Spark(Python)学习(四)
HBase
HBase是基于Google BigTable的开源产品,是Hadoop家族的成员组件,架构在Hadoop之上,是一个分布式数据库。分布式数据库的数据保存在底层的HDFS中。
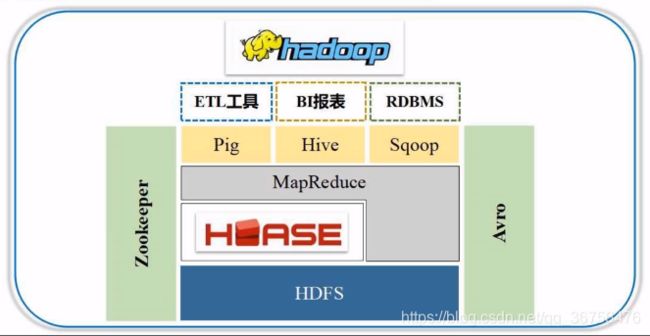
HBase是一个稀疏多维度排序映射表。
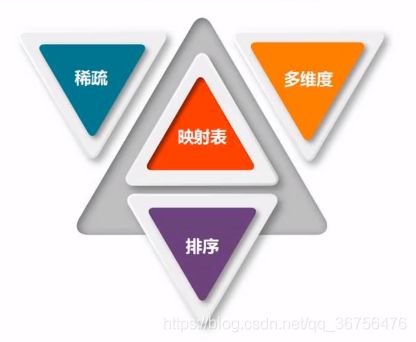
HBase是google的BigTable的开源实现,BigTable指一个表中包含非常多的列,非常多的行(百万级)。跟关系数据库的多表连接查询不同,HBase把相关的信息全部汇总在一个表中,不需要多表的连接操作,具有高的数据读写性能。

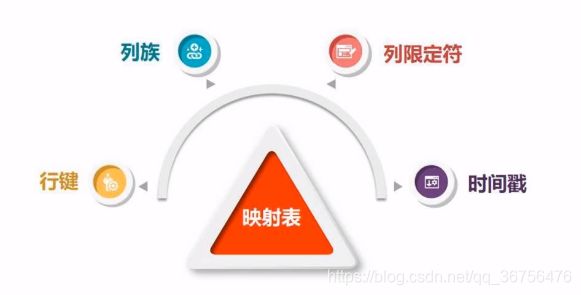
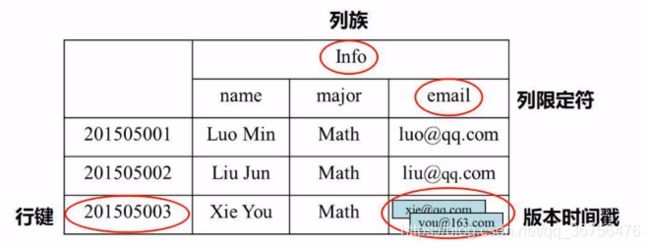
一个表分为若干行和若干列族。
每个行由行键(row key)唯一的标识一行。
一个表从垂直方向上分成很多个列族,一个列族中包含多个列(列限定符)。
HBase中的数据都是按单元格形式保存的,读取也按单元格读取,不同于关系数据库的按行存取。
由于每个单元格的内容可能发生变化,而底层所基于的分布式存储HDFS是只读的,所以采用变相修改方式,将指针指向新生成的数据,间接实现修改,旧数据依然存在导致数据的多个版本,因此使用时间戳进行索引。
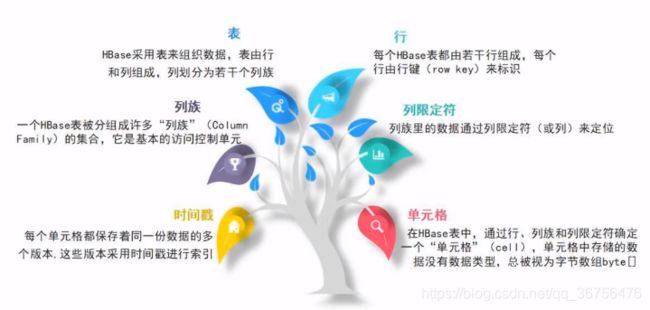
HBase中的值采用4维定位法,即行健、列族、列限定符、版本时间戳。(关系数据库是二维定位,只需要行和列,便可以唯一确定一个值)。
HBase为什么可以存储这么大数量级的数据
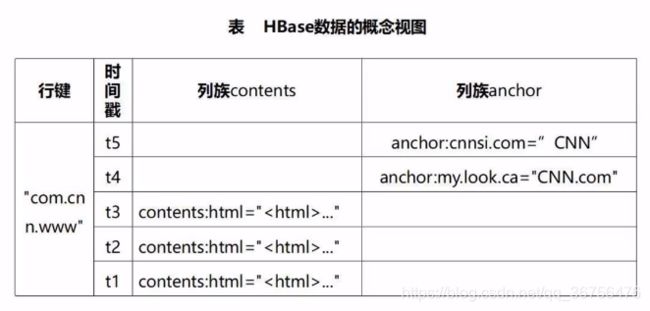
下表内容为爬取网页保存的信息,列族contents中保存的是网页的全部html文本,列族anchor中保存具体的锚文本。所以一个网页被解析出来后,会把各种各样的信息全部保存在这样一个大表中,下表只是行键中的一个。
上面的表只是概念视图,真正存储时是把行键、列族加时间戳的方式存储的,所以存储时把行键、时间戳和列族单独提取出来,构成了底层的物理视图。
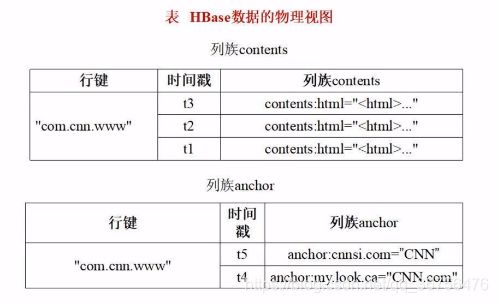
HBase可以存储大数量级的数据,与HBase的存储结构有关,上表中只有一个行键,即一个网页被抓取的数据。实际上可能还有其他的许多行和列,这样具有庞大数据的表无法保存在一个电脑上,所以保存机制采用水平分区(分为一个个行键)和竖直分区(分为一个个列族),将数据切分为许多小碎片,每一个碎片称之为一个分区,每一个分区被单独的分散到多台电脑保存。使用是在利用相应的机制将碎片找回处理。
创建HBase表
启动Hadoop
$ cd <Hadoop安装目录>
$ ./sbin/start-all.sh
启动HBase
$ cd <HBase安装目录>
$ ./bin/start-hbase.sh
$ ./bin/hbase shell
确保数据库里不存在‘student’表,如果存在则删除
hbase> disable 'student'
hbase> drop 'student'
创建表如下表格

