ResNet(一)相关概念
文章目录
- 一、ResNet 介绍
- 1.1 ResNet 由来
- 1.2 深度残差网络 DRN 之恒等映射
- 1.3 34层的深度残差网络的结构图
- 1.4 深度残差网络的结构图实线和虚线
- 1.5 不同层的残差学习单元
- 二、ResNet 结构
- 2.1 ResNet基本架构图
- 2.2 基本参数解释
- 2.3 residual 分支和 identity 分支
- 2.4 Post-activation 和 Pre-activation
- 三、深度学习发展历程
一、ResNet 介绍
1.1 ResNet 由来
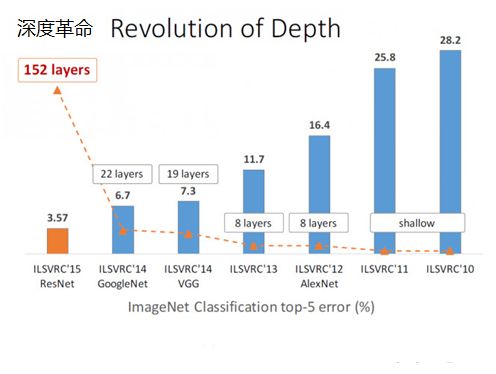
ResNet由微软研究院的kaiming He等4名华人提出,通过使用Residual Unit成功训练152层深的神经网络,在ILSVRC 2015比赛中获得了冠军,取得3.57%的top5错误率,同时参数量却比VGGNet低,效果非常突出。ResNet的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。
ResNet最初的灵感出自这个问题:在不断增加神经网络的深度时,会出现一个Degradation(退化)的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。
1.2 深度残差网络 DRN 之恒等映射
深度残差网络(Deep Residual Network,简称DRN)之恒等映射。
前面描述了一个实验结果现象,在不断加神经网络的深度时,模型准确率会先上升然后达到饱和,再持续增加深度时则会导致准确率下降,示意图如下:
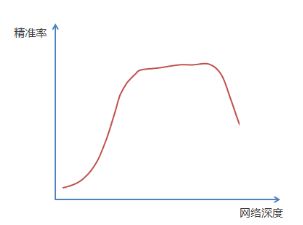
那么我们作这样一个假设:假设现有一个比较浅的网络(Shallow Net)已达到了饱和的准确率,这时在它后面再加上几个恒等映射层(Identity mapping,也即y=x,输出等于输入),这样就增加了网络的深度,并且起码误差不会增加,也即更深的网络不应该带来训练集上误差的上升。而这里提到的使用恒等映射直接将前一层输出传到后面的思想,便是著名深度残差网络ResNet的灵感来源。
ResNet引入了残差网络结构(residual network),通过这种残差网络结构,可以把网络层弄的很深(据说目前可以达到1000多层),并且最终的分类效果也非常好,残差网络的基本结构如下图所示,很明显,该图是带有跳跃结构的:
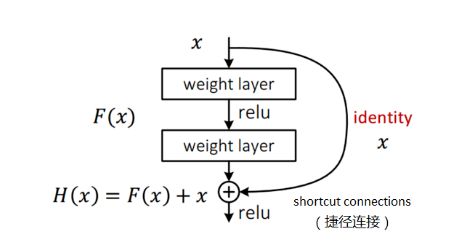
假定某段神经网络的输入是x,期望输出是H(x),即H(x)是期望的复杂潜在映射,如果是要学习这样的模型,则训练难度会比较大;
回想前面的假设,如果已经学习到较饱和的准确率(或者当发现下层的误差变大时),那么接下来的学习目标就转变为恒等映射的学习,也就是使输入x近似于输出H(x),以保持在后面的层次中不会造成精度下降。
在上图的残差网络结构图中,通过shortcut connections(捷径连接) 的方式,直接把输入x传到输出作为初始结果,输出结果为H(x)=F(x)+x,当F(x)=0时,那么H(x)=x,也就是上面所提到的恒等映射。于是,ResNet相当于将学习目标改变了,不再是学习一个完整的输出,而是目标值H(X)和x的差值,也就是所谓的 残差F(x) := H(x)-x,因此,后面的训练目标就是要将残差结果逼近于0,使到随着网络加深,准确率不下降。
这种残差跳跃式的结构,打破了传统的神经网络n-1层的输出只能给n层作为输入的惯例,使某一层的输出可以直接跨过几层作为后面某一层的输入,其意义在于为叠加多层网络而使得整个学习模型的错误率不降反升的难题提供了新的方向。
至此,神经网络的层数可以超越之前的约束,达到几十层、上百层甚至千层,为高级语义特征提取和分类提供了可行性。
1.3 34层的深度残差网络的结构图
下面感受一下34层的深度残差网络的结构图,是不是很壮观:

1.4 深度残差网络的结构图实线和虚线
从图可以看出,怎么有一些“shortcut connections(捷径连接)”是实线,有一些是虚线,有什么区别呢?
因为经过“shortcut connections(捷径连接)”后,H(x)=F(x)+x,如果F(x)和x的通道相同,则可直接相加,那么通道不同怎么相加呢。上图中的实线、虚线就是为了区分这两种情况的:
- 实线的Connection部分,表示通道相同,如上图的第一个粉色矩形和第三个粉色矩形,都是3x3x64的特征图,由于通道相同,所以采用计算方式为H(x)=F(x)+x
- 虚线的的Connection部分,表示通道不同,如上图的第一个绿色矩形和第三个绿色矩形,分别是3x3x64和3x3x128的特征图,通道不同,采用的计算方式为H(x)=F(x)+Wx,其中W是卷积操作,用来调整x维度的。
1.5 不同层的残差学习单元
除了上面提到的两层残差学习单元,还有三层的残差学习单元,如下图所示:

