FPN解读
前两篇博客中都说到了FPN这个神器,今天就花了点时间看了下这篇论文,喜欢这个很赞很干净的结构。
Motivation
凡是都要从motivation说起,哈哈哈。rcnn系列在单个scale的feature map做检测(b),尽管conv已经对scale有些鲁棒了,但是还是不够。物体各种各样的scale还是是个难题,尤其是小物体,所以有很多论文在这上面做工作,最简单的做法就是类似于数据增强了,train时把图片放缩成不同尺度送入网络进行训练,但是图片变大很吃内存,一般只在测试时放缩图片,这样一来测试时需要测试好几遍时间就慢了(a)。另一种就是SSD的做法©,在不同尺度的feature map上做检测,按理说它该在计算好的不同scale的feature map上做检测,但是它放弃了前面的low-level的feature map,而是从conv4_3开始用而且在后面加了一些conv,生成更多高层语义的feature map在上面检测(我猜想是因为这些low-leve的feature map一是太大了很大地拖慢SSD最追求的速度,二是这些low-level语义信息太差了,效果没太多提升)。
所以本文就想即利用conv net本身的这种已经计算过的不同scale的feature,又想让low-level的高分辩的feature具有很强的语义,所以自然的想法就是把high-level的低分辨的feature map融合过来。类似的工作还有RON: Reverse Connection with Objectness Prior Networks for Object Detection

Approach
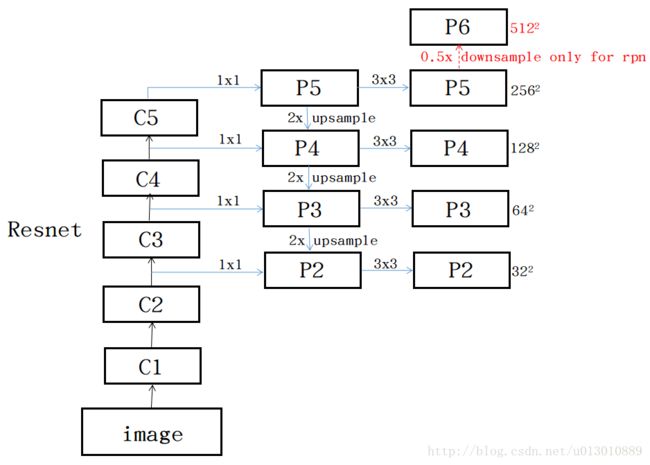
做法很简单,down-top top-down lateral conn(侧路连接)如图所示。以Resnet101为例:
- down-top就是每个residual block(C1去掉了,太大太耗内存了),scale缩小2,C2,C3,C4,C5(1/4, 1/8, 1/16, 1/32)。
- top-down就是把高层的低分辨强语义的feature 最近邻上采样2x
- lateral conn 比如把C2通过1x1卷积调整channel和top-down过来的一样,然后两者直接相加
通过上述操作一直迭代到生成最好分辨率的feature(此处指C2)

具体迭代操作:
- 从C5(512)开始加个1*1到256个channel,生成分辨率最低但语义最强的feature P5,开始迭代
- 然后P5上采样放大2倍,C4经过一个1*1的卷积后和放大后P5尺寸什么都一样了,然后add
- 以此迭代下去到P2结束
- 每个Pk后加一个3*3的卷积(原文说reduce the aliasing effect of upsampling)
详细可下面代码
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# 扔掉了C1
_, C2, C3, C4, C5 = resnet_graph(input_image, "resnet101", stage5=True)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(256, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(256, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(256, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(256, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(256, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]
Experiments
RPN
首先想证明这个FPN对RPN有效果。如图所示,每个level的feature P2,P3,P4,P5,P6只对应一种scale,比例还是3个比例。
还有一个问题,RPN生成roi后对应feature时在哪个level上取呢?
k0是faster rcnn时在哪取的feature map如resnet那篇文章是在C4取的,k0=4(C5相当于fc,也有在C5取的,在后面再多添加fc),比如roi是w/2,h/2,那么k=k0-1=4-1=3,就在P3取

还有个问题,从不同level取feature做roipooling后需要分类和回归,这些各个level需要共享吗?本文的做法是共享,还有一点不同的是resnet论文中是把C5作为fc来用的,本文由于C5已经用到前面feature了,所以采用在后面加fc6 fc7,注意这样是比把C5弄到后面快一点。
实验结果如下,RPN的召回率高出baseline10个点左右的
(d)是去掉top-down,即类似于SSD在各个不同scale的feature上做预测
(e)是没有lateral,那就是只把低分辨强语义的feature上采样放大做预测
(f)这个是只用迭代到最后分辨率最高的P2,所有scale和比例的anchor都在P2取,由于P2比较大所有scale都在它上面取,anchor数量提升了很多,速度会慢。它的精度好于baseline但是低于©,原文解释:RPN is a sliding window detector with a fixed window size, so scanning over pyramid levels can increase its robustness to scale variance. 就是解释而已,怎么说都是他对…

Fast/Faster RCNN
直接使用上一步生成的proposal(Fast RCNN)

和RPN共享feature(Faster RCNN),证明end2end还是有提升的

在COCO的test榜单上也是state-of-art,注意它是单模型,其他经过了各种融合等工程化手段

FPN也可以利用instance segmentation任务中,比如mask rcnn等