【Python学习笔记】4:求Pi的近似值,求反向对,统计文件中单词出现的频率
今天这三道不算是算法题,算是熟悉一下python中的精度控制和文件读操作。
求Pi的近似值
题目描述:编写循环控制代码用下面公式逼近圆周率(精确到小数点后15位),并且和math.pi的值做比较。
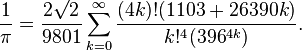
import math
def JC(r):
num=1
for i in range(1,r+1):
num*=i
return num
def main():
p=math.sqrt(8)/9801
sumk=0.0
for k in range(0,200):
sumk+=JC(4*k)*(1103+26390*k)/(JC(k)**4*396**(4*k))
a="%.17f"%(sumk*p)
print (a)
b="%.17f"%(1/math.pi)
print (b)
main()运行结果:
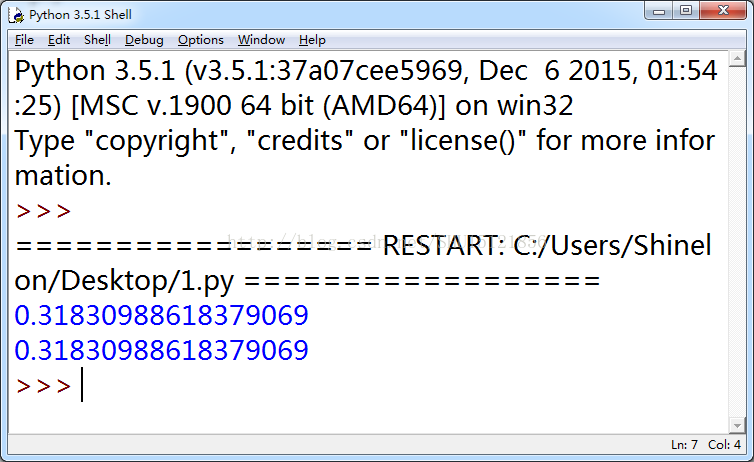
这里先加入了一个math包以调用其中的pi属性和sqrt()方法。首先在主函数中,将Σ前的系数存入p中,初始化sumk=0.0以存放Σ运算实时的结果。因为不知道k取多大满足精度,这里先取了k从0~199进行运算。只要将sumk加上Σ内的表达式即可。表达式中用到的方法JC()是用来求阶乘的自定义方法,该方法一开始用了递归实现但是内存占用太大而且速度也不快,现在改成了迭代求解。这里a="%.17f"%(sumk*p)即是将sumk*p的值保留17位放入a中,如果其精度不足17位后面的值将没有意义。
在本题求解后,将range(0,200)改为range(0,300)运行发现结果没有改变,说明满足了精度要求。
求反向对
题目描述:如果一个单词是另一个单词的反向序列,则称这两个单词为“反向对”。编写代码输出一个文件中中词汇表包含的反向对。
f=open("te.txt")
r=f.read()
b=[]
a=[]
for j in r.split():
if j not in a and j not in b:
pj=j[::-1]
if pj in r.split():
a.append(j)
b.append(pj)