两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。左图是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,右图是第一个1x1的卷积把256维通道降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。
对于常规的ResNet,可以用于34层或者更少的网络中(左图);对于更深的网络(如101层),则使用右图,其目的是减少计算和参数量。
经检验,深度残差网络的确解决了退化问题,如下图(后期更新实验用图)所示,左图为平原网络(plain network)网络层次越深(34层)比网络层次浅的(18层)的误差率更高;右图为残差网络ResNet的网络层次越深(34层)比网络层次浅的(18层)的误差率更低。


二、ResNet 结构
2.1 ResNet基本架构图
-
图1 是2016年ResNet V1 架构图;
1)BN和ReLU在weight的后面;属于常规范畴,我们平时也都这个顺序:Conv → BN → ReLU;
2)最后的ReLU在addition的后面;常规ReLU在addition的前面; -
图(2)的结构为何会阻碍反向传播时的信息。
-
图3 是不work的情况
-
图4 的结构与ResNet原结构伯仲之间,稍稍逊色
-
图5 的结构却好于ResNet原结构,是ResNet V2 架构图
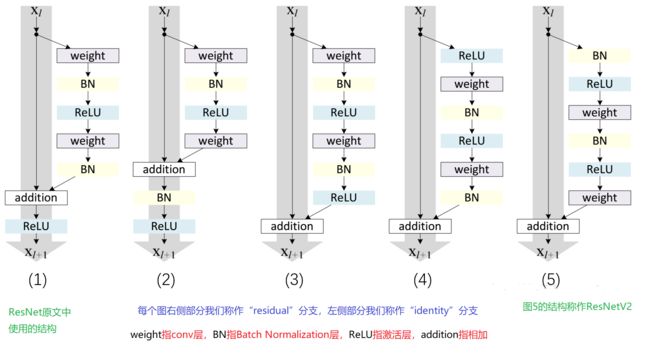
2.2 基本参数解释
- weight指conv层
- BN指Batch Normalization层
- ReLU指激活层
- addition指相加
2.3 residual 分支和 identity 分支
ResNet要尽量保证两点:
1)不轻易改变”identity“分支的值,也就是输入与输出一致;
2)addition之后不再接改变信息分布的层;
对于每个图右侧部分我们称作“residual”分支,左侧部分我们称作“identity”分支”。
如果ReLU作为“residual”分支的结尾,我们不难发现“residual”分支的结果永远非负,这样前向的时候输入会单调递增,从而会影响特征的表达能力,所以我们希望“residual”分支的结果应该在(-∞, +∞);这点也是我们以后设计网络时所要注意的。
- 对于图(3)把ReLU作为“residual”分支的结尾,所以是不work的情况。
- 如图(2),保证了“residual”分支的取值范围;但是,这里BN改变了“identity”分支的分布,影响了信息的传递,在训练的时候会阻碍loss的下降;
2.4 Post-activation 和 Pre-activation
Post-activation”和”Pre-activation”,其中Post和Pre的概念是相对于weight(conv)层来说的,那么我们不难发现,图(1), (2), (3)都是”Post-activation”,图(4), (5)都是”Pre-activation”,那么两种模式哪一个更好呢?这里我们就用实验结果说话。上图是5种结构在Cifar10上的实验结果;一共实验了两种网络ResNet110和ResNet164(注:这里直接摘抄了原文的图片,本人后期将更新最新的实验图);
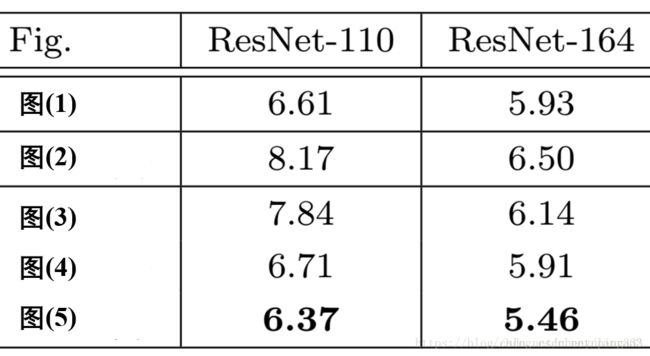
从实验结果上,我们可以发现图(4)的结构与ResNet原结构伯仲之间,稍稍逊色,然而图(5)的结构却好于ResNet原结构,我们通常把图5的结构称作ResNetV2。
图5的结构好的原因在于两点:
1)反向传播基本符合假设,信息传递无阻碍;
2)BN层作为pre-activation,起到了正则化的作用;
三、深度学习发展历程
ResNet在ILSVRC2015竞赛中惊艳亮相,一下子将网络深度提升到152层,将错误率降到了3.57,在图像识别错误率和网络深度方面,比往届比赛有了非常大的提升,ResNet毫无悬念地夺得了ILSVRC2015的第一名。如下图所示:
欢迎学习交流,个人QQ 87605025