5、重要信息(新价格)的数据清洗、覆盖。
Json文件层次:
data_deal文件下有data文件夹和Js文件夹:其中data放置旧信息;Js放置新信息;
data文件夹下面有Comb文件(对应旧的名字、价格);Prop文件(对应商品的系列号);
一、代码思路流程图:

二、代码解释:
# -*- coding: utf-8 -*-
import numpy
import json
import csv
import os
import os.path
import shutil
import sys
import csv
reload(sys)
sys.setdefaultencoding( "utf-8" )
count_the_right_file=0
dets=[]
sum_prop=0
sum_comp=0
num_prop=0
num_comp=0
wrong_files=[]其次:定义了一些相关的列表:wrong_file用于存放数据发生改动的data文件夹中的json文件名;
def getDirList(p):
p=str(p)
if p=="":
return []
if p[-1]!="/":
p=p+"/"
a=os.listdir(p)
return a
js_file_names=[]
js_file_names=getDirList("/home/suanyi3/data_deal/js")
这一步就是做一个文件夹路径下所有文件名的整理,该操作之后,js_file_names这个列表就会按顺序存放/home/suanyi3/data_deal/js文件下的所有文件名;
for file in range(len(js_file_names)):
js_file_addr="/home/suanyi3/data_deal/js/"+js_file_names[file]
compare1=[]
compare2=[]
te=0
de=0
#########################################<<>>##########################################
try:
with open(js_file_addr) as f:
data=json.load(f)
#print data
#print data["a"]["bn"]
for i in range(len(data["f"])):
compare1.append(data["f"][i]["be"])
compare1.append(data["f"][i]["bh"])
#print compare1
file_index=(data["a"]["bn"])
file_index=file_index.split('_')
print file_index
bomb_addr="/home/suanyi3/data_deal/data/comb/"+ file_index[0] + ".js"
prop_addr="/home/suanyi3/data_deal/data/prop/"+ file_index[0] + ".js"
except IndexError:
pass
##########################################<<>>###################################
try:
with open(prop_addr) as ff:
prop_data=json.load(ff)
except IOError,IndexError:
pass
if(data["a"]["j"]==prop_data["KEY_SERIES"]["SeriesFullName"]):
de=1
else:
de=0
sum_prop=sum_prop+de
num_prop=num_prop+1
print count_the_right_file
###########################################<<>>##################################
try:
with open(bomb_addr) as ff:
com_data=json.load(ff)
for i in range(len(com_data)):
compare2.append(com_data[i]["CombName"])
compare2.append(com_data[i]["Price"])
#print compare2
except IOError,IndexError:
pass
这一步很关键:
首先解释一下为什么要用try--except结构:因为如果不用,读取文件夹如果不存在的话就很尴尬了,会报错
其次解释一下我发现的挖掘数据的规则:js文件下的字典“a”键下面的子键“bn”存放有Comb文件和Prop文件中文件的名字,秩序要做一个split把“_”下划线分开就是对应的文件名字;比如:
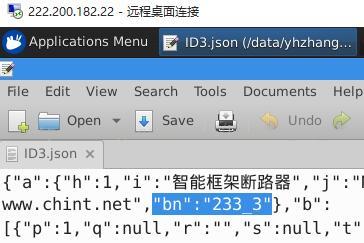
我们再去Comb文件夹寻找233.js这个文件:

两者的系列号、价格、名字是对应的→然而我为什么说是对应的?对应着什么?
我们来看:
这面有另外一个规则:js文件夹下面的"f"键下面的“be”、“bh”键分别对应Comb文件下面的CombName、CombPrice(旧数据名字、价格)如下所示:


