Python Scrapy爬虫框架学习!半小时掌握它!
Scrapy 是用Python实现一个为爬取网站数据、提取结构性数据而编写的应用框架。
一、Scrapy框架简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。
二、架构流程图
Python资源共享群:484031800
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
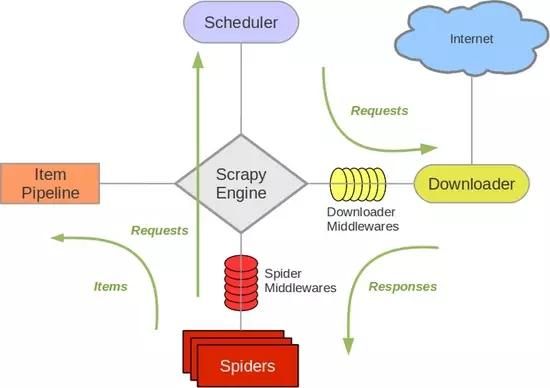
1、组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
2、数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
引擎向调度器请求下一个要爬取的URL。
调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
3、事件驱动网络(Event-driven networking)
Scrapy基于事件驱动网络框架 Twisted 编写。因此,Scrapy基于并发性考虑由非阻塞(即异步)的实现。
关于异步编程及Twisted更多的内容请查看下列链接:
三、4步制作爬虫
新建项目(scrapy startproject xxx):新建一个新的爬虫项目
明确目标(编写items.py):明确你想要抓取的目标
制作爬虫(spiders/xxsp der.py):制作爬虫开始爬取网页
存储内容(pipelines.py):设计管道存储爬取内容
四、安装框架
这里我们使用 conda 来进行安装:
conda install scrapy
或者使用 pip 进行安装:
pip install scrapy
查看安装:
spider scrapy -h Scrapy 1.4.0 - no active project Usage: scrapy[options] [args] Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy -h" to see more info about a command
1.创建项目
spider scrapy startproject SF New Scrapy project 'SF', using template directory '/Users/kaiyiwang/anaconda2/lib/python2.7/site-packages/scrapy/templates/project', created in: /Users/kaiyiwang/Code/python/spider/SF You can start your first spider with: cd SF scrapy genspider example example.com spider
使用 tree 命令可以查看项目结构:
SF tree . ├── SF │ ├── __init__.py │ ├── items.py │ ├── middlewares.py │ ├── pipelines.py │ ├── settings.py │ └── spiders │ └── __init__.py └── scrapy.cfg

2.在spiders 目录下创建模板
spiders scrapy genspider sf "https://segmentfault.com" Created spider 'sf' using template 'basic' in module: SF.spiders.sf spiders
这样,就生成了一个项目文件 sf.py
# -*- coding: utf-8 -*-
import scrapy
from SF.items import SfItem
class SfSpider(scrapy.Spider):
name = 'sf'
allowed_domains = ['https://segmentfault.com']
start_urls = ['https://segmentfault.com/']
def parse(self, response):
# print response.body
# pass
node_list = response.xpath("//h2[@class='title']")
# 用来存储所有的item字段的
# items = []
for node in node_list:
# 创建item字段对象,用来存储信息
item = SfItem()
# .extract() 将xpath对象转换为 Unicode字符串
title = node.xpath("./a/text()").extract()
item['title'] = title[0]
# 返回抓取到的item数据,给管道文件处理,同时还回来继续执行后边的代码
yield.item
#return item
#return scrapy.Request(url)
#items.append(item)
命令:
# 测试爬虫是否正常, sf为爬虫的名称
scrapy check sf
s
# 运行爬虫
scrapy crawl sf
3.item pipeline
当 item 在Spider中被收集之后,它将会被传递到 item Pipeline, 这些 item Pipeline 组件按定义的顺序处理 item.
每个 Item Pipeline 都是实现了简单方法的Python 类,比如决定此Item是丢弃或存储,以下是 item pipeline 的一些典型应用:
验证爬取得数据(检查item包含某些字段,比如说name字段)
查重(并丢弃)
将爬取结果保存到文件或者数据库总(数据持久化)
编写 item pipeline
编写 item pipeline 很简单,item pipeline 组件是一个独立的Python类,其中 process_item()方法必须实现。
from scrapy.exceptions import DropItem
class PricePipeline(object):
vat_factor = 1.15
def process_item(self, item, spider):
if item['price']:
if item['price_excludes_vat']:
item['price'] = item['price'] * self.vat_factor
return item
else:
raise DropItem("Missing price in %s" % item)
4.选择器(Selectors)
当抓取网页时,你做的最常见的任务是从HTML源码中提取数据。
Selector 有四个基本的方法,最常用的还是Xpath
xpath():传入xpath表达式,返回该表达式所对应的所有节点的selector list 列表。
extract(): 序列化该节点为Unicode字符串并返回list
css():传入CSS表达式,返回该表达式所对应的所有节点的selector list 列表,语法同 BeautifulSoup4
re():根据传入的正则表达式对数据进行提取,返回Unicode 字符串list 列表
Scrapy提取数据有自己的一套机制。它们被称作选择器(seletors),因为他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关连。
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。
XPath表达式的例子:
/html/head/title: 选择文档中标签内的元素 /html/head/title/text(): 选择上面提到的<title>元素的问题 //td: 选择所有的<td> 元素 //div[@class="mine"]:选择所有具有 class="mine" 属性的 div 元素 </pre> <p>五、爬取招聘信息</p> <p>1.爬取腾讯招聘信息</p> <p>爬取的地址:http://hr.tencent.com/positio...</p> <p>1.1 创建项目</p> <pre> > scrapy startproject Tencent You can start your first spider with: cd Tencent scrapy genspider example example.com </pre> <p> </p> <p><a href="http://img.e-com-net.com/image/info8/317513715ad0475f9e035bfe694637fe.jpg" target="_blank"><img alt="Python Scrapy爬虫框架学习!半小时掌握它!_第3张图片" class="has" src="http://img.e-com-net.com/image/info8/317513715ad0475f9e035bfe694637fe.jpg" width="452" height="200" style="border:1px solid black;"></a></p> <p> </p> <p> </p> <p> </p> <p> </p> <p>需要抓取网页的元素:</p> <p><a href="http://img.e-com-net.com/image/info8/cf1db75911b941e294d972bd5d9b1f33.jpg" target="_blank"><img alt="Python Scrapy爬虫框架学习!半小时掌握它!_第4张图片" class="has" src="http://img.e-com-net.com/image/info8/cf1db75911b941e294d972bd5d9b1f33.jpg" width="550" height="373" style="border:1px solid black;"></a></p> <p> </p> <p> </p> <p> </p> <p> </p> <p>我们需要爬取以下信息:</p> <p>职位名:positionName</p> <p>职位链接:positionLink</p> <p>职位类型:positionType</p> <p>职位人数:positionNumber</p> <p>工作地点:workLocation</p> <p>发布时点:publishTime</p> <p>在 items.py 文件中定义爬取的字段:</p> <pre># -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html import scrapy # 定义字段 class TencentItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() # 职位名 positionName = scrapy.Field() # 职位链接 positionLink = scrapy.Field() # 职位类型 positionType = scrapy.Field() # 职位人数 positionNumber = scrapy.Field() # 工作地点 workLocation = scrapy.Field() # 发布时点 publishTime = scrapy.Field() pass </pre> <p>1.2 写spider爬虫</p> <p>使用命令创建</p> <p>Tencent scrapy genspider tencent "tencent.com"</p> <p>Created spider 'tencent' using template 'basic' in module:</p> <p>Tencent.spiders.tencent</p> <p>生成的 spider 在当前目录下的 spiders/tencent.py</p> <pre> Tencent tree . ├── __init__.py ├── __init__.pyc ├── items.py ├── middlewares.py ├── pipelines.py ├── settings.py ├── settings.pyc └── spiders ├── __init__.py ├── __init__.pyc └── tencent.py </pre> <p>我们可以看下生成的这个初始化文件 tencent.py</p> <pre> # -*- coding: utf-8 -*- import scrapy class TencentSpider(scrapy.Spider): name = 'tencent' allowed_domains = ['tencent.com'] start_urls = ['http://tencent.com/'] def parse(self, response): pass </pre> <p>对初识文件tencent.py进行修改:</p> <pre># -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem class TencentSpider(scrapy.Spider): name = 'tencent' allowed_domains = ['tencent.com'] baseURL = "http://hr.tencent.com/position.php?