pytorch基础入门一: 训练原始的线性模型
pytorch基础入门一: 训练原始的线性模型
Backgroud 背景说明
由于公司业务需要(基于单张全景图的三维场景重建),从五一开始拾起了神经网络的学习;嗯!这个月的flag就是五月份完成业务模型的技术验证;
搜索到的几篇文章,都是基于PyTorch搭建的模型,那理所当然也就踏入PyTorch的世界;按照以往的学习习惯,一切从官网文档开始入手;
看 官网入门指南 第一节讲tensor的主要操作,这一部分理解起来问题不大,就是一些细节需要在具体使用中熟悉;
第二节 AUTOGRAD 自动求导,也能明白个大概 ;到第三节的时候,直接扑面而来的新对象
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 1 input image channel, 6 output channels, 3x3 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 3)
self.conv2 = nn.Conv2d(6, 16, 3)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 6 * 6, 120) # 6*6 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
简直 懵逼树上懵逼果,懵逼树下你和我
那只能暂时放下tutorials,我胡汉三还会再回来的
然后,就找官方出版的开源书籍 Deep-Learning-with-PyTorch
第一章 介绍PyTorch概况,一眼带过
第二章 讲述 tensor 的底层实现,果然比 tutorials 详尽充实多了,看来这本书适合概念建立;
第三章 介绍输入数据的处理,也暂时跳过
第四章 神经网络学习机制的介绍,看到这就知道这章就是适合我的
所以本篇文章主要记录, Deep-Learning-with-PyTorch 书中第四章内容,包括以下几点:
- 定义一个线性模型
- 定义线性模型的损失函数(代价函数)
- 实现线性模型的梯度回归
- 学习速率的调试
- 特征值的缩放
定义线性模型
假设的问题如下:
现在有两种类型的温度计,一个是已知单位,另一个是未知单位的温度计,需要拟合两种温度计的换算公式
作最简单的假设,换算公式为线性的:
# 对应的线性模型为
# t_c = w * t_u + b
对应的代码如下:
"""
PyTorch 基础入门
线性回归参数估计
问题: 华氏温度转换
"""
import torch
# 定义输入数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
# 对应的线性模型为
# t_c = w * t_u + b
def model(t_u, w, b):
return w*t_u + b
定义损失函数
损失函数是用来判断模型参数拟合实验数据优劣的一个方法,所以损失函数也会存在多种多样,比如;
针对我们的问题,可以列出两种损失函数:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fvdrfn70-1589179469322)(https://cdn.jsdelivr.net/gh/austinxishou/pics/feimao/20200511134915.png)]
左边为 预估数据与实验数据的距离
右边为 预估数据与实验数据的距离平方
如果不绕弯子,直接给出结论的话,右边损失函数会优于左边的损失函数;
简单的解释为: 距离的平方 会在偏离正确数据时给出较大的偏差惩罚;数学上理解为,左边的斜率保持一个常数,右边的斜率是越偏离x0,斜率越大
python代码实现的损失函数如下:
# 定义损失函数
# t_p 为模型估计值
# t_c 为实验数据
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
线性模型的梯度回归
梯度回归的基本原理,就用一张图解释,详细的参考其他说明资料
图片引用自 吴恩达大神的经典课程 <
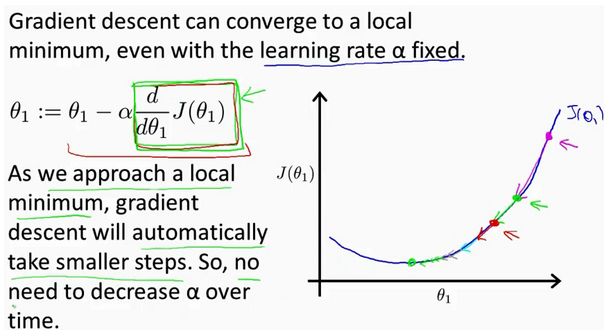
翻译为 Python语言如下:
# 损失函数对w求导
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u, w + delta, b), t_c) -
loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
# 更新 w
learning_rate = 1e-2
