数据分析师基本技能——SQL
我们做数据分析工作时,多数数据来源于数据库,SQL非常方便我们访问和查询数据库。
SQL 作为数据分析师的基本技能,那么需要掌握哪些SQL核心技能
- 理解数据库
- SQL基础重点知识:查询,更新,提取,插入,删除等数据操作
- 典型实例sql
1.理解数据库
数据库基本定义:
数据库(Database)基本含义为:存储数据的地方,确切地来说是一张张表格,每张表通过一定联系链接在一起,最后组成了数据库
可以简单的理解为:数据库中最基本的元素为表(table),每个表都有一个身份标识(像我们的身份证,来证明我们是谁)专业名称叫主键,每张表只有一个主键,它具有唯一性,table的中包含列和行,列为名称标签,行为记录具体数据。
在数据库中,如何关联其他表,一般会以 「表名_ID」作为联接,通过JOIN 进行操作链接
选取主流数据库
市场上主流的数据有MySQL、Oracle、SQL Server等,而MySQL 是一个开源的关系型的数据库管理系统,应用非常广泛,因而选择使用Mysql学习sql是个不错的选择。
mysql的安装与配置非常简单,我们从官网下载社区版本安装,windows用户可以选择安装MSI安装(Windows Installer),一直默认安装,到了数据库用户和密码设置时,设置即可。
选取MySQL的GUI工具
windows用户选择Navicat第三方工具,来连接mysql,连接好了我们就可以进行数据库操作了。
Navicat常用的快捷键
- Ctrl+Q ------ 打开查询窗口
- Ctrl+R ------ 运行查询窗口的sql语句
- Ctrl+Shift+R ------ 只运行选中的sql语句
- Ctrl+N ------ 打开一个新的查询窗口
- Ctrl+W ------ 关闭一个查询窗口
- Ctrl+/ ------ 注释sql语句
- Ctrl+L ------ 删除一行
- Ctrl+Shift +/ ------ 解除注释
- F6 ------ 打开一个mysql命令行窗口
- Ctrl+D ------ 表的数据显示显示页面切换到表的结构设计页面,但是在查询页面写sql时是复制当前行
Navicat基本操作实践
创建数据库,含有一个简单的数据表,并进行C(创建)U(更新)R(读取,查询)D(删除)操作数据表
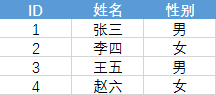
创建数据库
CREATE DATABASE 数据库名称
CREATE DATABASE MINGZHI打开数据库
USE 数据库名称
USE MINGZHI查看数据数据库
#查看所有数据库
SHOW DATABASES
#查看当前打开的数据库
SELECT DATABASE()删除数据库
DROP DATABASES 数据库名称
DROP DATABASES MINGZHI在数据库中创建数据表,根据具体数据类型,选择相应数据长度
CREATE TABLE tb1(
ID INT(20) NOT NULL,
姓名 varchar(20),
性别 varchar(5)
)
#查看数据表
SHOW TABLES FROM MINGZHI
#查看数据表结构
SHOW COLUMNS FROM MINGZHI向数据表中写入记录
INSERT 表名称 (列1, 列2,...) VALUES (值1, 值2,....)