&start=" offset = 0 # 偏移量 start_urls = [baseURL + str(offset)] def parse(self, response): # 请求响应 # node_list = response.xpath("//tr[@class='even'] or //tr[@class='odd']") node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']") for node in node_list: item = TencentItem() # 引入字段类 # 文本内容, 取列表的第一个元素[0], 并且将提取出来的Unicode编码 转为 utf-8 item['positionName'] = node.xpath("./td[1]/a/text()").extract()[0].encode("utf-8") item['positionLink'] = node.xpath("./td[1]/a/@href").extract()[0].encode("utf-8") # 链接属性 item['positionType'] = node.xpath("./td[2]/text()").extract()[0].encode("utf-8") item['positionNumber'] = node.xpath("./td[3]/text()").extract()[0].encode("utf-8") item['workLocation'] = node.xpath("./td[4]/text()").extract()[0].encode("utf-8") item['publishTime'] = node.xpath("./td[5]/text()").extract()[0].encode("utf-8") # 返回给管道处理 yield item # 先爬 2000 页数据 if self.offset < 2000: self.offset += 10 url = self.baseURL + self.offset yield scrapy.Request(url, callback = self.parse) #pass </pre> <p>写管道文件 pipelines.py:</p> <pre> # -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import json class TencentPipeline(object): def __init__(self): self.f = open("tencent.json", "w") # 所有的item使用共同的管道 def process_item(self, item, spider): content = json.dumps(dict(item), ensure_ascii = False) + ",\n" self.f.write(content) return item def close_spider(self, spider): self.f.close() </pre> <p>管道写好之后,在 settings.py 中启用管道</p> <pre> # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'Tencent.pipelines.TencentPipeline': 300, } </pre> <p>运行:</p> <pre> > scrapy crawl tencent File "/Users/kaiyiwang/Code /python/spider /Tencent/Tencent/spiders/tencent.py", line 21, in parse item['positionName'] = node.xpath("./td[1]/a/text()"). extract()[0].encode("utf-8") IndexError: list index out of range </pre> <p>请求响应这里写的有问题,Xpath或应该为这种写法:</p> <p># 请求响应</p> <p># node_list = response.xpath("//tr[@class='even'] or //tr[@class='odd']")</p> <p>node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']")</p> <p>然后再执行命令:</p> <p>> scrapy crawl tencent</p> <p>执行结果文件 tencent.json :</p> <pre> {"positionName": "23673-财经运营中心热点运营组编辑", "publishTime": "2017-12-02", "positionLink": "position_detail.php?id=32718&keywords=&tid=0&lid=0", "positionType": "内容编辑类", "workLocation": "北京", "positionNumber": "1"}, {"positionName": "MIG03-腾讯地图高级算法评测工程师(北京)", "publishTime": "2017-12-02", "positionLink": "position_detail.php?id=30276&keywords=&tid=0&lid=0", "positionType": "技术类", "workLocation": "北京", "positionNumber": "1"}, {"positionName": "MIG10-微回收渠道产品运营经理(深圳)", "publishTime": "2017-12-02", "positionLink": "position_detail.php?id=32720&keywords=&tid=0&lid=0", "positionType": "产品/项目类", "workLocation": "深圳", "positionNumber": "1"}, {"positionName": "MIG03-iOS测试开发工程师(北京)", "publishTime": "2017-12-02", "positionLink": "position_detail.php?id=32715&keywords=&tid=0&lid=0", "positionType": "技术类", "workLocation": "北京", "positionNumber": "1"}, {"positionName": "19332-高级PHP开发工程师(上海)", "publishTime": "2017-12-02", "positionLink": "position_detail.php?id=31967&keywords=&tid=0&lid=0", "positionType": "技术类", "workLocation": "上海", "positionNumber": "2"} </pre> <p>1.3 通过下一页爬取</p> <p>我们上边是通过总的页数来抓取每页数据的,但是没有考虑到每天的数据是变化的,所以,需要爬取的总页数不能写死,那该怎么判断是否爬完了数据呢?其实很简单,我们可以根据下一页来爬取,只要下一页没有数据了,就说明数据已经爬完了。</p> <p><a href="http://img.e-com-net.com/image/info8/816d1cacbb804a7083adf696e6fc16fc.jpg" target="_blank"><img alt="Python Scrapy爬虫框架学习!半小时掌握它!_第5张图片" class="has" src="http://img.e-com-net.com/image/info8/816d1cacbb804a7083adf696e6fc16fc.jpg" width="550" height="170" style="border:1px solid black;"></a></p> <p> </p> <p> </p> <p> </p> <p> </p> <p>我们通过 下一页 看下最后一页的特征:</p> <p><a href="http://img.e-com-net.com/image/info8/8f01e34f980c457eacb608d54df9b94f.jpg" target="_blank"><img alt="Python Scrapy爬虫框架学习!半小时掌握它!_第6张图片" class="has" src="http://img.e-com-net.com/image/info8/8f01e34f980c457eacb608d54df9b94f.jpg" width="550" height="197" style="border:1px solid black;"></a></p> <p> </p> <p> </p> <p> </p> <p> </p> <p>下一页的按钮为灰色,并且链接为 class='noactive'属性了,我们可以根据此特性来判断是否到最后一页了。</p> <pre># 写死总页数,先爬 100 页数据 """ if self.offset < 100: self.offset += 10 url = self.baseURL + str(self.offset) yield scrapy.Request(url, callback = self.parse) """ # 使用下一页爬取数据 if len(response.xpath("//a[@class='noactive' and @id='next']")) == 0: url = response.xpath("//a[@id='next']/@href").extract()[0] yield scrapy.Request("http://hr.tencent.com/" + url, callback = self.parse) </pre> <p>修改后的tencent.py文件:</p> <pre># -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem class TencentSpider(scrapy.Spider): # 爬虫名 name = 'tencent' # 爬虫爬取数据的域范围 allowed_domains = ['tencent.com'] # 1.需要拼接的URL baseURL = "http://hr.tencent.com/position.php?