w = w - learning_rate * loss_rate_of_change_w
# 损失函数对b求导
loss_rate_of_change_b = \
(loss_fn(model(t_u, w, b + delta), t_c) -
loss_fn(model(t_u, w, b - delta), t_c)) / (2.0 * delta)
# 更新 b
b = b - learning_rate * loss_rate_of_change_b
把上述过程放到 loop循环中,就构成了实验数据的学习过程
求导的数学微分表示
在我们的假设模型中,线性模型和损失函数都是可微的,所以可以用数学的求导公式进行表示
# 通过求导公式进行求导
def dloss_fn(t_p, t_c):
dsq_diffs = 2 * (t_p - t_c)
return dsq_diffs
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dw = dloss_fn(t_p, t_c) * dmodel_dw(t_u, w, b)
dloss_db = dloss_fn(t_p, t_c) * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.mean(), dloss_db.mean()])
把上述过程放到 loop循环中,同样构成了实验数据的学习过程
定义迭代过程
整合以上几步,实现loop循环
# 定义迭代过程
# n_epochs 迭代次数
# learning_rate 学习速率
# params 模型参数 这里为 w,b
# t_u, t_c 实验数据
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' % (epoch, float(loss)))
print('Params', params)
print('Grad', grad)
return params
其中的迭代次数需要特别说明下,模型的学习可以设置不同的停止学习的条件,在这里我们直接用写死的迭代次数作为终止条件
学习速率的调试
到目前为止我们完整的代码如下,可以直接运行评估下模型情况:
"""
PyTorch 基础入门
线性回归参数估计
问题: 华氏温度转换
"""
import torch
# 定义输入数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
# 对应的线性模型为
# t_c = w * t_u + b
def model(t_u, w, b):
return w*t_u + b
# 定义损失函数
# t_p 为模型估计值
# t_c 为实验数据
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
w = torch.ones(1)
b = torch.zeros(1)
t_p = model(t_u, w, b)
print(t_p)
# 计算损失函数
loss = loss_fn(t_p, t_c)
print(loss)
# 损失函数对w求导
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u, w + delta, b), t_c) -
loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
learning_rate = 1e-2
w = w - learning_rate * loss_rate_of_change_w
loss_rate_of_change_b = \
(loss_fn(model(t_u, w, b + delta), t_c) -
loss_fn(model(t_u, w, b - delta), t_c)) / (2.0 * delta)
b = b - learning_rate * loss_rate_of_change_b
# 通过求导公式进行求导
def dloss_fn(t_p, t_c):
dsq_diffs = 2 * (t_p - t_c)
return dsq_diffs
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dw = dloss_fn(t_p, t_c) * dmodel_dw(t_u, w, b)
dloss_db = dloss_fn(t_p, t_c) * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.mean(), dloss_db.mean()])