INSERT tb1(ID, 姓名, 性别) VALUES(1,'张三', '男');
INSERT tb1(ID, 姓名, 性别) VALUES(2,'李四', '女');
INSERT tb1(ID, 姓名, 性别) VALUES(3,'王五', '男');
INSERT tb1(ID, 姓名, 性别) VALUES(4,'赵六', '女');删除记录的数据
DELETE FROM 表名 WHERE 列名称 = 某值
DELETE FROM tb1 WHERE 姓名 = '赵六' 更新记录的数据
UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
UPDATE persons SET 性别 = '男' WHERE 姓名 ='赵六'ALTER TABLE 语句用于在已有的表中添加、修改或删除列
2.SQL基础重点知识
通过2周的学习,先谈谈我的学习感受,sql语句学习相对比较简单,上手蛮快的,最核心思路就是,掌握基础知识,理清逻辑思路。
比如理清sql语句的执行顺序:
select---from---where---groupby---having---orderby一、对基础重点知识梳理如下
一些关键字含义梳理
- select.....from
- where
- group by --having
- order by
- like
- distinct
- 常用函数:sum,count, max, min,avg
- case when then else end
select :选取数据,查看数据,指定返回的列 from: 需要从哪个数据表选取数据
select 列名称 from 表名称
select * from 表名称 #获取所有列where : 设置条件筛选数据
WHERE 列 运算符 值需要理解筛选的条件,合理利用运算符获取数据
group by:对指定的字段进行分组,产生汇总信息,一般结合sum,count函数使用。
select 字段1,字段2 from Table1
GROUP BY 字段1,字段2group by 使用中需要注意的问题
1,注意返回结果集的字段,,这些字段要么要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中
例如将上面代码改成如下,就是错误的,会报错:字段2没有包含在group by 中,因为group by 根据字段1,将具有相同分组字段的记录归并成了一条记录,然而那些不存在于Group By语句后面作为分组依据的字段就有可能出现多个值,但是当前一种分组情况只有一条记录,一个数据格是无法放入多个数值的,所以这里就需要通过一定的处理将这些多值的列转化成单值
select 字段1,字段2 from Table1
group by 字段12,where 搜索条件在进行group by 分组操作之前应用,不能使用聚合函数
3, having 搜索条件在进行分组操作之后应用,可以使用聚合函数
order by : 根据指定的列对结果集进行排序, 默认按照升序,降序用desc
ORDER BY 字段1,字段2like:模糊搜索,用于在 WHERE 子句中搜索列中的指定模式,结合“%”通配符使用
where column_namelike pattern还可以用正则表达式来进行搜寻,REGEXP pattern(后续研究正则再详细减少)
distinct: 去重字段,需注意,只能放在select 语句首字段中
SELECT DISTINCT 列名称 FROM 表名称sum:返回数值列的总数、 avg: 返回列的平均值、 count()返回表中的记录数
max():返回最大值、 min():返回最小值
二、联接查询
- 内联接
- 外联接
内联接
多表内联接:将多张表连接在一起,只列出匹配的记录
FROM 表1 [INNER] JOIN 表2 ON〈联接条件〉自连接(特殊的内联接): 将一张表,在逻辑上分为两张表,每张表取不同的别名来区别
FROM 表1 表名1 [INNER] JOIN 表1 表名2 ON〈联接条件〉外联接
包括,左、右连接,返回所有的行
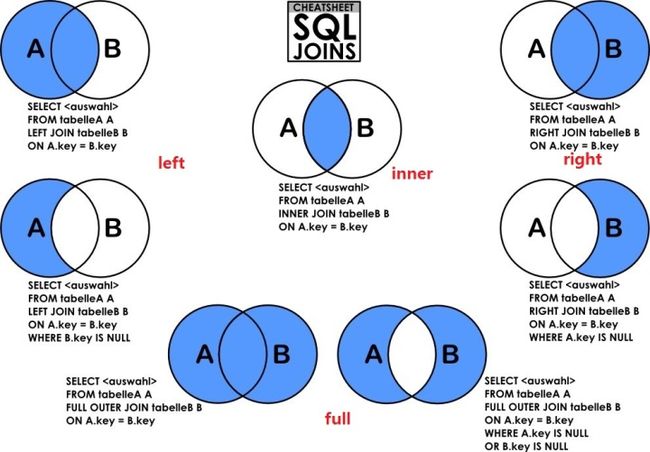
FROM 表1 LEFT JOIN 表2 ON〈连接条件〉如何理解JOIN,看这张图就够了,这张表非常清晰的阐述了JOIN的用法,
- 内联接 inner Join,找出两张表共有的字段;
- 左联接 left join,以 join 前面一张表为主,返回其所有行,如果与右表有相同的字段,全部返回,否则为空,右联接刚好与之相反。
- 全连接 Full join, 两张表全部返回

三、子查询
说白了就是嵌套查询,包含在某个查询中,如果子查询依赖于外部条件,则被称为相关子查询;
反之为非相关子查询
