NLP ----- Bert with Sentiment Analysis
Bert模型可谓是在2018年NLP领域的大杀器,它的刷新了各种数据集上的NLP任务新高度,好像预示着人类在让机器理解自然语言的道路上又近了一步。google research方面也公布出了模型和代码,让该模型走近千家万户。作为模型的搬运工,自然不能错过把这样的神器收入囊中的机会。官方也给出了pretraining和fine-tuning的代码,但仅仅是调试官方的代码还是不能将模型很好利用起来,自然想到最好可以将模型应用到自己数据集下的NLP任务中。
- 关于BERT模型(论文地址https://arxiv.org/abs/1810.04805),论文比我讲的清楚,我就不多说,以免因为个人的理解的偏差对读者产生误导。
官方给出训练好的bert模型是ckpt格式的,既然有了模型文件,将模型加载到内存中,feed它数据就好了。(这里默认对tensorflow足够了解)讲道理,就是这么简单。可惜官方提供的训练好的模型graph当中placeholer这个部分的tensor的batch_size大小为1,如果直接将模型加载进来,feed给模型的batch_size也只能是1,这样训练起来就太慢了。所以,不得不还是要用官方提供的modeling.py文件引入模型定义的部分,之后再将ckpt文件中的模型权重restore即可。
以下是在imdb数据集上的进行模型的fine-tuning
- 查看工作环境和模型文件
此处import modeing即为官网提供的modeing.py,将文件放置在自己的工具目录下即可。我的工作目录如下:
ckpt模型文件如下:

个人习惯在jupyterlab工作环境下,方便对数据进行检查和文件查看。这里并不限定仅能使用jupterlab来完成模型的开发。
- 导入相关package
import json
import numpy as np
import tensorflow as tf
import modeling
tf.__version__- 导入imdb数据集
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(path="imdb.npz", num_words=30000) # 限定为30000词表大小为30000
# check 词序范围
min(min(train_data)), max(max(train_data))- 数据预处理
from keras.preprocessing.sequence import pad_sequences
train_data_ = pad_sequences(train_data, maxlen=127)
test_data_ = pad_sequences(test_data, maxlen=127)
# train
train_input_ids = np.hstack((np.zeros(len(train_data_)).reshape(-1, 1).astype(np.int), train_data_, ))
train_input_mask = pad_sequences([[1 for mask_id in range(len(x))] for x in train_data_], maxlen=128)
train_segment_ids = pad_sequences([[1 for mask_id in range(len(x))] for x in train_data_], maxlen=128)
# test
test_input_ids = np.hstack((np.zeros(len(test_data_)).reshape(-1, 1).astype(np.int), test_data_, ))
test_input_mask = pad_sequences([[1 for mask_id in range(len(x))] for x in test_data_], maxlen=128)
test_segment_ids = pad_sequences([[1 for mask_id in range(len(x))] for x in test_data_], maxlen=128)- 构建数据图(这里使用tf.data的接口将数据部分也转换为tensor,当sess.run的时候数据才会被feed给模型)
# 定义总图
g = tf.Graph()
# 数据图
with g.as_default():
batch_size = 32
# train
training_dataset = tf.data.Dataset.from_tensor_slices({
"input_ids": tf.constant(train_input_ids, shape=[len(train_data_), 128], dtype=tf.int32),
"input_mask": tf.constant(train_input_mask, shape=[len(train_data_), 128], dtype=tf.int32),
"segment_ids":tf.constant(train_segment_ids, shape=[len(train_data_), 128], dtype=tf.int32),
"label_ids": tf.constant(train_labels, shape=[len(train_data_), 1], dtype=tf.float32),
})
training_dataset = training_dataset.repeat(3)
