大数据Spark技术数据分析综合实验:出租车数据分析
Spark出租车数据实验
目录
- Spark出租车数据实验
- 【实验目的】
- 【实验原理】
- 【实验环境】
- 【实验步骤】
- 1.数据加载
- 2.数据分析
- 3、模型构建
- 4.可视化展现
【实验目的】
主要使用出租车上传的GPS点作为分析对象,使用Kmeans把出租车轨迹点聚类,找出出租车出现密集的地方,并用地图的方式进行可视化展示
【实验原理】
(1)数据的准备。
(2)创建DataFrame。
(3)使用kmeans聚类。
(4)聚类结果可视化。
【实验环境】
操作系统:Linux
开发环境:pyspark命令行
【实验步骤】
1.数据加载
数据路径:
http://10.90.3.2/HUP/spark/taxi.csv
终端下载数据
cd /home/ubuntu
wget http://10.90.3.2/HUP/spark/taxi.csv
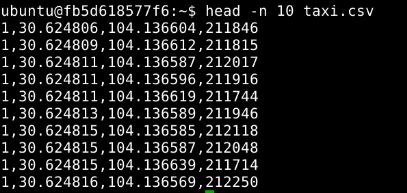
该实验采用数据为出租车载客时GPS记录数据集,数据格式为CSV,CSV格式是数据分析中常见的一种数据格式。
数据共4列,列之间以“,”分割。
tid:出租车编号 lat:维度 lon:经度 time:时间戳
安装软件依赖
pip install numpy
2.数据分析
(1)创建DataFrame
首先终端执行如下命令进入交互式命令行:
pyspark
使用textFile函数读取csv文件创建taxi_data,然后使用map算子操作将按照逗号隔开的文本创建RDD。
taxi_data = sc.textFile("/home/ubuntu/taxi.csv")
taxi_rdd=taxi_data.map(lambda line:line.split(','))
创建矢量RDD,矢量两个参数分别为纬度和经度。在下文的聚类函数中需要该格式RDD进行聚类。
from pyspark.ml.linalg import Vectors
taxi_row=taxi_rdd.map(lambda x: (Vectors.dense (x[1],x[2]), ))
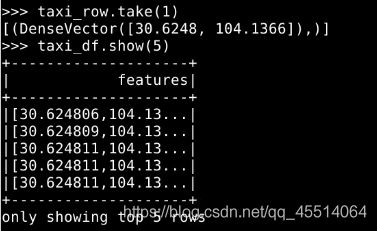
使用createDataFrame创建DataFrame,并查看数据。
taxi_df=spark.createDataFrame(taxi_row,["features"])
taxi_df.show(5)
3、模型构建
输入和输出列是用户使用kmeans方法时候的参数类型,默认的输入列名为features,输出的列名为prediction。KMeans方法中包含若干参数,其中k为分簇个数,seed为种子点。
from pyspark.ml.clustering import KMeans
kmeans=KMeans(k=3, seed=1)
model=kmeans.fit(taxi_df)
centers=model.clusterCenters()
print(centers)
4.可视化展现
申请地图key
使用百度地图接口需要百度的一个认证,也就是需要在登录百度地图开发平台申请key,申请key地址:http://lbsyun.baidu.com/apiconsole/key,申请界面如图
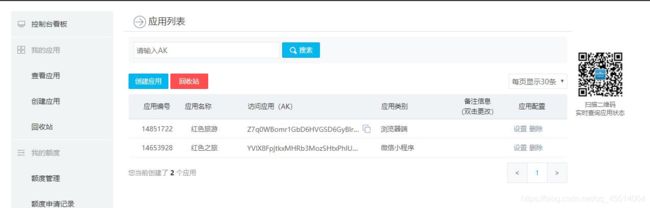
点击创建应用
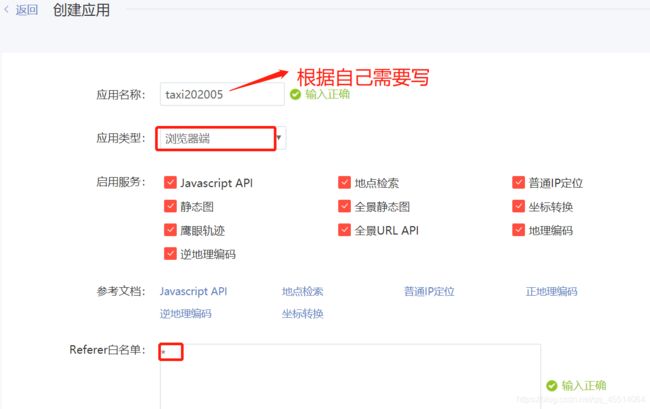
聚类结果可视化
已经得到了聚类结果坐标,本节任务就是把这些点可视化出来即可。根据百度开放平台提供的例子简单地编写一些html代码即可展示相应的点,代码核心部分如下:
<!DOCTYPE html>
<html>
<head>
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>kmeans聚类可视化</title>
<style type="text/css">
html{height:100%}
body{height:100%;margin:0px;padding:0px}
#container{height:100%}
</style>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=2.0&ak=Z7q0WBomr1GbD6HVGSD6GyBIrkqeoFhi">
//v2.0版本的引用方式:src="http://api.map.baidu.com/api?v=2.0&ak=您的密钥"
</script>
</head>
<body>
<div id="container"></div>
<script type="text/javascript">
var map = new BMap.Map("container");
// 创建地图实例
map.enableScrollWheelZoom(); //允许滑轮进行放大缩小
map.addControl(new BMap.NavigationControl());// 添加平移缩放控件
map.addControl(new BMap.ScaleControl());// 添加比例尺控件
var myP1 = new BMap.Point(104.088050401,30.6461552); //声明点对象
var myP2 = new BMap.Point(103.89418873,30.89418873);
var myP3 = new BMap.Point(104.01765079,30.65644259);
// 创建点坐标
map.centerAndZoom(myP1 , 15);
// 初始化地图,设置中心点坐标和地图级别
map.clearOverlays(); //清空地图中的对象
var marker1 = new BMap.Marker(myP1); //定义点样式,默认为红色水滴形状
var marker2 = new BMap.Marker(myP2);
var marker3 = new BMap.Marker(myP3);
map.addOverlay(marker1); //添加点到地图
map.addOverlay(marker2);
map.addOverlay(marker3);
</script>
</body>
</html>
在浏览器中打开,展示结果如下:
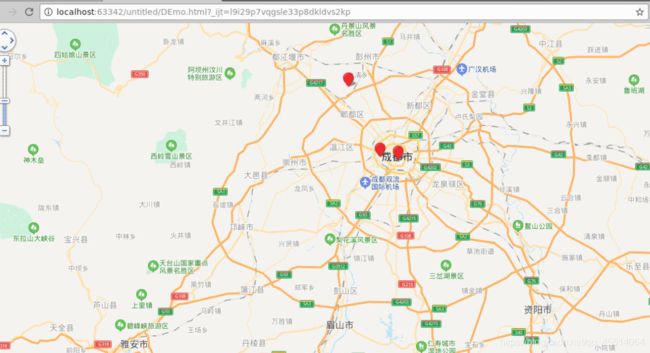
实验总结:本实验使用出租车数据,用Kmeans把出租车轨迹点聚类,找出出租车出现密集的地方,并用地图的方式进行可视化展示。主要在数据分析时创建出KMeans算法的输入数据类型,如何创建模型进行可视化。