创建列族信息
hbase> create 'student', 'info'
关系数据库以行为单位录入数据,而HBase数据库以单元格为单位录入数据。

录入student表第一个学生记录
hbase> put 'student','1','info:name','Xueqian'
hbase> put 'student','1','info:gender','F'
hbase> put 'student','1','info:age','23'
同理录入第二个学生记录
hbase> put 'student','2','info:name','Weiliang'
hbase> put 'student','2','info:gender','M'
hbase> put 'student','2','info:age','24'
配置Spark
为防止编程运行中出现错误,需要配置Spark,载入JAR包。
配置视频
编写程序读取HBase数据
使用SparkContext提供的newAPIHadoopRDD,API将表的内容以RDD的形式加载到Spark中。
保存为SparkOperateHBase.py
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf=conf) // 生成一个SparkContext对象sc担任指挥官
host = 'localhost' // 本地安装
table = 'student' // 指定读取表的名称
conf = {"hbase.zookeeper.quorum":host,"hbase.mapreduce.inputtable":table} // 配置zookeeper服务器在localhost,和当前读取的表格
keyConv = "org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter" // 指定键的转换类,将ImmutableBytesWritable格式数据转换为String型数据
valueConv = "org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter" // 指定值的转换类
hbase_rdd = sc.newAPIHadoopRDD("org.apache.hadoop.hbase.mapreduce..TableInputFormat","org.apacche.hadop.hbase.io.ImmutableBytesWritable","org.apache.hadoop.hbase.client.Result",keyConverter=keyConv,valueConverter=valueConv,conf=conf) // 指定读取表的格式为mapreduce.TableInputFormat,指定从HBase读出的key的类型是ImmutableBytesWritable,value为Result类,keyConverter=keyConv,valueConverter=valueConv指定key和value的转换类
count = hbase_rdd.count() // 计算有多少行键
hbase_rdd.cache() // 缓冲区缓存
output = hbase_rdd.collect() // 把键值对封装在一个列表中返回
for (k,v) in output: // 对列表中每个键值对一次进行循环遍历输出
print(k,v)
// 完成整个程序读写HBase数据
执行代码
$ cd
$ /bin/spark-submit SparkOperateHBase.py
编写程序向HBase写入数据
把表中的两个学生信息插入到HBase的student表中


