python数据分析与挖掘实战——第五章-数据挖据建模——5.13-Logistic逻辑回归模型实例
一. 逻辑回归
在前面讲述的回归模型中,处理的因变量都是数值型区间变量,建立的模型描述是因变量的期望与自变量之间的线性关系。比如常见的线性回归模型:

而在采用回归模型分析实际问题中,所研究的变量往往不全是区间变量而是顺序变量或属性变量,比如二项分布问题。通过分析年龄、性别、体质指数、平均血压、疾病指数等指标,判断一个人是否换糖尿病,Y=0表示未患病,Y=1表示患病,这里的响应变量是一个两点(0-1)分布变量,它就不能用h函数连续的值来预测因变量Y(只能取0或1)。
总之,线性回归模型通常是处理因变量是连续变量的问题,如果因变量是定性变量,线性回归模型就不再适用了,需采用逻辑回归模型解决。
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
二分类问题的概率与自变量之间的关系图形往往是一个S型曲线,如图所示,采用的Logistic 函数(也叫Sigmoid函数)实现。
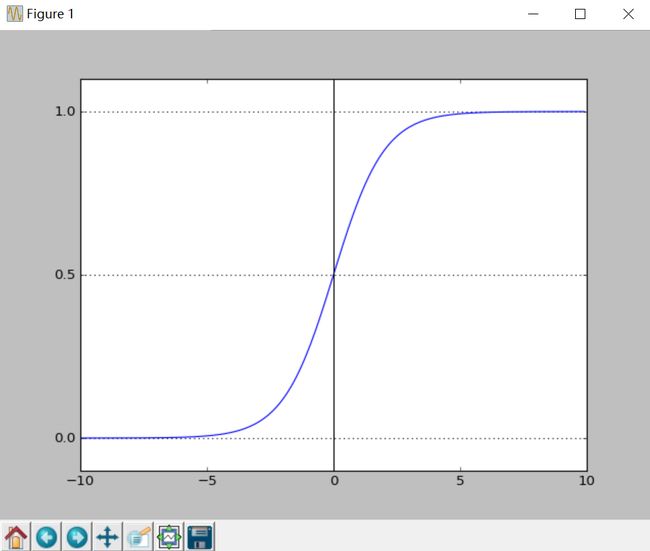
这里我们将该函数定义如下:

函数的定义域为全体实数,值域在[0,1]之间,x轴在0点对应的结果为0.5。当x取值足够大的时候,可以看成0或1两类问题,大于0.5可以认为是1类问题,反之是0类问题,而刚好是0.5,则可以划分至0类或1类。对于0-1型变量,y=1的概率分布公式定义如下:

y=0的概率分布公式定义如下:

其离散型随机变量期望值公式如下:

采用线性模型进行分析,其公式变换如下:

而实际应用中,概率p与因变量往往是非线性的,为了解决该类问题,我们引入了logit变换,使得logit(p)与自变量之
间存在线性相关的关系,逻辑回归模型定义如下:

通过推导,概率p变换如下,这与Logistic函数相符,也体现了概率p与因变量之间的非线性关系。
以0.5为界限,预测p大于0.5时,我们判断此时y更可能为1,否则y为0。

得到所需的Logistic函数后,接下来只需要和前面的线性回归一样,拟合出该式中n个参数θ即可
二. LogisticRegression回归算法
LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
(1) 导入模型。调用逻辑回归LogisticRegression()函数。
(2) fit()训练。调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
(3) predict()预测。利用训练得到的模型对数据集进行预测,返回预测结果。
代码如下:
from sklearn.linear_model import LogisticRegression #导入逻辑回归模型
clf = LogisticRegression()
print clf
clf.fit(train_feature,label)
predict['label'] = clf.predict(predict_feature)
输出结果如下:
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
其中,参数penalty表示惩罚项(L1、L2值可选。L1向量中各元素绝对值的和,作用是产生少量的特征,而其他特征都是0,常用于特征选择;L2向量中各个元素平方之和再开根号,作用是选择较多的特征,使他们都趋近于0。); C值的目标函数约束条件:s.t.||w||1 举个栗子(共700条数据,空间有限,只展示部分): 部分转自:https://blog.csdn.net/liulina603/article/details/78676723 感谢大神,写得很详细,还有LogisticRegression参数部分,待以后续继续学习
三、实例

import pandas as pd
from sklearn.linear_model import LogisticRegression as LR
# 参数初始化
filename = 'bankloan.xls'
data = pd.read_excel(filename)
x = data.iloc[:,:8].values # 选取,所有行,[0,8)列,的数据
y = data.iloc[:,8].values # 选取,所有行,[0,8)列,的数据
# x = data.iloc[:,:8].as_matrix()
# y = data.iloc[:,8].as_matrix()
# 会出现警告:FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
# 警告解决方法:https://blog.csdn.net/weixin_41884148/article/details/88783328
lr = LR(solver='liblinear') # 建立逻辑回归模型
# lr = LR() # 建立逻辑回归模型
# 会出现警告:FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning。
# 警告解决方法:https://blog.csdn.net/linzhjbtx/article/details/85331200
lr.fit(x, y) # 用筛选后的特征数据来训练模型
print('模型的平均准确度为:%s' % lr.score(x, y))
# 模型的平均准确度为:0.8057142857142857
# LogisticRegression的API:https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression.decision_function%20%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92