&start=" # 需要拼接的URL地址的偏移量 offset = 0 # 偏移量 # 爬虫启动时,读取的URL地址列表 start_urls = [baseURL + str(offset)] # 用来处理response def parse(self, response): # 提取每个response的数据 node_list = response.xpath("//tr[@class='even'] | //tr[@class='odd']") for node in node_list: # 构建item对象,用来保存数据 item = TencentItem() # 文本内容, 取列表的第一个元素[0], 并且将提取出来的Unicode编码 转为 utf-8 print node.xpath("./td[1]/a/text()").extract() item['positionName'] = node.xpath("./td[1]/a/text()").extract()[0].encode("utf-8") item['positionLink'] = node.xpath("./td[1]/a/@href").extract()[0].encode("utf-8") # 链接属性 # 进行是否为空判断 if len(node.xpath("./td[2]/text()")): item['positionType'] = node.xpath("./td[2]/text()").extract()[0].encode("utf-8") else: item['positionType'] = "" item['positionNumber'] = node.xpath("./td[3]/text()").extract()[0].encode("utf-8") item['workLocation'] = node.xpath("./td[4]/text()").extract()[0].encode("utf-8") item['publishTime'] = node.xpath("./td[5]/text()").extract()[0].encode("utf-8") # yield的重要性,是返回数据后还能回来接着执行代码,返回给管道处理,如果为return 整个函数都退出了 yield item # 第一种写法:拼接URL,适用场景:页面没有可以点击的请求链接,必须通过拼接URL才能获取响应 """ if self.offset < 100: self.offset += 10 url = self.baseURL + str(self.offset) yield scrapy.Request(url, callback = self.parse) """ < # 第二种写法:直接从response获取需要爬取的连接,并发送请求处理,直到连接全部提取完(使用下一页爬取数据) if len(response.xpath("//a[@class='noactive' and @id='next']")) == 0: url = response.xpath("//a[@id='next']/@href").extract()[0] yield scrapy.Request("http://hr.tencent.com/" + url, callback = self.parse) #pass </pre> <p>OK,通过 根据下一页我们成功爬完招聘信息的所有数据。</p> <p>1.4 小结</p> <p>爬虫步骤:</p> <p>1.创建项目 scrapy project XXX</p> <p>2.scarpy genspider xxx "http://www.xxx.com"</p> <p>3.编写 items.py, 明确需要提取的数据</p> <p>4.编写 spiders/xxx.py, 编写爬虫文件,处理请求和响应,以及提取数据(yield item)</p> <p>5.编写 pipelines.py, 编写管道文件,处理spider返回item数据,比如本地数据持久化,写文件或存到表中。</p> <p>6.编写 settings.py,启动管道组件ITEM_PIPELINES,以及其他相关设置</p> <p>7.执行爬虫 scrapy crawl xxx</p> <p>有时候被爬取的网站可能做了很多限制,所以,我们请求时可以添加请求报头,scrapy 给我们提供了一个很方便的报头配置的地方,settings.py 中,我们可以开启:</p> <pre># Crawl responsibly by identifying yourself (and your website) on the user-agent USER_AGENT = 'Tencent (+http://www.yourdomain.com)' User-AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" # Override the default request headers: DEFAULT_REQUEST_HEADERS = { 'Accept': 'text/html,application/xhtml+xml, application/xml;q=0.9,*/*;q=0.8', 'Accept-Language': 'en', } </pre> <p>scrapy 最大的适用场景是爬取静态页面,性能非常强悍,但如果要爬取动态的json数据,那就没必要了。</p> </div> </div> </div> </div> </div> <!--PC和WAP自适应版--> <div id="SOHUCS" sid="1292898437167128576"></div> <script type="text/javascript" src="/views/front/js/chanyan.js"></script> <!-- 文章页-底部 动态广告位 --> <div class="youdao-fixed-ad" id="detail_ad_bottom"></div> </div> <div class="col-md-3"> <div class="row" id="ad"> <!-- 文章页-右侧1 动态广告位 --> <div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_1"> </div> </div> <!-- 文章页-右侧2 动态广告位 --> <div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_2"></div> </div> <!-- 文章页-右侧3 动态广告位 --> <div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad"> <div class="youdao-fixed-ad" id="detail_ad_3"></div> </div> </div> </div> </div> </div> </div> <div class="container"> <h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(Python,Python)</h4> <div id="paradigm-article-related"> <div class="recommend-post mb30"> <ul class="widget-links"> <li><a href="/article/1899409406920028160.htm" title="量子计算如何颠覆能源优化领域:从理论到实践" target="_blank">量子计算如何颠覆能源优化领域:从理论到实践</a> <span class="text-muted">Echo_Wish</span> <a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E6%B2%BF%E6%8A%80%E6%9C%AF/1.htm">前沿技术</a><a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%AD%90%E8%AE%A1%E7%AE%97/1.htm">量子计算</a><a class="tag" taget="_blank" href="/search/%E8%83%BD%E6%BA%90/1.htm">能源</a> <div>量子计算如何颠覆能源优化领域:从理论到实践大家好,我是Echo_Wish,一个热爱探索前沿技术的人工智能与Python领域的技术分享者。今天,我们将深入探讨一个激动人心的话题——量子计算在能源优化中的应用。这不仅是科技领域的全新趋势,也可能为全人类的能源利用效率带来革命性突破。从理论模型到实际应用,量子计算已经在一些能源相关领域崭露头角,例如电网优化、可再生能源分配和物流节能规划。以下,让我们一步</div> </li> <li><a href="/article/1899405245457428480.htm" title="Kibana 单机与集群部署教程" target="_blank">Kibana 单机与集群部署教程</a> <span class="text-muted">闲人编程</span> <a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE%E9%9B%86%E7%BE%A4%E9%83%A8%E7%BD%B2%E6%95%99%E7%A8%8B/1.htm">大数据集群部署教程</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a><a class="tag" taget="_blank" href="/search/%E9%9B%86%E7%BE%A4/1.htm">集群</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E6%9C%BA/1.htm">单机</a><a class="tag" taget="_blank" href="/search/%E9%83%A8%E7%BD%B2/1.htm">部署</a><a class="tag" taget="_blank" href="/search/Kibana/1.htm">Kibana</a><a class="tag" taget="_blank" href="/search/%E6%97%A5%E5%BF%97%E5%88%86%E6%9E%90/1.htm">日志分析</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%8F%AF%E8%A7%86%E5%8C%96/1.htm">数据可视化</a> <div>目录Kibana单机与集群部署教程第一部分:Kibana概述第二部分:Kibana单机部署教程1.安装Kibana1.1安装依赖项1.2下载和安装Kibana1.3启动Kibana2.单机案例代码实现(Python)3.常见问题及解决方法3.1无法启动Kibana服务3.2Kibana无法连接到Elasticsearch第三部分:Kibana集群部署教程1.配置集群节点1.1配置Elasticse</div> </li> <li><a href="/article/1899402974443139072.htm" title="INCA二次开发GUI实例化" target="_blank">INCA二次开发GUI实例化</a> <span class="text-muted">智海行舟</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E4%B8%AA%E4%BA%BA%E5%BC%80%E5%8F%91/1.htm">个人开发</a> <div>【摘要】本文基于ETASINCA二次开发实践,深入探讨如何构建完整的自动化测试GUI系统。通过Python语言结合COM接口技术,实现从软件架构设计到功能模块开发的完整闭环,为汽车电子领域工程师提供可复用的开发范式。一、INCA二次开发技术背景1.1行业应用需求在汽车电子开发领域,ETASINCA作为行业标准标定工具,其自动化测试需求日益增长。传统的手动操作模式存在以下痛点:重复性操作耗时严重(单</div> </li> <li><a href="/article/1899402216096198656.htm" title="如何通过API用Python获取北向资金流向数据?" target="_blank">如何通过API用Python获取北向资金流向数据?</a> <span class="text-muted">量化问财</span> <a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%8C%96%E8%BD%AF%E4%BB%B6/1.htm">量化软件</a><a class="tag" taget="_blank" href="/search/QMT/1.htm">QMT</a><a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%8C%96%E4%BA%A4%E6%98%93/1.htm">量化交易</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%8C%96%E7%82%92%E8%82%A1/1.htm">量化炒股</a><a class="tag" taget="_blank" href="/search/PTrade/1.htm">PTrade</a><a class="tag" taget="_blank" href="/search/QMT/1.htm">QMT</a><a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%8C%96%E4%BA%A4%E6%98%93/1.htm">量化交易</a><a class="tag" taget="_blank" href="/search/%E9%87%8F%E5%8C%96%E8%BD%AF%E4%BB%B6/1.htm">量化软件</a><a class="tag" taget="_blank" href="/search/deepseek/1.htm">deepseek</a> <div>推荐阅读:《【最全攻略】免费的量化软件有哪些?