keyConv —— key值转换器,转换String类型数据为ImmutableBytesWritable类型。
valueConv —— value值转换器,转换StringList类型数据为Put类型(StringList说明录入值会形成一个字符串列表)。
rawData中每个数据是一个单元格,由六个字符串组成,每个字符串包含“行键、列族、列和每个单元个对应的值”。
.parallelize —— 先将列表加载至内存生成一个RDD,通过RDD再写入到底层HBase。
.map(lambda x:x[0],x.split(’,’)) —— x[0]是行键,在这里是3或4,split(’,’)以“,”进行分隔,形成字符串列表StringList。
执行代码
$ cd
$ /bin/spark-submit SparkWriteHBase.py
查看写入结果,进入HBase shell中,执行如下命令
hbase> scan 'student'
案例(求TOP值)
求payment的N个top值

程序代码

逐行解释

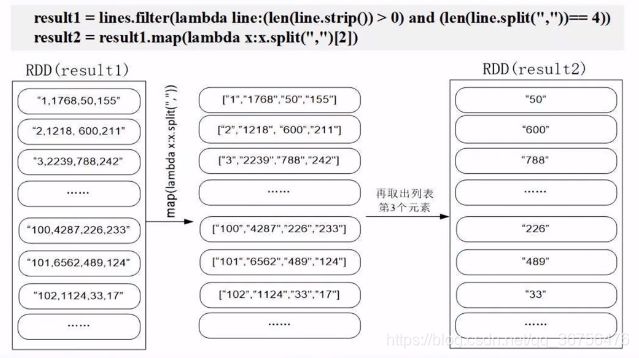
line.strip() —— 把字符串后的空格删除
len(line.split(","))==4 —— 以逗号分拆字符串生成列表,筛选出列表长度为4的数据。
.map(lambda x:x.split(",")[2]) —— 生成列表,取出第三个元素payment。

.map(lambda x:(int(x),"")) —— 将值转换为键值对以便排序。
.repartition(1) —— 放在一个分区保证全局有序。
.sortByKey(False) —— 根据key降序排序。
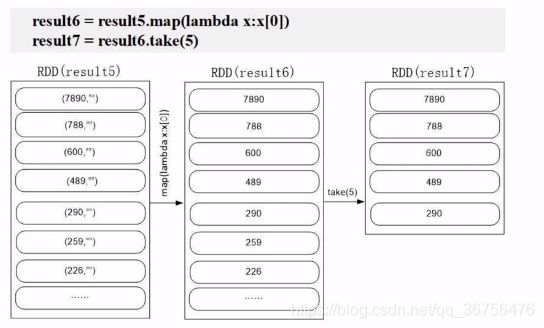
.map(lambda x:x[0]) —— 取出key值。
.take(5) —— 取出前五个数据。
案例(文件排序)
读取文件中所有整数进行排序,排序后输出到一个新的文件中。
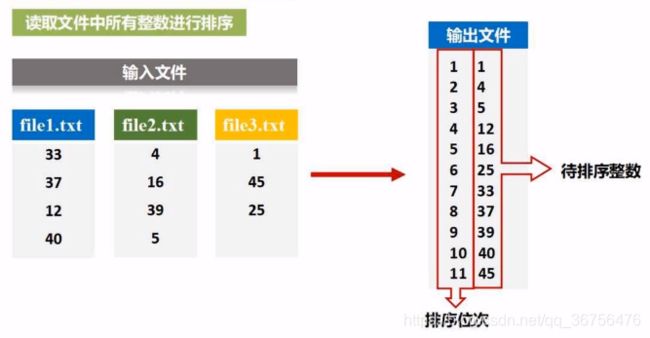
程序代码

逐行解释
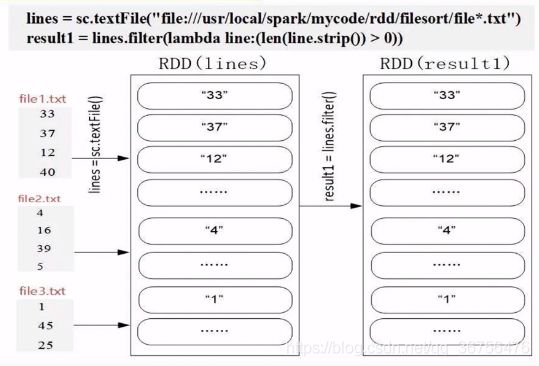
lambda line:(len(line.strip())>0) —— 消除空行,即当去掉空格后该行的长度为0则删除。