if(len(compare2)>=len(compare1)):
length=len(compare1)
mis_length=len(compare2)
tell=compare2
else:
length=len(compare2)
mis_length=len(compare1)
tell=compare1
for j in range(length):
count=[]
if(compare1[j]==compare2[j]):
count.append(1)
else:
count.append(0)
# if(count==len(compare2)-1):
# print "rightrightrightright!!!"
# te=1
# else:
# te=0
for j in range(0,length,2):
if(compare1[j+1]!=compare2[j+1]):
te=te+1
else:
te=te+0
body=(js_file_names[file],file_index,data["a"]["j"],prop_data["KEY_SERIES"]["SeriesFullName"],de,com_data[0]["CombName"],compare1[j],compare1[j+1],compare2[j],compare2[j+1],bool(compare1[j+1]==compare2[j+1]),bool(compare1[j]==compare2[j]))
dets.append(body)
if((mis_length-length)>0):
for i in range(length,(mis_length-length),2):
body=(js_file_names[file],file_index,data["a"]["j"],prop_data["KEY_SERIES"]["SeriesFullName"],de,com_data[0]["CombName"],tell[i],tell[i+1],"missssssss","misssssssss",0)
dets.append(body)
dets.append(body)
这段代码主要是做在对于compre1、compare2列表下的价格进行比对,长度不一样的话,用mis_length来表示长,用length表示短者;
然后进行比较,如果一一对应,te=0恒成立;
如果又不一样的话我们马上把te+1使之大于0;
紧接着作如下操作:
if (te>=1 and de==1):
wrong_files.append(bomb_addr)
很简单:我们用dets表来储存所有的要整理的参数(新旧价格名字系列号de、te)用wrong_files来存储不对应的文件名字;
#######################################<<>>##############################################
headers=["Js_File","prop_File","New_Series_Name","Old_Series_Name","The_Same?","ID","compare1_CombNames","compare1_Price","compare2_CombNames","compare2_Price","All_The_Same?"]
with open('temp4.csv','w') as fff:
fff_csv=csv.writer(fff)
fff_csv.writerow(headers)
fff_csv.writerows(dets)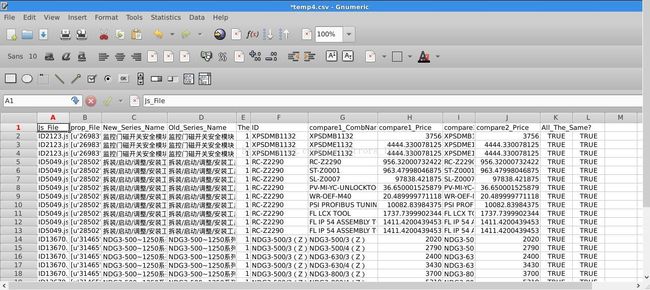

########################################<<>>##########################################
print wrong_files
print len(wrong_files)
def moveFileto(sourceDir,targetDir):
shutil.copy(sourceDir,targetDir)
targetDir="/home/suanyi3/data_deal/ooo/"
for wrong_file in wrong_files:
moveFileto(wrong_file,targetDir)
通过它,我们可以复制需要变动的Comb文件夹下面的文件Copy到我们的targetDir路径下;如下图完成复制:

我们可以看到,并不是所有复制过来,而是有了变动的价格对应的js文件我们才把他拿过来,这一部工作成功完成!!
三、后续工作:
接下来是我们的后续工作,我们要把真实的数据反写回去,另外开一个test.py脚本,重新写些代码:
reload(sys)
sys.setdefaultencoding( "utf-8" )def store(measurement,addr):
new_js="/home/suanyi3/data_deal/oo/"+addr+".json"
with open(new_js,'w') as f:
jsonStr=json.dumps(measurement,ensure_ascii=False)
f.write(jsonStr)
多加一个函数:def store(measurement,addr):
看完后面的 代码你会发现:这个函数是这整个Python脚本的关键,他可以在json文件夹中特定位置写进字典里面对应的值;
而其他的代码也大同小异:
def getDirList(p):
p=str(p)
if p=="":
return []
if p[-1]!="/":
p=p+"/"
a=os.listdir(p)
return a
def store(measurement,addr):
new_js="/home/suanyi3/data_deal/oo/"+addr+".json"
with open(new_js,'w') as f:
jsonStr=json.dumps(measurement,ensure_ascii=False)
f.write(jsonStr)
js_file_names=[]
js_file_names=getDirList("/home/suanyi3/data_deal/js")
#print js_file_names
for file in range(len(js_file_names)):
js_file_addr="/home/suanyi3/data_deal/js/"+js_file_names[file]
compare1=[]
compare2=[]
te=0
de=0
#########################################<<>>##########################################
try:
with open(js_file_addr) as f:
data=json.load(f)
for i in range(len(data["f"])):
compare1.append(data["f"][i]["be"])
compare1.append(data["f"][i]["bh"])
#print compare1
file_index=(data["a"]["bn"])
file_index=file_index.split('_')
print file_index
ooo_addr="/home/suanyi3/data_deal/ooo/"+ file_index[0] + ".js"
except IndexError:
pass
#########################################<<>>#####################################
try:
with open(ooo_addr) as ff:
ooo_data=json.load(ff)
for i in range(min(len(ooo_data),len(data["f"]))):
ooo_data[i]["CombName"]=data["f"][i]["be"]
ooo_data[i]["Price"]=data["f"][i]["bh"]
print ooo_data[i]["CombName"],ooo_data[i]["Price"]
store(ooo_data,file_index[0])
except IOError,IndexError:
pass
以上代码、思路为作者一行行亲手编写,
解决:不同Json文件的数据挖掘、清洗、反写;数据量:百万级;时间:4~5s;也乐于跟大家分享,按着这个步骤往下是可以完成属于你自己的工程项目的。当然,我也允许你的懒惰,如果需要源代码,请在下面留下你的邮箱地址。