券商的交易接口怎么获取?》如何通过API用Python获取北向资金流向数据?北向资金指的是通过沪港通和深港通渠道,从香港市场流入A股市场的资金。对于投资者来说,了解北向资金流向对于把握市场趋势和投资决策具有重要意义。本文将介绍如何通过API用Python获取北向资金流向数据。理解北向资金流向数据北向资金流向数据主要包括以下几个方面:资金流入量:指通过沪</div> </li> <li><a href="/article/1899396287590100992.htm" title="go执行java -jar 完成DSA私钥解析并签名" target="_blank">go执行java -jar 完成DSA私钥解析并签名</a> <span class="text-muted">DavidSoCool</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jar/1.htm">jar</a><a class="tag" taget="_blank" href="/search/golang/1.htm">golang</a> <div>起因,最近使用go对接百度联盟api需要使用到DSA私钥完成签名过程,在百度提供的代码示例里面没有go代码的支持,示例中仅有php、python2和3、java的代码,网上找了半天发现go中对DSA私钥解析支持不友好,然后决定使用在java中完成签名计算过程,生成可执行jar后由外部传入参数获取签名数据。百度联盟api文档说明:1)权限开通后,登录百度联盟媒体平台(union.baidu.com)</div> </li> <li><a href="/article/1899392881412599808.htm" title="【30天玩转python】项目实战:从零开始开发一个Python项目" target="_blank">【30天玩转python】项目实战:从零开始开发一个Python项目</a> <span class="text-muted">爱技术的小伙子</span> <a class="tag" taget="_blank" href="/search/30%E5%A4%A9%E7%8E%A9%E8%BD%ACpython/1.htm">30天玩转python</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a> <div>项目实战:从零开始开发一个Python项目在学习Python的过程中,开发一个完整的项目是非常重要的实战练习。它不仅能够帮助你巩固所学的知识,还能提高实际编程能力。本文将带领你从零开始开发一个Python项目,介绍从项目规划、环境搭建、代码实现到项目发布的完整过程。我们将以一个简单的“任务管理系统”为例,逐步讲解如何构建、测试和优化这个项目。1.项目规划1.1项目简介我们将开发一个基于命令行的任务</div> </li> <li><a href="/article/1899388724085583872.htm" title="Python从0到100(七十六):计算机视觉-直方图和自适应直方图均衡化" target="_blank">Python从0到100(七十六):计算机视觉-直方图和自适应直方图均衡化</a> <span class="text-muted">是Dream呀</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/1.htm">计算机视觉</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>前言:零基础学Python:Python从0到100最新最全教程。想做这件事情很久了,这次我更新了自己所写过的所有博客,汇集成了Python从0到100,共一百节课,帮助大家一个月时间里从零基础到学习Python基础语法、Python爬虫、Web开发、计算机视觉、机器学习、神经网络以及人工智能相关知识,成为学习学习和学业的先行者!欢迎大家订阅专栏:零基础学Python:Python从0到100最新</div> </li> <li><a href="/article/1899386453226483712.htm" title="python递推法_如何使用Python递归函数中的递推?" target="_blank">python递推法_如何使用Python递归函数中的递推?</a> <span class="text-muted">热茶走</span> <a class="tag" taget="_blank" href="/search/python%E9%80%92%E6%8E%A8%E6%B3%95/1.htm">python递推法</a> <div>我们大家都知道,一个函数可能存在多种不同的用法,很少是有函数只针对一个方式,那么基于一种函数,我们肯定要了解多个方式,今日针对递归函数里的递推内容给大家介绍哦~递归是什么?是指函数/过程/子程序在运行过程序中直接或间接调用自身而产生的重入现象。下面是个人理解:递归就是在函数内部调用自己的函数被称之为递归。实例:#直接调用自己:deffunc:print('fromfunc')funcFunc#间接</div> </li> <li><a href="/article/1899386074359197696.htm" title="python递推式_Python 递推式构造列表(List Comprehensions)" target="_blank">python递推式_Python 递推式构造列表(List Comprehensions)</a> <span class="text-muted">man One</span> <a class="tag" taget="_blank" href="/search/python%E9%80%92%E6%8E%A8%E5%BC%8F/1.htm">python递推式</a> <div>你需要构造一个新的列表,列表中的元素是从一个已知列表中的元素计算而得到的.比如你要创建一个列表,里面的元素是另一个列表中的元素加23后得到的.使用递推式构造列表是最理想的方法:thenewlist=[x+23forxintheoldlist]如果你希望用一个列表中大于5的元素构造一个新的列表,使用递推式也是很方便的:thenewlist=[xforxintheoldlistifx>5]如果你希望将</div> </li> <li><a href="/article/1899384937878974464.htm" title="Dash 简介" target="_blank">Dash 简介</a> <span class="text-muted">tankusa</span> <a class="tag" taget="_blank" href="/search/dash/1.htm">dash</a> <div>Dash是一个基于Python的开源框架,专门用于构建数据分析和数据可视化的Web应用程序。Dash由Plotly团队开发,旨在帮助数据分析师、数据科学家和开发人员快速创建交互式的、基于数据的Web应用,而无需深入掌握前端技术(如HTML、CSS和JavaScript)。Dash的核心优势在于其简单易用性和强大的功能。通过Dash,用户可以使用纯Python代码来构建复杂的Web应用,而无需编写繁</div> </li> <li><a href="/article/1899380142069837824.htm" title="视频下载插件:yt-dlp" target="_blank">视频下载插件:yt-dlp</a> <span class="text-muted">小怪兽长大啦</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>Yt-dlp插件使用下载方法方法一:Python插件下载使用pip工具安装即可:pipinstallyt-dlp.Python已经配置过环境变量,下载yt-dlp时不需要配置。方法二:直接下载EXE可执行文件网上下载yt-dlp应用程序:https://github.com/yt-dlp/yt-dlp/releases配置环境变量。常用使用命令(配置好环境变量后,控制台下输入命令即可)直接下载视频</div> </li> <li><a href="/article/1899379386608578560.htm" title="Python __init__.py 模块详解" target="_blank">Python __init__.py 模块详解</a> <span class="text-muted">鱼丸丶粗面</span> <a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/__init__.py/1.htm">__init__.py</a> <div>文章目录1概述2导入演示2.1执行顺序:先父后子2.2导入所有模块(含子模块)1概述1.工具:Pycharm场景:在创建一个PythonPackage时,会默认在该包下生成一个'__init__.py'文件2.目的:'进行一些初始化操作'(1)当importpackage时,"自动"执行'__init__.py'文件中的内容(2)常用于导入模块2导入演示2.1执行顺序:先父后子目录结构:目录结构简</div> </li> <li><a href="/article/1899378250661031936.htm" title="Python __init__.py" target="_blank">Python __init__.py</a> <span class="text-muted">愚昧之山绝望之谷开悟之坡</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/init/1.htm">init</a> <div>Python__init__.py作用详解尼古拉苏关注12018.06.1012:57:34字数745阅读45,278转载于:https://www.cnblogs.com/tp1226/p/8453854.html__init__.py该文件的作用就是相当于把自身整个文件夹当作一个包来管理,每当有外部import的时候,就会自动执行里面的函数。1.标识该目录是一个python的模块包(modul</div> </li> <li><a href="/article/1899364248610467840.htm" title="机器学习之线性代数" target="_blank">机器学习之线性代数</a> <span class="text-muted">珠峰日记</span> <a class="tag" taget="_blank" href="/search/AI%E7%90%86%E8%AE%BA%E4%B8%8E%E5%AE%9E%E8%B7%B5/1.htm">AI理论与实践</a><a class="tag" taget="_blank" href="/search/%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0/1.htm">机器学习</a><a class="tag" taget="_blank" href="/search/%E7%BA%BF%E6%80%A7%E4%BB%A3%E6%95%B0/1.htm">线性代数</a><a class="tag" taget="_blank" href="/search/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/1.htm">人工智能</a> <div>文章目录一、引言:线性代数为何是AI的基石二、向量:AI世界的基本构建块(一)向量的定义(二)向量基础操作(三)重要概念三、矩阵:AI数据的强大容器(一)矩阵的定义(二)矩阵运算(三)矩阵特性(四)矩阵分解(五)Python示例(使用NumPy库)四、线性代数在AI中的应用(一)数据表示(二)降维:PCA(三)线性回归(四)计算机视觉(五)自然语言处理一、引言:线性代数为何是AI的基石在人工智能领</div> </li> <li><a href="/article/1899359709018779648.htm" title="有趣的学习Python-第十篇:Python的“魔法宝库”:标准库之旅" target="_blank">有趣的学习Python-第十篇:Python的“魔法宝库”:标准库之旅</a> <span class="text-muted">王盼达</span> <a class="tag" taget="_blank" href="/search/%E6%9C%89%E8%B6%A3%E7%9A%84%E5%AD%A6%E4%B9%A0Python/1.htm">有趣的学习Python</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>Python不仅是一门强大的编程语言,更像是一座充满宝藏的“魔法宝库”,里面装满了各种各样的“魔法工具”(标准库)。