# 定义迭代过程
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' % (epoch, float(loss)))
print('Params', params)
print('Grad', grad)
return params
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_u,
t_c = t_c)
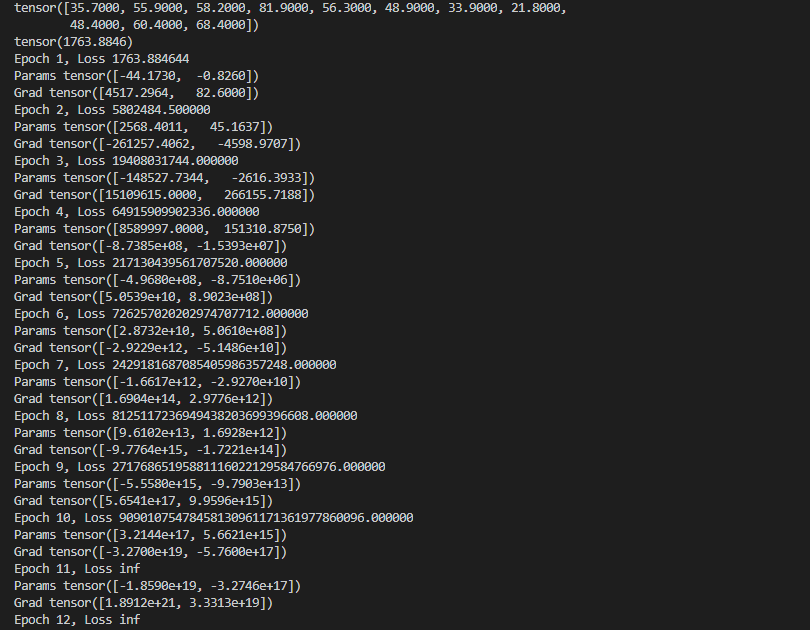
运行后会发现,梯度回归是发散,并没有收敛
运行截图:
这其中的根本问题就是 学习速率太大 导致模型震荡,用图说明就是如下:
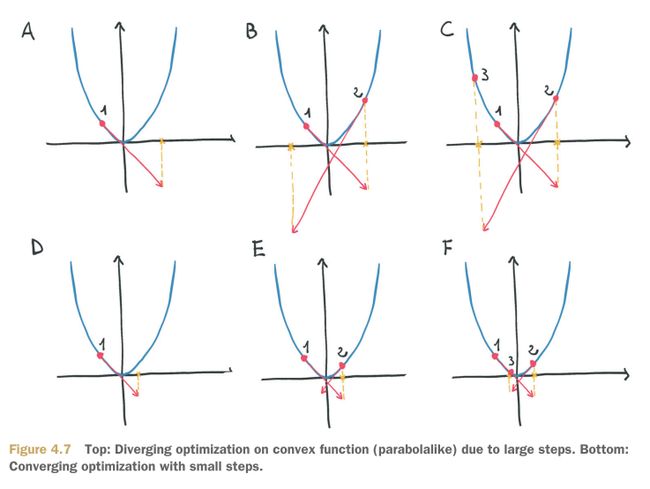
所以如何选择 学习速率, 在 < 中也有详细的说明,总结就是两点:
- 太大的学习速率会导致梯度下降震荡
- 太小的学习速率会导致梯度下降太慢,计算次数变多
所谓大小,一般可以在 0.0001 0.001 0.01 0.02 0.05 0.1 0.2 0.5 … 等类似取值
所以我们修改 学习速率 learning_rate = 1e-4,重新跑一遍代码
Epoch 98, Loss 29.024494
Params tensor([ 0.2327, -0.0432])
Grad tensor([-0.0533, 3.0227])
Epoch 99, Loss 29.023582
Params tensor([ 0.2327, -0.0435])
Grad tensor([-0.0533, 3.0226])
Epoch 100, Loss 29.022669
Params tensor([ 0.2327, -0.0438])
Grad tensor([-0.0532, 3.0226])
迭代一百次后,损失函数的返回值变化就已经很小了,到此,一个最原始的Python语言实现的线性回归差不多就完成了
特征值缩放
为什么需要这个,一个通俗的解释就是:
上面说的学习速率 learning_rate,不管取什么值,总是无法匹配两个参数w和b
- 对w合适的 learning_rate ,对于b来说太小了
- 对b合适的 learning_rate ,对于w来说太大了
所以需要对 相应的特征值输入进行缩放,在我们这个例子中,可以:
# 特征缩放处理
t_un = 0.1 * t_u
training_loop(
n_epochs = 100,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c)
然后我们增加迭代次数:
t_un = 0.1 * t_u
params = training_loop(
n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c)
运行后的结果如下:
Epoch 4996, Loss 2.927648
Params tensor([ 5.3671, -17.3012])
Grad tensor([-0.0001, 0.0006])
Epoch 4997, Loss 2.927647
Params tensor([ 5.3671, -17.3012])
Grad tensor([-0.0001, 0.0006])
Epoch 4998, Loss 2.927647
Params tensor([ 5.3671, -17.3012])
Grad tensor([-0.0001, 0.0006])
Epoch 4999, Loss 2.927647
Params tensor([ 5.3671, -17.3012])
Grad tensor([-0.0001, 0.0006])
Epoch 5000, Loss 2.927648
Params tensor([ 5.3671, -17.3012])
Grad tensor([-0.0001, 0.0006])
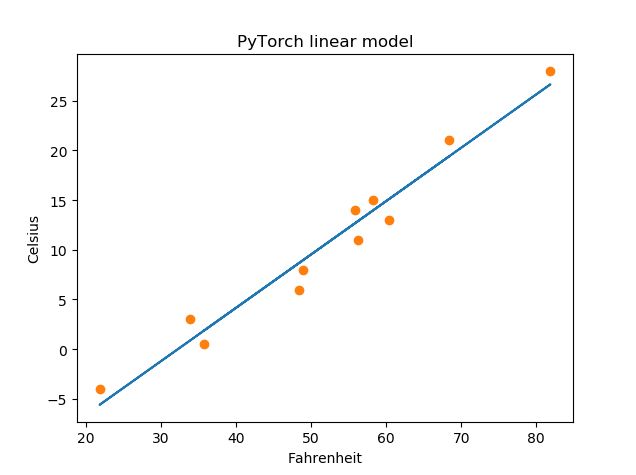
结果
最后说下,这篇文章实现的最原始的Python线性回归实现,并不是PyTorch的标准实现;
所以下一篇会讲 基于 PyTorch AutoGrade 实现的线性模型回归
完整代码如下:
"""
PyTorch 基础入门
线性回归参数估计
问题: 华氏温度转换
"""
import torch
# 定义输入数据
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
