手把手教会使用YOLOv5训练VOC2007数据集
1. 运行环境配置
本次使用的电脑系统是windows7。
使用YOLOv5训练自己的数据集,首先需要搭建YOLOv5的环境,包括安装Python环境、安装相关Python库、下载YOLOv5 github项目,具体操作方法请参照本人另一篇博文: [YOLOv5环境搭建]。
2. 下载模型文件
参考: [YOLOv5环境搭建],里面有下载模型文件的方法。
这里也提供CSDN下载链接:yolov5m.pt、yolov5l.pt、yolov5x.pt、yolov5s.pt、yolov3-spp.pt。这里5个文件代表5种不同的模型结构,例如yolov5m.pt中m表示中等大小的模型。
本次以yolov5s.pt为例进行案例分析,因此读者可以先只下载yolov5s.pt。因为yolov5s.pt是这几个中最小的一个模型,方便我们把流程跑通,之后读者想尝试更大的模型时,只需将yolov5s.pt替换成更大的模型文件即可。
为了方便后面的训练,可以将下载的模型文件拷贝到yolov5\weights文件夹中,如下图所示:
3. 数据集准备
本次以VOC2007为例进行案例分析,如果读者有自己的数据集,也可以按如下的方式准备后进行训练。
VOC数据集下载地址: [ Pascal VOC Dataset Mirror ],该网址是一个镜像网站,所有速度还是可以的。这里推荐使用迅雷下载,速度可以达到几M、甚至几十M。

下载 VOC2007下面 [Train/Validation Data (439 MB)]和[Test Data With Annotations (431 MB)]这两个文件即可。
为了方便读者,也提供百度网盘下载地址: [ VOC2007数据集 ] (提取码:7sjo)。
下载完成后解压两个下载的文件。注意:这里解压的时候选择 [ 解压到当前文件夹 ],两个压缩文件会合并到一个文件夹 [ VOCdevkit ]中。
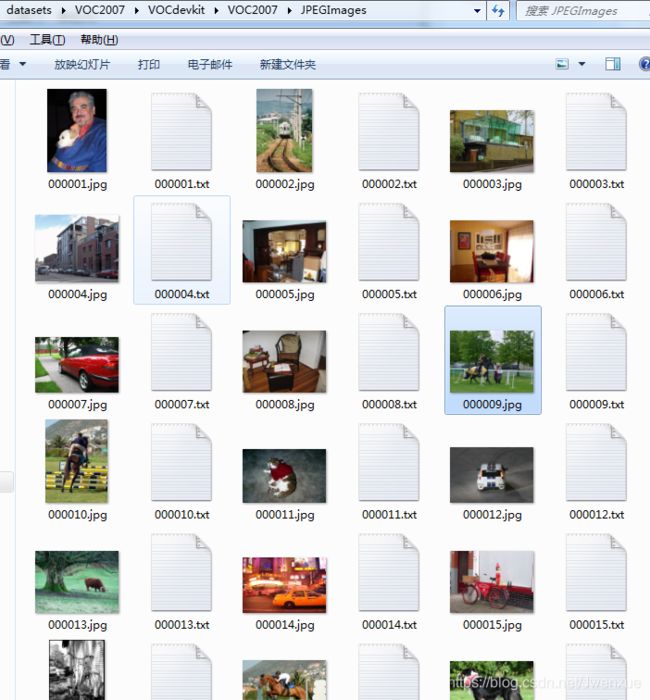
解压完成后需要将VOC格式的标注文件转换成YOLO标注格式的文件,转换过程请参考:[ VOC标注格式转换成YOLO标注格式 ]。转换完成后会生成一个[labels]的文件夹和三个txt文件[ 2007_train.txt、2007_val.txt、2007_test.txt],文件夹里面是转换后的YOLO标注格式的文件,我们将里面所有txt文件复制到 [ VOCdevkit\VOC2007\JPEGImages ]中。为了防止有人不会转换,这里提供转换后的 [labels] 的文件夹: [ labels-YOLO格式标注文件.7z ](提取码:uu1i)。最终如下图所示:
2007_train.txt、2007_val.txt、2007_test.txt这三个文件后面训练的时候会用到,先别急!!!