这些“魔法工具”可以帮助你轻松地完成各种任务,从文件操作到网络编程,从数据处理到性能优化。接下来,让我们一起探索Python的“魔法宝库”,看看这些“魔法工具”到底有多神奇!10.1操作系统接口:与“魔法世界”互动os模块就像是一个“魔法接口”,可以帮助你与操作系统进行互动。你可以用</div> </li> <li><a href="/article/1899359582615040000.htm" title="有趣的学习Python-第八篇:Python的“魔法盾牌”:错误与异常处理" target="_blank">有趣的学习Python-第八篇:Python的“魔法盾牌”:错误与异常处理</a> <span class="text-muted">王盼达</span> <a class="tag" taget="_blank" href="/search/%E6%9C%89%E8%B6%A3%E7%9A%84%E5%AD%A6%E4%B9%A0Python/1.htm">有趣的学习Python</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>在Python的魔法世界里,即使是经验丰富的魔法师也可能遇到一些“魔法失误”。这些失误分为两种:语法错误和异常。别担心,Python为你准备了一面强大的“魔法盾牌”,帮助你应对这些挑战。8.1语法错误:魔法咒语写错了语法错误就像是你在念魔法咒语时,不小心说错了单词。这是学习Python过程中最常见的问题。比如,你可能忘记在while循环后面加上冒号:whileTrueprint('Hellowor</div> </li> <li><a href="/article/1899358951691055104.htm" title="Python字符串操作" target="_blank">Python字符串操作</a> <span class="text-muted">weixin_30871905</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>转自http://blog.chinaunix.net/u/19742/showart_382176.html#Python字符串操作'''1.复制字符串'''#strcpy(sStr1,sStr2)sStr1='strcpy'sStr2=sStr1sStr1='strcpy2'printsStr2'''2.连接字符串'''#strcat(sStr1,sStr2)sStr1='strcat'sSt</div> </li> <li><a href="/article/1899348108433747968.htm" title="零基础必看!CCF-GESP Python一级考点全解析:运算符这样学就对了" target="_blank">零基础必看!CCF-GESP Python一级考点全解析:运算符这样学就对了</a> <span class="text-muted">奕澄羽邦</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>第一章编程世界的基础工具:运算符三剑客在Python编程语言中,运算符如同魔法咒语般神奇。对于CCF-GESPPython一级考生而言,正确掌握比较运算符、算术运算符和逻辑运算符这三大基础工具,就相当于打开了数字世界的大门。这三个运算符家族共同构成了程序逻辑的核心骨架,其灵活组合能实现从简单计算到复杂判断的多样功能。1.1运算符分类图谱算术运算符:负责数字间的数学运算(+-*/%)比较运算符:用于</div> </li> <li><a href="/article/1899347352498532352.htm" title="Python 字符串操作" target="_blank">Python 字符串操作</a> <span class="text-muted">iteye_13776</span> <a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/C/1.htm">C</a><a class="tag" taget="_blank" href="/search/C%2B%2B/1.htm">C++</a><a class="tag" taget="_blank" href="/search/C%23/1.htm">C#</a> <div>Python截取字符串使用变量[头下标:尾下标],就可以截取相应的字符串,其中下标是从0开始算起,可以是正数或负数,下标可以为空表示取到头或尾。#例1:字符串截取str='12345678'printstr[0:1]>>1#输出str位置0开始到位置1以前的字符printstr[1:6]>>23456#输出str位置1开始到位置6以前的字符num=18str='0000'+str(num)#合并字</div> </li> <li><a href="/article/1899331847842754560.htm" title="【Python 第五篇章】数据类型" target="_blank">【Python 第五篇章】数据类型</a> <span class="text-muted">蜗牛 | ICU</span> <a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/%E4%B8%93%E6%A0%8F/1.htm">专栏</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>一、列表详解list.append(x)在列表末尾添加一个元素。list.extend(iterable)用可迭代对象的元素扩展列表。list.insert(i,x)在指定位置插入元素,第一个参数是插入元素的索引,第二个是值。list.remove(x)从列表中删除第一个值为x的元素。list.pop([i])移除列表中给定位置的条目,并返回该条目。如果未指定索引号,则a.pop()将移除并返回列</div> </li> <li><a href="/article/1899331721439014912.htm" title="python catia catalog文件_Python封装的获取文件目录的函数" target="_blank">python catia catalog文件_Python封装的获取文件目录的函数</a> <span class="text-muted">卢新生</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/catia/1.htm">catia</a><a class="tag" taget="_blank" href="/search/catalog%E6%96%87%E4%BB%B6/1.htm">catalog文件</a> <div>获取指定文件夹中文件的函数,网上学习时东拼西凑的结果。注意,其中文件名如1.txt,文件路径如D:\文件夹\1.txt;direct为第一层子级importos#filePath输入文件夹全路径#mode#1递归获取所有文件名;#2递归获取所有文件路径;#3获取direct文件名;#4获取direct文件路径;#5获取direct文件名和direct子文件夹名;#6获取direct文件路径和dir</div> </li> <li><a href="/article/1899330208956215296.htm" title="Python:每日一题之错误票据" target="_blank">Python:每日一题之错误票据</a> <span class="text-muted">努力的敲码工</span> <a class="tag" taget="_blank" href="/search/%E8%93%9D%E6%A1%A5%E6%9D%AF/1.htm">蓝桥杯</a><a class="tag" taget="_blank" href="/search/%E6%AF%8F%E6%97%A5%E4%B8%80%E9%A2%98/1.htm">每日一题</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E8%93%9D%E6%A1%A5%E6%9D%AF/1.htm">蓝桥杯</a> <div>题目描述某涉密单位下发了某种票据,并要在年终全部收回。每张票据有唯一的ID号。全年所有票据的ID号是连续的,但ID的开始数码是随机选定的。因为工作人员疏忽,在录入ID号的时候发生了一处错误,造成了某个ID断号,另外一个ID重号。你的任务是通过编程,找出断号的ID和重号的ID。假设断号不可能发生在最大和最小号。输入描述输入描述要求程序首先输入一个整数N(N<100)表示后面数据行数。接着读入N行数据</div> </li> <li><a href="/article/1899320746539282432.htm" title="Python控制批量插入Catia文件并修改文件定义及PN" target="_blank">Python控制批量插入Catia文件并修改文件定义及PN</a> <span class="text-muted">一盘红烧肉</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>改了两天,总算初步摸清楚了Catia中的文件结构,实现了使用Python控制批量修改文件名及定义使用Pycatia在Product中插入Part并改名及定义</div> </li> <li><a href="/article/1899310787294457856.htm" title="PySide2是 Qt 库的 Python 绑定之一" target="_blank">PySide2是 Qt 库的 Python 绑定之一</a> <span class="text-muted">WwwwwH_PLUS</span> <a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/Qt/1.htm">Qt</a><a class="tag" taget="_blank" href="/search/qt/1.htm">qt</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>PySide2是Qt库的Python绑定之一,它为Python程序员提供了创建跨平台桌面应用程序的工具和功能。PySide2是Qt5.x系列的Python绑定,而Qt本身是一个跨平台的图形用户界面(GUI)框架,广泛用于开发各种类型的桌面应用程序,包括多种平台(Windows、Linux、macOS)的应用。主要特点跨平台支持:PySide2可以在Windows、Linux和macOS上运行,允许</div> </li> <li><a href="/article/1899309401106345984.htm" title="Python学习第十一天" target="_blank">Python学习第十一天</a> <span class="text-muted">Leo来编程</span> <a class="tag" taget="_blank" href="/search/Python%E5%AD%A6%E4%B9%A0/1.htm">Python学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a> <div>疑惑:有很多人不知道是不是也分不清什么是单核?什么是多核?什么是时间片?进程?线程?那么在讲进程和线程前我先举个例子更好理解这些概念。单核例子:比如你是一个厨师(计算机)在一个厨房(CPU)里需要同时做3个菜(进程)、每个菜需要准备不同的调料以及协作(线程),那么这个厨师需要不断地切换时间(时间片)来达到同时在一个时间将三个菜做完。多核的话其实对应的例子就是多个厨师,这样的例子太多了因为万物皆对象</div> </li> <li><a href="/article/1899309274656468992.htm" title="python学习第三天" target="_blank">python学习第三天</a> <span class="text-muted">Leo来编程</span> <a class="tag" taget="_blank" href="/search/Python%E5%AD%A6%E4%B9%A0/1.htm">Python学习</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>条件判断条件判断使用if、elif和else关键字。