将外部查询的数据,放到内层子查询中做条件验证,根据验证结果(TRUE 或 FALSE)来决定外部查询的数据结果是否得以保留
举例:三张表,一张表student包含姓名sname,学号sno;一张表为course包含,课程编号cno,具体课程cname;一张表为score包含,学号sno,课程编号cno,和成绩score,
查询所有参加选修课程的同学的名字
select sname
from student st
where not exists
(
select sno
from course co
where not exists
(
select sno
from score sc
where sc.cno = co.cno and sc.sno = st.sno
)代码实现逻辑:
先取一条student记录,进入中层,再取一条course的记录,进入内层,此时student的记录和course的记录,作为内层判断的条件,在内层进行判断,结果返回真,则内层的NOT EXISTS为假, 然后继续对course表中的下一条记录进行判断,返现NOT EXISTS的值也为假,直到遍历完course表中的所有的数据,内层的NOT EXISTS的值一直都是假,所以中间层的WHERE语句的值也一直都是假。因为中间层一直为假,返回NOT EXISTS的值为真,结果就出现在结果集中,然后继续对student表中的下一条记录进行判断,直达student表中的所有数据都遍历完毕
参考与该篇文章
SQL 子查询 EXISTS 和 NOT EXISTS3.典型实例sql
1、查询每个部门最高工资员工(题源来自LeetCode)


实现逻辑:首先在Employee表查询,找到部门最高工资,然后联接Department表,与其部门对应起来
代码如下:
select d.name as Department, e.name as Employee, e.Salary as Salary
from Employee e join Department d On e.DepartmentId = d.id
where (e.DepartemtId,e.Salary) in (select department,max(Salary)from Employee group by DepartementID)主要语法有 inner join,max(), in, group by
2、查询员工第n高的工资(题源来自LeetCode)
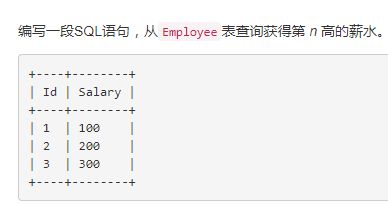
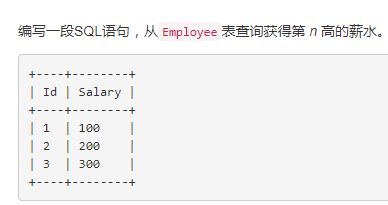
实现逻辑:受启发于找第2高的工资,假如我们要找第2高的工资,那么就存在一个最大值(第一高),排除最大的,在其余的值中寻找最大的。以此类推,找到第N高的工资也就不难了
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
select max(Salary) from Employee e
where N - 1 =
(select count(distinct(e.Salary)) FROM Employee e2
where e2.Salary > e1.Salary)
);
END主要语法有 max(),count(),distinct()
3、查询2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率(题源来自LeetCode)

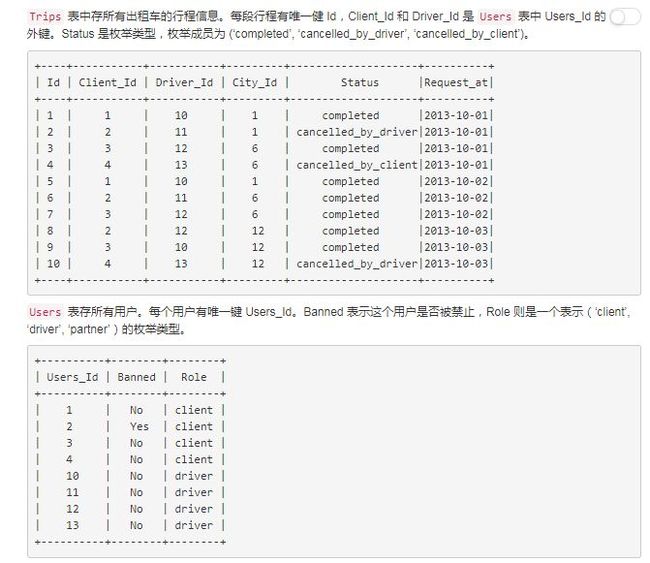


实现逻辑:首先要理解取消率,status状态一栏中,canceled次数占总的比率,我们可以通过sum(case when status like 'cancel%' then 1 else 0 end) 获得次数,从而得到比率,在设置
日期条件和非禁止条件就可以实现了
select t.Request_at as Day, Round(sum(case when t.status like 'cancel%' then 1 else 0 end)/count(*), 2) as 'Cancellation Rate'
from Trips as t join Users as u
on t.Client_id = u.Users_Id and u.Banned = 'No'
where t.Request_at between '2013-10-01' and '2013-10-03' group by t.Request_at主要语法有 round()保留两位, sum()求和, case..when..then..else..end 改变记录值,count(*)统计总数, join联接表,group by按日期分组, between and 区间筛选。