c=zip(a,b)
for j in c:
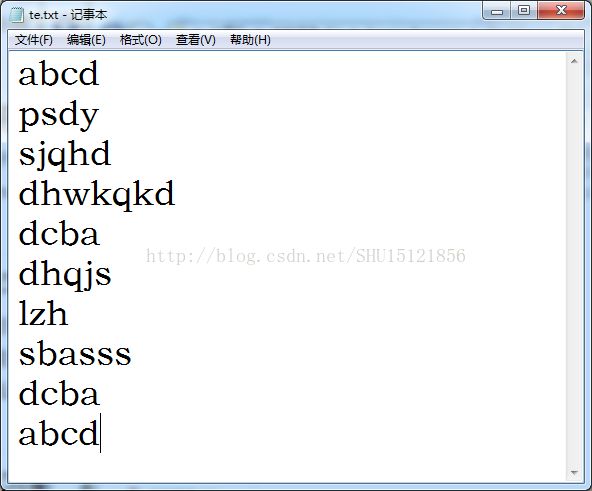
print (j)建立的词汇表文件:
运行结果:
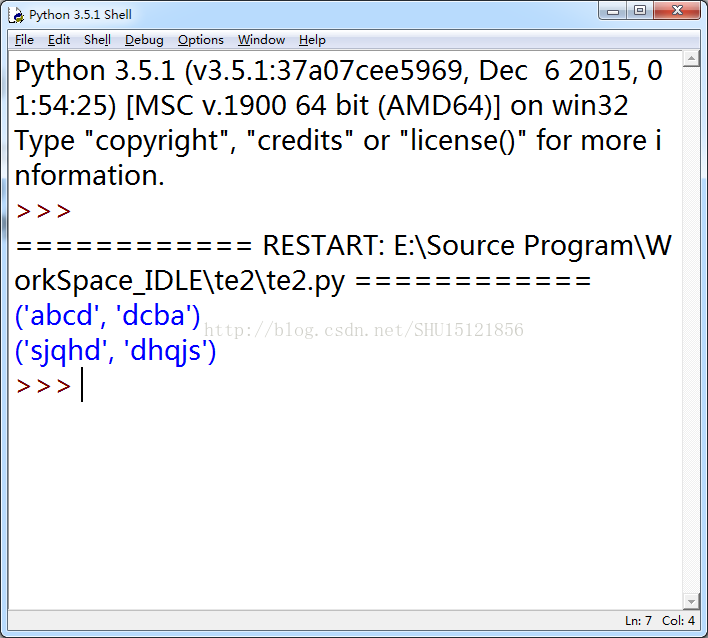
这里用split()函数将词汇表中的单词按空白符(此处是换行)分开,然后建立了a和b两个list用来存放找到的正向和反向的单词,如果新找到这样的单词在a和b中都没有,就把它append进去。最后用zip变形转置,就可以一对一对地输出了。
如果文件过大,运行将变得极其慢甚至始终不能看到结果。这题我还没找到简便的算法。
统计文件中单词出现的频率
题目描述:设计Python程序读入一个英文单词组成的文本文件,统计其中包含的某给定关键词列表中各个单词出现的频率。设计测试用例验证代码的正确性。
lzh=['Chinese','friends','isolation','She','desperation','flora']
lzh2=[0,0,0,0,0,0]
f=open('op2.txt')
str_mwj=list(f.read().split(' '))
for i in str_mwj:
for k in i.split('.'):
for j in k.split(','):
if j!='' and j!=' ' and j in lzh:
lzh2[lzh.index(j)]+=1
for k,v in zip(lzh,lzh2):
print (k,'出现了',v,'次')建立的英文文章:

运行结果:
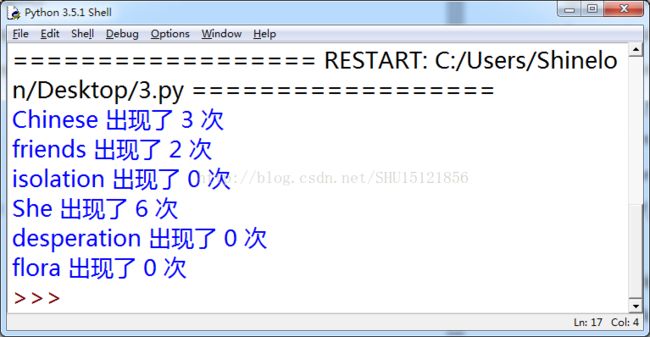
首先将所有要查找的字符串放入列表lzh中,然后建立一个列表lzh2存放每个字符串找到的次数(初始都为0)。用open()打开一个文件并返回该文件的文件对象给f,则f.read()返回的就是整个文件中的所有字符形成的字符串。对这个字符串用split()方法按空格分割成一些单词,但这些单词可能还会有’.’或者’,’相连。所以再作两个循环将单词用’.’和’,’隔开。这时候得到的单词就已经是完整的单词了,但是还是会有’’或’ ’这样的不合法串的出现。因此在判定中将其消去,然后用zip()变形转置输出即可。