它们用于根据条件执行不同的代码块。#条件判断age=18ifage0:#也可以写if(s>0)但是没必要因为python给个提示建议去掉保证代码的按照缩进来进行更加规范print("这个数字是大于0的数字!")#这行代码属于if语句的代码块elifs==0:print("这个数字是等于0的数字!")#这行代码属于elif语句的代码块else:pr</div> </li> <li><a href="/article/1899305865350017024.htm" title="三种优化算法" target="_blank">三种优化算法</a> <span class="text-muted">旅者时光</span> <a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>本文将总结遗传算法、粒子群算法、模拟退火三种优化算法的核心思路,并使用python完整实现。实际上,越来越多的优秀算法已经被封装为一个易用的接口。很多时候,一行代码就能实现我们的需求。但了解这些算法的基本逻辑,能够使用最基本的代码实现它。无论对于提升我们的编程能力还是解决问题的能力,都会大有裨益。甚至,改变我们思考问题的方式。1、遗传算法遗传算法,顾名思义,就是借鉴了生物通过遗传变异来逐渐适应环境</div> </li> <li><a href="/article/1899300950376509440.htm" title="使用 Python 合并微信与支付宝账单,生成财务报告" target="_blank">使用 Python 合并微信与支付宝账单,生成财务报告</a> <span class="text-muted"></span> <a class="tag" taget="_blank" href="/search/python%E5%90%8E%E7%AB%AF/1.htm">python后端</a> <div>最近用思源笔记记东西上瘾,突然想每个月存一份收支记录进去。但手动整理账单太麻烦了,支付宝导出一份CSV,微信又导出一份,格式还不一样,每次复制粘贴头都大。干脆写了个Python脚本一键处理,核心就干两件事:把俩平台的CSV账单合并到一起自动生成带分类表格的Markdown(直接拖进思源就能渲染)代码主要折腾了这些:支付宝账单前24行都是废话,直接skiprows=24跳过去,GBK编码差点让我栽跟</div> </li> <li><a href="/article/1899298673951567872.htm" title="Python Flask 在网页应用程序中处理错误和异常" target="_blank">Python Flask 在网页应用程序中处理错误和异常</a> <span class="text-muted">dowhileprogramming</span> <a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/flask/1.htm">flask</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a> <div>PythonFlask在网页应用程序中处理错误和异常PythonFlask在网页应用程序中处理错误和异常PythonFlask在网页应用程序中处理错误和异常在我们所有的代码示例中,我们没有注意如何处理用户在浏览器中输入错误的URL或向我们的应用程序发送错误的参数集的情况。这不是设计意图,但目的是首先关注网页应用程序的关键组件。网页框架的美妙之处在于,它们通常默认支持错误处理。如果发生任何错误,将自</div> </li> <li><a href="/article/1899296658152288256.htm" title="农业生产模拟和农业政策分析:WOFOST模型与PCSE模型安装、运行、数据准备;农田农作物生长模拟和产量预测等" target="_blank">农业生产模拟和农业政策分析:WOFOST模型与PCSE模型安装、运行、数据准备;农田农作物生长模拟和产量预测等</a> <span class="text-muted">WangYan2022</span> <a class="tag" taget="_blank" href="/search/%E4%BD%9C%E7%89%A9%E6%A8%A1%E5%9E%8B/1.htm">作物模型</a><a class="tag" taget="_blank" href="/search/%E5%86%9C%E4%B8%9A/1.htm">农业</a><a class="tag" taget="_blank" href="/search/WOFOST%E6%A8%A1%E5%9E%8B/1.htm">WOFOST模型</a><a class="tag" taget="_blank" href="/search/PCSE%E6%A8%A1%E5%9E%8B/1.htm">PCSE模型</a><a class="tag" taget="_blank" href="/search/%E5%86%9C%E7%94%B0%E7%94%9F%E6%80%81%E7%B3%BB%E7%BB%9F/1.htm">农田生态系统</a><a class="tag" taget="_blank" href="/search/%E4%BD%9C%E7%89%A9%E6%A8%A1%E5%9E%8B/1.htm">作物模型</a><a class="tag" taget="_blank" href="/search/%E5%86%9C%E4%B8%9A%E7%94%9F%E4%BA%A7%E6%A8%A1%E6%8B%9F/1.htm">农业生产模拟</a> <div>WOFOST(WorldFoodStudies)和PCSE(PythonCropSimulationEnvironment)是两个用于农业生产模拟的模型:WOFOST是一个经过多年开发和验证的模型,被广泛用于全球的农业生产模拟和农业政策分析;采用了模块化的结构,可以对不同的农作物和环境条件进行参数化和适应;WOFOST可用于长期模拟,能够模拟整个作物生长周期,包括播种、生长、收获等各个阶段;WOF</div> </li> <li><a href="/article/16.htm" title="深入浅出Java Annotation(元注解和自定义注解)" target="_blank">深入浅出Java Annotation(元注解和自定义注解)</a> <span class="text-muted">Josh_Persistence</span> <a class="tag" taget="_blank" href="/search/Java+Annotation/1.htm">Java Annotation</a><a class="tag" taget="_blank" href="/search/%E5%85%83%E6%B3%A8%E8%A7%A3/1.htm">元注解</a><a class="tag" taget="_blank" href="/search/%E8%87%AA%E5%AE%9A%E4%B9%89%E6%B3%A8%E8%A7%A3/1.htm">自定义注解</a> <div>一、基本概述 Annontation是Java5开始引入的新特征。中文名称一般叫注解。它提供了一种安全的类似注释的机制,用来将任何的信息或元数据(metadata)与程序元素(类、方法、成员变量等)进行关联。 更通俗的意思是为程序的元素(类、方法、成员变量)加上更直观更明了的说明,这些说明信息是与程序的业务逻辑无关,并且是供指定的工具或</div> </li> <li><a href="/article/143.htm" title="mysql优化特定类型的查询" target="_blank">mysql优化特定类型的查询</a> <span class="text-muted">annan211</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a> <div> 本节所介绍的查询优化的技巧都是和特定版本相关的,所以对于未来mysql的版本未必适用。 1 优化count查询 对于count这个函数的网上的大部分资料都是错误的或者是理解的都是一知半解的。在做优化之前我们先来看看 真正的count()函数的作用到底是什么。 count()是一个特殊的函数,有两种非常不同的作用,他可以统计某个列值的数量,也可以统计行数。 在统</div> </li> <li><a href="/article/270.htm" title="MAC下安装多版本JDK和切换几种方式" target="_blank">MAC下安装多版本JDK和切换几种方式</a> <span class="text-muted">棋子chessman</span> <a class="tag" taget="_blank" href="/search/jdk/1.htm">jdk</a> <div>环境: MAC AIR,OS X 10.10,64位 历史: 过去 Mac 上的 Java 都是由 Apple 自己提供,只支持到 Java 6,并且OS X 10.7 开始系统并不自带(而是可选安装)(原自带的是1.6)。 后来 Apple 加入 OpenJDK 继续支持 Java 6,而 Java 7 将由 Oracle 负责提供。 在终端中输入jav</div> </li> <li><a href="/article/397.htm" title="javaScript (1)" target="_blank">javaScript (1)</a> <span class="text-muted">Array_06</span> <a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E6%B5%8F%E8%A7%88%E5%99%A8/1.htm">浏览器</a> <div>JavaScript 1、运算符 运算符就是完成操作的一系列符号,它有七类: 赋值运算符(=,+=,-=,*=,/=,%=,<<=,>>=,|=,&=)、算术运算符(+,-,*,/,++,--,%)、比较运算符(>,<,<=,>=,==,===,!=,!==)、逻辑运算符(||,&&,!)、条件运算(?:)、位</div> </li> <li><a href="/article/524.htm" title="国内顶级代码分享网站" target="_blank">国内顶级代码分享网站</a> <span class="text-muted">袁潇含</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/jdk/1.htm">jdk</a><a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/.net/1.htm">.net</a><a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a> <div> 现在国内很多开源网站感觉都是为了利益而做的 当然利益是肯定的,否则谁也不会免费的去做网站 &</div> </li> <li><a href="/article/651.htm" title="Elasticsearch、MongoDB和Hadoop比较" target="_blank">Elasticsearch、MongoDB和Hadoop比较</a> <span class="text-muted">随意而生</span> <a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a><a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a><a class="tag" taget="_blank" href="/search/%E6%90%9C%E7%B4%A2%E5%BC%95%E6%93%8E/1.htm">搜索引擎</a> <div> IT界在过去几年中出现了一个有趣的现象。很多新的技术出现并立即拥抱了“大数据”。稍微老一点的技术也会将大数据添进自己的特性,避免落大部队太远,我们看到了不同技术之间的边际的模糊化。假如你有诸如Elasticsearch或者Solr这样的搜索引擎,它们存储着JSON文档,MongoDB存着JSON文档,或者一堆JSON文档存放在一个Hadoop集群的HDFS中。你可以使用这三种配</div> </li> <li><a href="/article/778.htm" title="mac os 系统科研软件总结" target="_blank">mac os 系统科研软件总结</a> <span class="text-muted">张亚雄</span> <a class="tag" taget="_blank" href="/search/mac+os/1.htm">mac os</a> <div>1.1 Microsoft Office for Mac 2011 大客户版,自行搜索。 