training_dataset = training_dataset.shuffle(buffer_size=10)
training_dataset = training_dataset.batch(batch_size=batch_size)
# test
test_dataset = tf.data.Dataset.from_tensor_slices({
"input_ids": tf.constant(test_input_ids, shape=[len(test_data_), 128], dtype=tf.int32),
"input_mask": tf.constant(test_input_mask, shape=[len(test_data_), 128], dtype=tf.int32),
"segment_ids":tf.constant(test_segment_ids, shape=[len(test_data_), 128], dtype=tf.int32),
"label_ids": tf.constant(test_labels, shape=[len(test_data_), 1], dtype=tf.float32),
})
test_dataset = test_dataset.repeat(3)
test_dataset = test_dataset.shuffle(buffer_size=10)
test_dataset = test_dataset.batch(batch_size=batch_size)
# 定义train_op, test_op
with g.as_default():
iterator = tf.data.Iterator.from_structure(training_dataset.output_types, training_dataset.output_shapes)
next_element = iterator.get_next()
training_init_op = iterator.make_initializer(training_dataset)
test_init_op = iterator.make_initializer(test_dataset)- 定义模型图
# 定义模型类,这是否加载bert模型作为一个可控参数
class ModelGraph(object):
def __init__(self, data_iter, learning_rate, use_bert=False):
inputs = None
self.input_ids=data_iter["input_ids"]
self.input_mask=data_iter["input_mask"]
self.segment_ids=data_iter["segment_ids"]
self.label_ids=data_iter["label_ids"]
if use_bert:
with open("./uncased_L-12_H-768_A-12/bert_config.json", "r") as f:
config = json.load(f)
bert_config = modeling.BertConfig(config["vocab_size"])
bert_config.type_vocab_size = config["type_vocab_size"]
model = modeling.BertModel(
config=bert_config,
is_training=True,
input_ids=self.input_ids,
input_mask=self.input_mask,
token_type_ids=self.segment_ids,
use_one_hot_embeddings=False
)
pooler = model.get_pooled_output()
inputs = pooler
else:
with tf.name_scope("embedding"):
embeddings = tf.get_variable(
"embeddings",
initializer=tf.truncated_normal_initializer(stddev=0.1),
shape=(bert_config.vocab_size, 32),
dtype=tf.float32
)
look_up = tf.nn.embedding_lookup(embeddings, self.input_ids)
avg_embed = tf.reduce_mean(look_up, axis=1)
print(avg_embed)
inputs = avg_embed
with tf.name_scope("output_layer"):
self.logits = tf.layers.dense(inputs=inputs, units=1, name="my_layer")
print(self.logits)
with tf.name_scope("loss"):
self.loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.logits, labels=self.label_ids
))
tf.summary.scalar("loss", self.loss)
with tf.name_scope("train_op"):
self.train_op = tf.train.AdamOptimizer(learning_rate).minimize(self.loss)
with tf.name_scope("y_pred"):
