模拟购物数据实时流处理(2)——模拟数据源
项目介绍
本项目总体分为
- 平台搭建
- 模拟数据源生成
- 实时流数据处理
- 实时数据大屏
这几个部分,我将分成几个博客分别介绍这些部分的工作,本文主要介绍模拟数据源生成的部分,下面给出整个项目数据生成和处理部分的框架
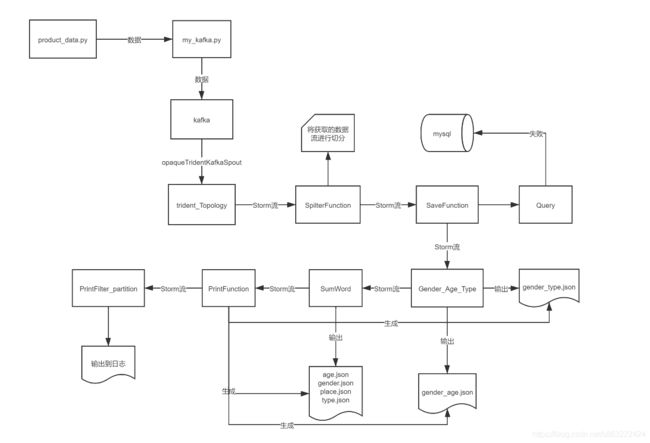
平台搭建,具体可以看平台搭建
实时流数据处理,具体可以看实时流数据处理
实时数据大屏,具体可以看实时数据大屏
项目下载地址下载
环境介绍
在数据生成部分,主要使用python语言来完成,为什么不用java,是因为我感觉java在这个方面使用起来完全不如python简单直观,下面给出一些配置
- python3.6.8
- 主要使用的库为random,time,kafka-python
- kafka集群在上文平台搭建有介绍
代码部分
整个代码部分只分成了两块,一块是随机生成数据的部分,一块是将生成的数据传到kafka里面
product_data.py
import random
from my_kafka import log_kafka
import time
age_one=['10-20','20-30','30-40']
age_two=['40-50','50-60','60-100']
type_two=['玩具','家电','珠宝','运动','影视','宠物','汽车','办公','百货','学习','建材','动漫','其他']
type_one=['服装','数码','洗护','食品','鞋靴','游戏',]
hometown_one=['北京','上海','广东','浙江','江苏','河南','山东','湖北','湖南',]
hometown_two=['天津','重庆','河北','山西','辽宁','吉林','黑龙江','安徽',
'福建','江西','海南','四川','贵州','云南','陕西','甘肃',
'青海','台湾','内蒙古','广西','西藏','宁夏','新疆']
while(True):
string=''
for i in range(0,5):
a=random.randint(1,10)
b=random.randint(1,10)
if a<=7:
if b<=7:
string=string+str(random.randint(100000000,999999999))+'\t'+'female'\
+'\t'+random.choice(age_one)+'\t'+random.choice(type_one)+'\t'+random.choice(hometown_one)\
+'\t'+str(random.randint(1,10))+'\t'+str(random.randint(1,10000))+'\n'
else:
string = string + str(random.randint(100000000, 999999999)) + '\t' + 'male' + '\t' + \
random.choice(age_one) + '\t' + random.choice(type_one) + '\t' + random.choice(hometown_one) \
+ '\t' + str(random.randint(1, 10)) + '\t' + str(random.randint(1, 10000)) + '\n'
else:
if b<=7:
string = string + str(random.randint(100000000, 999999999)) + '\t' + 'female' + '\t' + \
random.choice(age_two) + '\t' + random.choice(type_two) + '\t' + random.choice(hometown_two) \
+ '\t' + str(random.randint(1, 10)) + '\t' + str(random.randint(1, 10000)) + '\n'
else:
string = string + str(random.randint(100000000, 999999999)) + '\t' + 'male' + '\t' + \
random.choice(age_two) + '\t' + random.choice(type_two) + '\t' + random.choice(hometown_two) \
+ '\t' + str(random.randint(1, 10)) + '\t' + str(random.randint(1, 10000)) + '\n'
log_kafka(string)
print(string)
time.sleep(1)
这一块本来生成很简单,但是为了后面的可视化部分好看一些,必须使得随机生成的数据不那么随机,所以采取了上面的办法,按照消费水平将城市给分成了两类,同时这里博主主观上将一些大家更常买的东西给分了出来,以及主观上认为年轻人,尤其是年轻女性对于网购的需求可能更高一些,如果需要展示不同的效果,只需要改变上面的参数即可
my_kafka.py
# -*- coding: utf-8 -*-
from kafka import KafkaProducer
from kafka.errors import KafkaError
KAFAKA_HOST="192.168.161.100" # 服务器端口地址
KAFAKA_PORT = 9092 # 端口号
KAFAKA_TOPIC = "wordcount"# topic
class Kafka_producer():
def __init__(self, kafkahost, kafkaport, kafkatopic):
self.kafkaHost = kafkahost
self.kafkaPort = kafkaport
self.kafkatopic = kafkatopic
self.producer = KafkaProducer(bootstrap_servers='{kafka_host}:{kafka_port}'.format(
kafka_host=self.kafkaHost,
kafka_port=self.kafkaPort)
)
def sendjsondata(self, params):
try:
parmas_message = params # 注意dumps
producer = self.producer
producer.send(self.kafkatopic, value=parmas_message.encode('utf-8'))
producer.flush()
except KafkaError as e:
print(e)
def log_kafka(params):
# kafka生产模块
print("======> producer:", params, '\n')
producer = Kafka_producer(KAFAKA_HOST, KAFAKA_PORT, KAFAKA_TOPIC)
producer.sendjsondata(params)
这一块只要修改上面的IP端口以及topic就可以使用
结束语
数据生成这部分本身就不是整个项目里面的重点,主要还是起到一个基础性的作用,如果有更好的数据生成或者本身就有购物数据那么大可不必这样去随机的生成