1.2 Latex (MacTex): 系统环境:https://tug.org/mactex/ &nb</div> </li> <li><a href="/article/905.htm" title="Maven实战(四)生命周期" target="_blank">Maven实战(四)生命周期</a> <span class="text-muted">AdyZhang</span> <a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a> <div>1. 三套生命周期 Maven拥有三套相互独立的生命周期,它们分别为clean,default和site。 每个生命周期包含一些阶段,这些阶段是有顺序的,并且后面的阶段依赖于前面的阶段,用户和Maven最直接的交互方式就是调用这些生命周期阶段。 以clean生命周期为例,它包含的阶段有pre-clean, clean 和 post</div> </li> <li><a href="/article/1032.htm" title="Linux下Jenkins迁移" target="_blank">Linux下Jenkins迁移</a> <span class="text-muted">aijuans</span> <a class="tag" taget="_blank" href="/search/Jenkins/1.htm">Jenkins</a> <div>1. 将Jenkins程序目录copy过去 源程序在/export/data/tomcatRoot/ofctest-jenkins.jd.com下面 tar -cvzf jenkins.tar.gz ofctest-jenkins.jd.com &</div> </li> <li><a href="/article/1159.htm" title="request.getInputStream()只能获取一次的问题" target="_blank">request.getInputStream()只能获取一次的问题</a> <span class="text-muted">ayaoxinchao</span> <a class="tag" taget="_blank" href="/search/request/1.htm">request</a><a class="tag" taget="_blank" href="/search/Inputstream/1.htm">Inputstream</a> <div>问题:在使用HTTP协议实现应用间接口通信时,服务端读取客户端请求过来的数据,会用到request.getInputStream(),第一次读取的时候可以读取到数据,但是接下来的读取操作都读取不到数据 原因: 1. 一个InputStream对象在被读取完成后,将无法被再次读取,始终返回-1; 2. InputStream并没有实现reset方法(可以重</div> </li> <li><a href="/article/1286.htm" title="数据库SQL优化大总结之 百万级数据库优化方案" target="_blank">数据库SQL优化大总结之 百万级数据库优化方案</a> <span class="text-muted">BigBird2012</span> <a class="tag" taget="_blank" href="/search/SQL%E4%BC%98%E5%8C%96/1.htm">SQL优化</a> <div>网上关于SQL优化的教程很多,但是比较杂乱。近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充。 这篇文章我花费了大量的时间查找资料、修改、排版,希望大家阅读之后,感觉好的话推荐给更多的人,让更多的人看到、纠正以及补充。 1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where </div> </li> <li><a href="/article/1413.htm" title="jsonObject的使用" target="_blank">jsonObject的使用</a> <span class="text-muted">bijian1013</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/json/1.htm">json</a> <div> 在项目中难免会用java处理json格式的数据,因此封装了一个JSONUtil工具类。 JSONUtil.java package com.bijian.json.study; import java.util.ArrayList; import java.util.Date; import java.util.HashMap;</div> </li> <li><a href="/article/1540.htm" title="[Zookeeper学习笔记之六]Zookeeper源代码分析之Zookeeper.WatchRegistration" target="_blank">[Zookeeper学习笔记之六]Zookeeper源代码分析之Zookeeper.WatchRegistration</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a> <div>Zookeeper类是Zookeeper提供给用户访问Zookeeper service的主要API,它包含了如下几个内部类 首先分析它的内部类,从WatchRegistration开始,为指定的znode path注册一个Watcher, /** * Register a watcher for a particular p</div> </li> <li><a href="/article/1667.htm" title="【Scala十三】Scala核心七:部分应用函数" target="_blank">【Scala十三】Scala核心七:部分应用函数</a> <span class="text-muted">bit1129</span> <a class="tag" taget="_blank" href="/search/scala/1.htm">scala</a> <div>何为部分应用函数? Partially applied function: A function that’s used in an expression and that misses some of its arguments.For instance, if function f has type Int => Int => Int, then f and f(1) are p</div> </li> <li><a href="/article/1794.htm" title="Tomcat Error listenerStart 终极大法" target="_blank">Tomcat Error listenerStart 终极大法</a> <span class="text-muted">ronin47</span> <a class="tag" taget="_blank" href="/search/tomcat/1.htm">tomcat</a> <div>Tomcat报的错太含糊了,什么错都没报出来,只提示了Error listenerStart。为了调试,我们要获得更详细的日志。可以在WEB-INF/classes目录下新建一个文件叫logging.properties,内容如下 Java代码 handlers = org.apache.juli.FileHandler, java.util.logging.ConsoleHa</div> </li> <li><a href="/article/1921.htm" title="不用加减符号实现加减法" target="_blank">不用加减符号实现加减法</a> <span class="text-muted">BrokenDreams</span> <a class="tag" taget="_blank" href="/search/%E5%AE%9E%E7%8E%B0/1.htm">实现</a> <div> 今天有群友发了一个问题,要求不用加减符号(包括负号)来实现加减法。 分析一下,先看最简单的情况,假设1+1,按二进制算的话结果是10,可以看到从右往左的第一位变为0,第二位由于进位变为1。 </div> </li> <li><a href="/article/2048.htm" title="读《研磨设计模式》-代码笔记-状态模式-State" target="_blank">读《研磨设计模式》-代码笔记-状态模式-State</a> <span class="text-muted">bylijinnan</span> <a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a> <div>声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/ /* 当一个对象的内在状态改变时允许改变其行为,这个对象看起来像是改变了其类 状态模式主要解决的是当控制一个对象状态的条件表达式过于复杂时的情况 把状态的判断逻辑转移到表示不同状态的一系列类中,可以把复杂的判断逻辑简化 如果在</div> </li> <li><a href="/article/2175.htm" title="CUDA程序block和thread超出硬件允许值时的异常" target="_blank">CUDA程序block和thread超出硬件允许值时的异常</a> <span class="text-muted">cherishLC</span> <a class="tag" taget="_blank" href="/search/CUDA/1.htm">CUDA</a> <div>调用CUDA的核函数时指定block 和 thread大小,该大小可以是dim3类型的(三维数组),只用一维时可以是usigned int型的。 以下程序验证了当block或thread大小超出硬件允许值时会产生异常!!!GPU根本不会执行运算!!! 所以验证结果的正确性很重要!!! 在VS中创建CUDA项目会有一个模板,里面有更详细的状态验证。 以下程序在K5000GPU上跑的。</div> </li> <li><a href="/article/2302.htm" title="诡异的超长时间GC问题定位" target="_blank">诡异的超长时间GC问题定位</a> <span class="text-muted">chenchao051</span> <a class="tag" taget="_blank" href="/search/jvm/1.htm">jvm</a><a class="tag" taget="_blank" href="/search/cms/1.htm">cms</a><a class="tag" taget="_blank" href="/search/GC/1.htm">GC</a><a class="tag" taget="_blank" href="/search/hbase/1.htm">hbase</a><a class="tag" taget="_blank" href="/search/swap/1.htm">swap</a> <div>HBase的GC策略采用PawNew+CMS, 这是大众化的配置,ParNew经常会出现停顿时间特别长的情况,有时候甚至长到令人发指的地步,例如请看如下日志: 2012-10-17T05:54:54.293+0800: 739594.224: [GC 739606.508: [ParNew: 996800K->110720K(996800K), 178.8826900 secs] 3700</div> </li> <li><a href="/article/2429.htm" title="maven环境快速搭建" target="_blank">maven环境快速搭建</a> <span class="text-muted">daizj</span> <a class="tag" taget="_blank" href="/search/%E5%AE%89%E8%A3%85/1.htm">安装</a><a class="tag" taget="_blank" href="/search/mavne/1.htm">mavne</a><a class="tag" taget="_blank" href="/search/%E7%8E%AF%E5%A2%83%E9%85%8D%E7%BD%AE/1.htm">环境配置</a> <div>一 下载maven 安装maven之前,要先安装jdk及配置JAVA_HOME环境变量。