# 对应的线性模型为
# t_c = w * t_u + b
def model(t_u, w, b):
return w*t_u + b
# 定义损失函数
# t_p 为模型估计值
# t_c 为实验数据
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
return squared_diffs.mean()
w = torch.ones(1)
b = torch.zeros(1)
t_p = model(t_u, w, b)
print(t_p)
# 计算损失函数
loss = loss_fn(t_p, t_c)
print(loss)
# 损失函数对w求导
delta = 0.1
loss_rate_of_change_w = \
(loss_fn(model(t_u, w + delta, b), t_c) -
loss_fn(model(t_u, w - delta, b), t_c)) / (2.0 * delta)
learning_rate = 1e-2
w = w - learning_rate * loss_rate_of_change_w
loss_rate_of_change_b = \
(loss_fn(model(t_u, w, b + delta), t_c) -
loss_fn(model(t_u, w, b - delta), t_c)) / (2.0 * delta)
b = b - learning_rate * loss_rate_of_change_b
# 通过求导公式进行求导
def dloss_fn(t_p, t_c):
dsq_diffs = 2 * (t_p - t_c)
return dsq_diffs
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dw = dloss_fn(t_p, t_c) * dmodel_dw(t_u, w, b)
dloss_db = dloss_fn(t_p, t_c) * dmodel_db(t_u, w, b)
return torch.stack([dloss_dw.mean(), dloss_db.mean()])
# 定义迭代过程
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
w, b = params
t_p = model(t_u, w, b)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' % (epoch, float(loss)))
print('Params', params)
print('Grad', grad)
return params
# 学习速率 learning_rate 太大,导致梯度算法振荡
# training_loop(
# n_epochs = 100,
# learning_rate = 1e-2,
# params = torch.tensor([1.0, 0.0]),
# t_u = t_u,
# t_c = t_c)
# 修改 learning_rate,是梯度算法收敛
# training_loop(
# n_epochs = 100,
# learning_rate = 1e-4,
# params = torch.tensor([1.0, 0.0]),
# t_u = t_u,
# t_c = t_c)
# 特征缩放处理
# t_un = 0.1 * t_u
# training_loop(
# n_epochs = 100,
# learning_rate = 1e-2,
# params = torch.tensor([1.0, 0.0]),
# t_u = t_un,
# t_c = t_c)
# 增加迭代次数
t_un = 0.1 * t_u
params = training_loop(
n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0, 0.0]),
t_u = t_un,
t_c = t_c)
# 画出图示
import matplotlib.pyplot as plt
t_p = model(t_un, *params)
fig = plt.figure()
plt.title(u"PyTorch linear model")
plt.xlabel("Fahrenheit")
plt.ylabel("Celsius")
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(), 'o')
plt.show()