4. 修改YOLOv5模型配置文件
4.1 修改voc.yaml文件
该文件位于:yolov5\data目录下,文件内容如下:
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Download command: bash ./data/get_voc.sh
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../VOC/images/train/ # 16551 images
val: ../VOC/images/val/ # 4952 images
# number of classes
nc: 20
# class names
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']读者只需要将11行和12行改成2007_train.txt和2007_val.txt文件的路径即可,可以是相对路径,也可以是绝对路径,例如修改如下:
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC/
# Download command: bash ./data/get_voc.sh
# Train command: python train.py --data voc.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /VOC
# /yolov5
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: F:\AI\datasets\VOC2007\VOCdevkit\VOC2007\2007_train.txt
val: F:\AI\datasets\VOC2007\VOCdevkit\VOC2007\2007_val.txt
# number of classes
nc: 20
# class names
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']注意:上述文件中nc代表类别的个数,如果是训练自己的数据集,需要修改为自己数据集的类别个数。names代表类别的名称,对于VOC总共有20个类别。
4.2 修改yolov5s.yaml文件
该文件位于:yolov5\models目录下,文件内容如下:
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
该文件需要修改的地方是第2行nc的个数,需要改成自己数据集类别的个数,对于VOC数据集改成20。
5. 训练
进入YOLOv5项目(项目文件从github下载)根目录,如下所示的目录:
在命令行中运行如下命令:
python train.py --epochs 10 --cfg models\yolov5s.yaml --data data\voc.yaml --weights weights\yolov5s.pt运行后输入如下内容,便开始训练了:
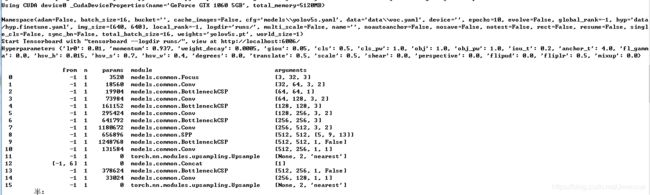
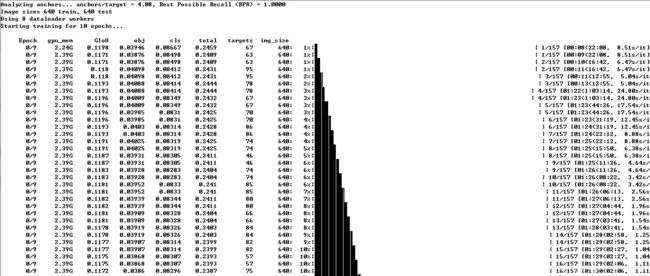
模型训练过程中默认会在yolov5/runs目录下生成一个目录exp1,exp2等等,每运行一次上述命令,生成一个文件夹,用于保存运行中一些数据。
运行结束时输出如下:
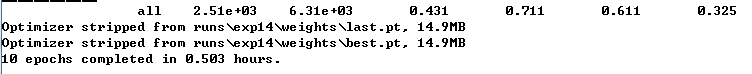
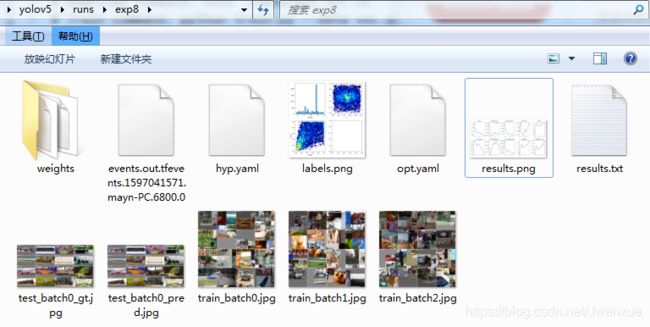
运行结束后运行目录结果如下:
6. 关于报错
6.1 KeyError: "weights/yolov5s.pt is not compatible with models/yolov5s.yaml
由于最近YOLOv5 github项目更新频繁,可能上面提到的模型文件yolov5s.pt等已经过期了,这时就需要下载新的模型文件来进行训练。谷歌网盘地址:https://drive.google.com/drive/folders/1Drs_Aiu7xx6S-ix95f9kNsA6ueKRpN2J
6.2 RuntimeError: CUDA out of memory
这类报错原因是显卡内存太小了,一次装不下太多的图片,因此可以通过--batch-size调整每个批次样本的个数,默认值是16。报错后可以调整为8试试,如果还是报错,再调整为4试试,如果还是报错,那请找一把锤子,瞄准电脑主机箱用力地砸下去...
6.3 torch.nn.modules.module.ModuleAttributeError: 'BatchNorm2d' object has no attribute '_non_persistent_buffers_set'
这类报错也是模型文件更新导致的,需要下载新的模型文件。