这个安装和配置java环境不用多说。 maven下载地址:http://maven.apache.org/download.html,目前最新的是这个apache-maven-3.2.5-bin.zip,然后解压在任意位置,最好地址中不要带中文字符,这个做java 的都知道,地址中出现中文会出现很多</div> </li> <li><a href="/article/2556.htm" title="PHP网站安全,避免PHP网站受到攻击的方法" target="_blank">PHP网站安全,避免PHP网站受到攻击的方法</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a> <div> 对于PHP网站安全主要存在这样几种攻击方式:1、命令注入(Command Injection)2、eval注入(Eval Injection)3、客户端脚本攻击(Script Insertion)4、跨网站脚本攻击(Cross Site Scripting, XSS)5、SQL注入攻击(SQL injection)6、跨网站请求伪造攻击(Cross Site Request Forgerie</div> </li> <li><a href="/article/2683.htm" title="yii中给CGridView设置默认的排序根据时间倒序的方法" target="_blank">yii中给CGridView设置默认的排序根据时间倒序的方法</a> <span class="text-muted">dcj3sjt126com</span> <a class="tag" taget="_blank" href="/search/GridView/1.htm">GridView</a> <div>public function searchWithRelated() { $criteria = new CDbCriteria; $criteria->together = true; //without th</div> </li> <li><a href="/article/2810.htm" title="Java集合对象和数组对象的转换" target="_blank">Java集合对象和数组对象的转换</a> <span class="text-muted">dyy_gusi</span> <a class="tag" taget="_blank" href="/search/java%E9%9B%86%E5%90%88/1.htm">java集合</a> <div> 在开发中,我们经常需要将集合对象(List,Set)转换为数组对象,或者将数组对象转换为集合对象。Java提供了相互转换的工具,但是我们使用的时候需要注意,不能乱用滥用。 1、数组对象转换为集合对象 最暴力的方式是new一个集合对象,然后遍历数组,依次将数组中的元素放入到新的集合中,但是这样做显然过</div> </li> <li><a href="/article/2937.htm" title="nginx同一主机部署多个应用" target="_blank">nginx同一主机部署多个应用</a> <span class="text-muted">geeksun</span> <a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a> <div>近日有一需求,需要在一台主机上用nginx部署2个php应用,分别是wordpress和wiki,探索了半天,终于部署好了,下面把过程记录下来。 1. 在nginx下创建vhosts目录,用以放置vhost文件。 mkdir vhosts 2. 修改nginx.conf的配置, 在http节点增加下面内容设置,用来包含vhosts里的配置文件 #</div> </li> <li><a href="/article/3064.htm" title="ubuntu添加admin权限的用户账号" target="_blank">ubuntu添加admin权限的用户账号</a> <span class="text-muted">hongtoushizi</span> <a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a><a class="tag" taget="_blank" href="/search/useradd/1.htm">useradd</a> <div>ubuntu创建账号的方式通常用到两种:useradd 和adduser . 本人尝试了useradd方法,步骤如下: 1:useradd 使用useradd时,如果后面不加任何参数的话,如:sudo useradd sysadm 创建出来的用户将是默认的三无用户:无home directory ,无密码,无系统shell。 顾应该如下操作: </div> </li> <li><a href="/article/3191.htm" title="第五章 常用Lua开发库2-JSON库、编码转换、字符串处理" target="_blank">第五章 常用Lua开发库2-JSON库、编码转换、字符串处理</a> <span class="text-muted">jinnianshilongnian</span> <a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/lua/1.htm">lua</a> <div> JSON库 在进行数据传输时JSON格式目前应用广泛,因此从Lua对象与JSON字符串之间相互转换是一个非常常见的功能;目前Lua也有几个JSON库,本人用过cjson、dkjson。其中cjson的语法严格(比如unicode \u0020\u7eaf),要求符合规范否则会解析失败(如\u002),而dkjson相对宽松,当然也可以通过修改cjson的源码来完成</div> </li> <li><a href="/article/3318.htm" title="Spring定时器配置的两种实现方式OpenSymphony Quartz和java Timer详解" target="_blank">Spring定时器配置的两种实现方式OpenSymphony Quartz和java Timer详解</a> <span class="text-muted">yaerfeng1989</span> <a class="tag" taget="_blank" href="/search/timer/1.htm">timer</a><a class="tag" taget="_blank" href="/search/quartz/1.htm">quartz</a><a class="tag" taget="_blank" href="/search/%E5%AE%9A%E6%97%B6%E5%99%A8/1.htm">定时器</a> <div>原创整理不易,转载请注明出处:Spring定时器配置的两种实现方式OpenSymphony Quartz和java Timer详解 代码下载地址:http://www.zuidaima.com/share/1772648445103104.htm 有两种流行Spring定时器配置:Java的Timer类和OpenSymphony的Quartz。 1.Java Timer定时 首先继承jav</div> </li> <li><a href="/article/3445.htm" title="Linux下df与du两个命令的差别?" target="_blank">Linux下df与du两个命令的差别?</a> <span class="text-muted">pda158</span> <a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a> <div> 一、df显示文件系统的使用情况,与du比較,就是更全盘化。 最经常使用的就是 df -T,显示文件系统的使用情况并显示文件系统的类型。 举比例如以下: [root@localhost ~]# df -T Filesystem Type &n</div> </li> <li><a href="/article/3572.htm" title="[转]SQLite的工具类 ---- 通过反射把Cursor封装到VO对象" target="_blank">[转]SQLite的工具类 ---- 通过反射把Cursor封装到VO对象</a> <span class="text-muted">ctfzh</span> <a class="tag" taget="_blank" href="/search/VO/1.htm">VO</a><a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/sqlite/1.htm">sqlite</a><a class="tag" taget="_blank" href="/search/%E5%8F%8D%E5%B0%84/1.htm">反射</a><a class="tag" taget="_blank" href="/search/Cursor/1.htm">Cursor</a> <div>在写DAO层时,觉得从Cursor里一个一个的取出字段值再装到VO(值对象)里太麻烦了,就写了一个工具类,用到了反射,可以把查询记录的值装到对应的VO里,也可以生成该VO的List。 使用时需要注意: 考虑到Android的性能问题,VO没有使用Setter和Getter,而是直接用public的属性。 表中的字段名需要和VO的属性名一样,要是不一样就得在查询的SQL中</div> </li> <li><a href="/article/3699.htm" title="该学习笔记用到的Employee表" target="_blank">该学习笔记用到的Employee表</a> <span class="text-muted">vipbooks</span> <a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/%E5%B7%A5%E4%BD%9C/1.htm">工作</a> <div> 这是我在学习Oracle是用到的Employee表,在该笔记中用到的就是这张表,大家可以用它来学习和练习。 drop table Employee; -- 员工信息表 create table Employee( -- 员工编号 EmpNo number(3) primary key, -- 姓</div> </li> </ul> </div> </div> </div> <div> <div class="container"> <div class="indexes"> <strong>按字母分类:</strong> <a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a> </div> </div> </div> <footer id="footer" class="mb30 mt30"> <div class="container"> <div class="footBglm"> <a target="_blank" href="/">首页</a> - <a target="_blank" href="/custom/about.htm">关于我们</a> - <a target="_blank" href="/search/Java/1.htm">站内搜索</a> - <a target="_blank" href="/sitemap.txt">Sitemap</a> - <a target="_blank" href="/custom/delete.htm">侵权投诉</a> </div> <div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved. <!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>--> </div> </div> </footer> <!-- 代码高亮 --> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script> <script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script> <link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/> <script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script> </body> </html>