self.y_pred = tf.cast(tf.greater(tf.nn.sigmoid(self.logits), 0.5), dtype=tf.float32)
print(self.y_pred)
with tf.name_scope("accuracy"):
self.accuracy = tf.reduce_mean(tf.cast(tf.equal(self.y_pred, self.label_ids), tf.float32))
tf.summary.scalar("accuracy", self.accuracy)
print(self.accuracy)
# 创建模型对象
with g.as_default():
model = ModelGraph(data_iter=next_element, learning_rate=1e-5, use_bert=True)模型图部分在tensorboard GRAPHS中显示如下:bert模型过大,这里不展开显示
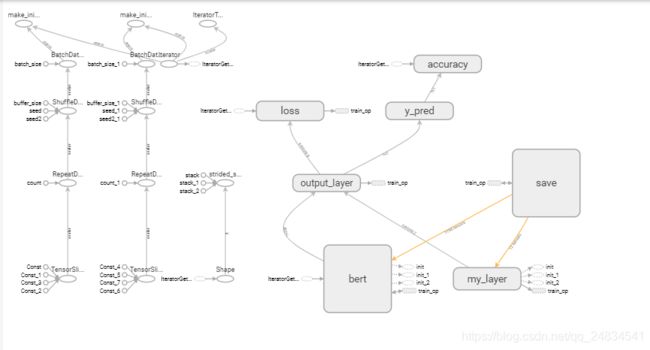
- 模型训练
%%time
from datetime import datetime
TIMESTAMP = "{0:%Y-%m-%dT%H-%M-%S/}".format(datetime.now())
train_log_dir = 'logs/train/' + TIMESTAMP
test_log_dir = 'logs/test/' + TIMESTAMP
with tf.Session(graph=g) as sess:
saver = tf.train.Saver()
merge_all = tf.summary.merge_all()
sess.run([tf.global_variables_initializer(), training_init_op])
train_writer = tf.summary.FileWriter(train_log_dir, sess.graph)
test_writer = tf.summary.FileWriter(test_log_dir, sess.graph)
for step in range(1000):
_, train_summary = sess.run([model.train_op, merge_all])
train_writer.add_summary(train_summary, global_step=step)
if step % 100 == 0:
sess.run(test_init_op)
test_summary = sess.run(merge_all)
test_writer.add_summary(test_summary, global_step=step)
sess.run(training_init_op)
saver.save(sess, "model/sentiment_analysis.ckpt") # 在工作目录下创建model文件用于保存模型
train_writer.close()
test_writer.close()- 训练监控
![]()
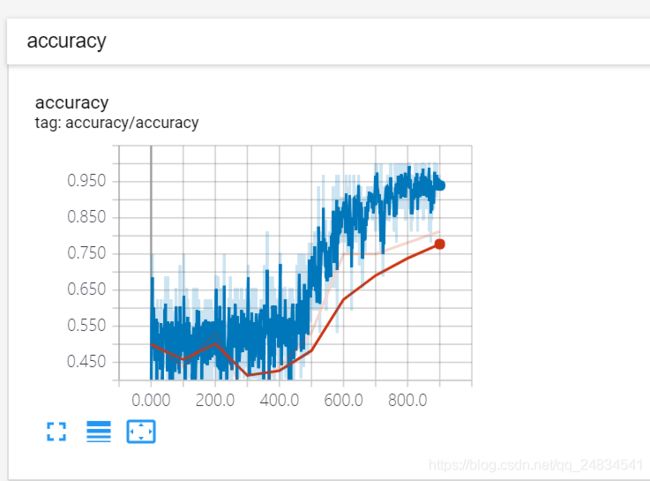
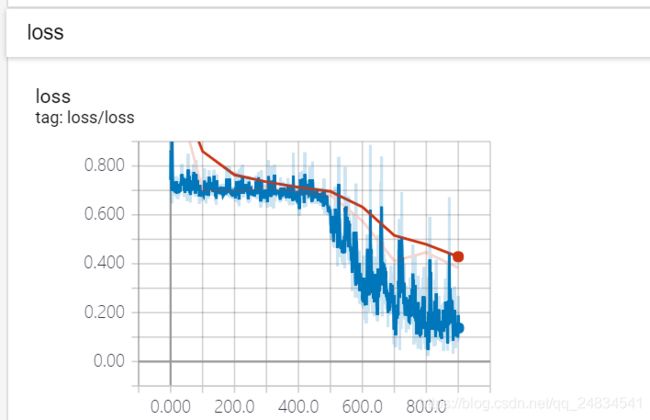
- 测试结果
test_graph = tf.Graph()
with tf.Session(graph=g) as sess:
saver = tf.train.import_meta_graph("model/sentiment_analysis.ckpt.meta")
saver.restore(sess, tf.train.latest_checkpoint("model/"))
sess.run(test_init_op)
test_loss, test_acc = sess.run(["loss/Mean:0", "accuracy/Mean:0"])
print("loss is {}, acc is {}".format(test_loss, test_acc))![]()
 模型训练执行了 1000个step,每个step获取一次batch_size下样本,更新一次模型权重,从监控图来看,模型在0-400次,loss处于不下降状态,也就是落入了平坦区域, 但是经过了400次之后,loss开始稳步下降了。对比use_bert=False的训练模式(这里没有贴出训练过程,可自行尝试),使用bert模型进行微调,训练消耗了不少时间,13个小时,而在非bert模式下,训练同样的step仅仅几分钟,而就结果来看,微调bert并没有带来精度上的提升,也许是我训练轮数不够,也许是学习速率设置的不合适,但是在没有GPU的情况下,消耗的时间成本太高,训练好的模型本身也会比较大。
模型训练执行了 1000个step,每个step获取一次batch_size下样本,更新一次模型权重,从监控图来看,模型在0-400次,loss处于不下降状态,也就是落入了平坦区域, 但是经过了400次之后,loss开始稳步下降了。对比use_bert=False的训练模式(这里没有贴出训练过程,可自行尝试),使用bert模型进行微调,训练消耗了不少时间,13个小时,而在非bert模式下,训练同样的step仅仅几分钟,而就结果来看,微调bert并没有带来精度上的提升,也许是我训练轮数不够,也许是学习速率设置的不合适,但是在没有GPU的情况下,消耗的时间成本太高,训练好的模型本身也会比较大。
由此得到一个结论,新技术,新模型,也许在学术界披荆斩刑,但是在工程使用上性价比不见得高。当然也许我本次实验有姿势不对的地方,自己未能察觉,欢迎行家拍砖指正!