.map(lambda x:(int(x.strip()),"")) —— 生成键值对。
.sortByKey(True) —— 升序排序。
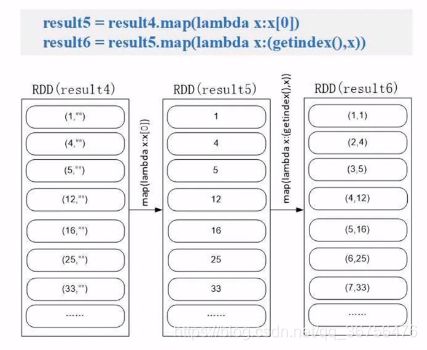
.map(lambda x:x[0]) —— 取键值对中的key,丢弃空字符串。
.map(lambda x:(getindex(),x)) —— getindex()用于获取全局顺序,每次调用getindex会返回递增值。
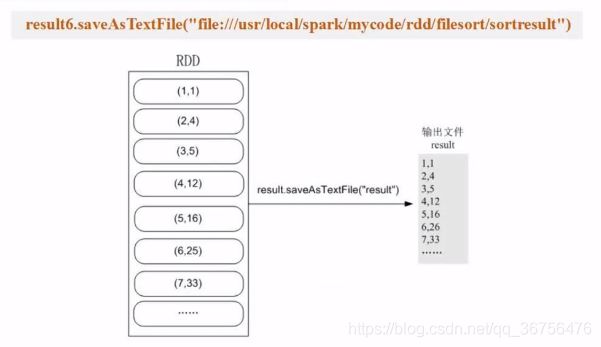
把生成的数据写入文本文件。
案例(二次排序)
要求文件中出现的每一行,对其列值进行排序,即第一列值按降序排序,若第一列中两值相等,则根据其对应第二列的值降序排序。

.sortByKey()要求用于排序的key必须是可比较对象,在这里“5 3”、“1 6”、…、“3 2”并不是整型值,在文本文件中以字符串形式存在。所以调用“.sortByKey()”时会将“5 3”看成一个字符串进行比较。

如何把字符串转化为可比较的key,下面是解题思路
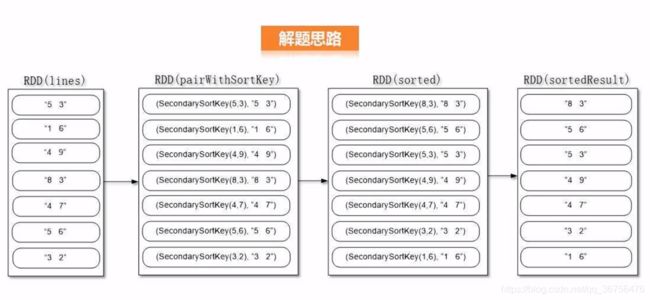
人工生成一个用于排序的SecondarySortKey类,使其成为键值对中的key,使字符串成为键值对中的value。
对键值对中可排序的key“SecondarySortKey()”进行二次排序,得到了排序后的结果(由于键值对排序,value随key移动,所以value也完成排序),再将临时用于排序key删除,得到所需结果。

以下为代码实现


逐行解释
加载数据到内存,生成RDD,删除空行。

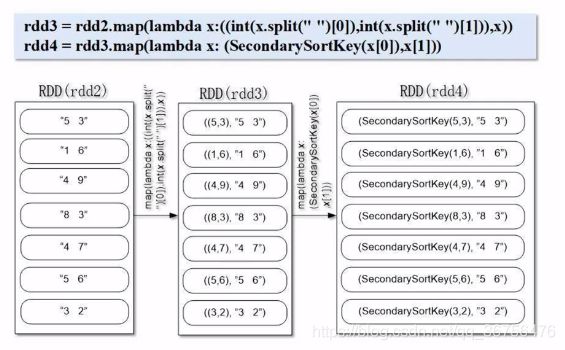
.map(lambda x:((int(x,split(" “)[0]),int(x.split(” ")[1])),x)) —— 生成键值对,以空格分隔,分别将两个字符串整型转换生成一个键值对(为方便理解,这个键值对记作A),并将A对作为外层键值对B的key。(在第一条数据里A=(5,3),B=(A,“5 3”))
SecondarySortKey(x[0]) —— 其中x[0]为前面生成的键值对B的key(即A),调用SecondarySortKey()类,将键值对A传入“ _init_(self,k)”中的k,将键值对A的key和value分别传入self.column1和self.column2中,生成了SecondarySortKey()类的对象。
“_gt_(self,other)”重写了比较函数,重写为若第一个点相等,则比较第二个点。

进行降序排序得到完成二次排序的rdd5,删除为排序生成的临时key。程序完成。