为什么80%的码农都做不了架构师?>>> 
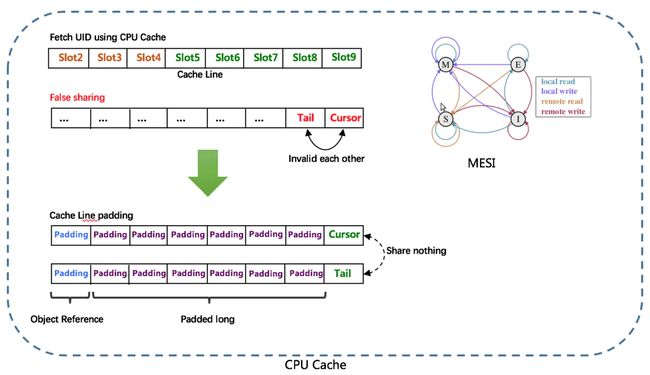
UidGenerator是Java实现的, 基于Snowflake算法的唯一ID生成器。UidGenerator以组件形式工作在应用项目中, 支持自定义workerId位数和初始化策略, 从而适用于docker等虚拟化环境下实例自动重启、漂移等场景。 在实现上, UidGenerator通过借用未来时间来解决sequence天然存在的并发限制; 采用RingBuffer来缓存已生成的UID, 并行化UID的生产和消费, 同时对CacheLine补齐,避免了由RingBuffer带来的硬件级「伪共享」问题. 最终单机QPS可达600万。
依赖版本:Java8及以上版本, MySQL(内置WorkerID分配器, 启动阶段通过DB进行分配; 如自定义实现, 则DB非必选依赖)
Snowflake算法

Snowflake算法描述:指定机器 & 同一时刻 & 某一并发序列,是唯一的。据此可生成一个64 bits的唯一ID(long)。默认采用上图字节分配方式:
-
sign(1bit)
固定1bit符号标识,即生成的UID为正数。 -
delta seconds (28 bits)
当前时间,相对于时间基点"2016-05-20"的增量值,单位:秒,最多可支持约8.7年 -
worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 -
sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。
以上参数均可通过Spring进行自定义
CachedUidGenerator
RingBuffer环形数组,数组每个元素成为一个slot。RingBuffer容量,默认为Snowflake算法中sequence最大值,且为2^N。可通过boostPower配置进行扩容,以提高RingBuffer 读写吞吐量。
Tail指针、Cursor指针用于环形数组上读写slot:
-
Tail指针
表示Producer生产的最大序号(此序号从0开始,持续递增)。Tail不能超过Cursor,即生产者不能覆盖未消费的slot。当Tail已赶上curosr,此时可通过rejectedPutBufferHandler指定PutRejectPolicy -
Cursor指针
表示Consumer消费到的最小序号(序号序列与Producer序列相同)。Cursor不能超过Tail,即不能消费未生产的slot。当Cursor已赶上tail,此时可通过rejectedTakeBufferHandler指定TakeRejectPolicy
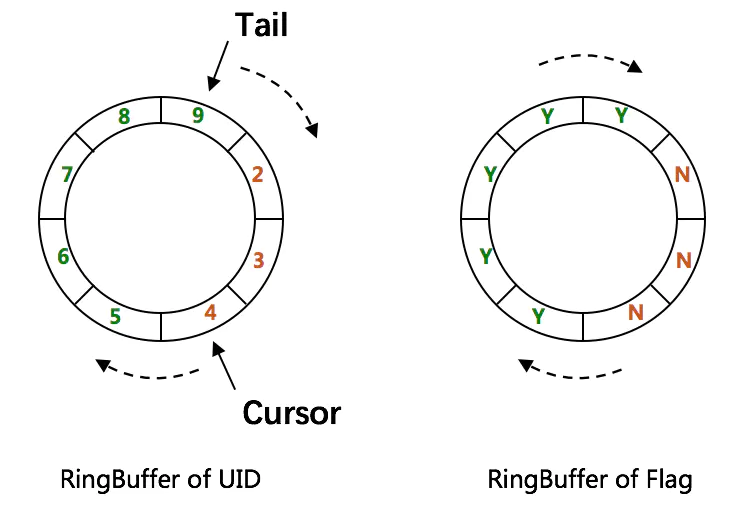
CachedUidGenerator采用了双RingBuffer,Uid-RingBuffer用于存储Uid、Flag-RingBuffer用于存储Uid状态(是否可填充、是否可消费)
由于数组元素在内存中是连续分配的,可最大程度利用CPU cache以提升性能。但同时会带来「伪共享」FalseSharing问题,为此在Tail、Cursor指针、Flag-RingBuffer中采用了CacheLine 补齐方式。
RingBuffer填充时机
-
初始化预填充
RingBuffer初始化时,预先填充满整个RingBuffer. -
即时填充
Take消费时,即时检查剩余可用slot量(tail-cursor),如小于设定阈值,则补全空闲slots。阈值可通过paddingFactor来进行配置,请参考Quick Start中CachedUidGenerator配置 -
周期填充
通过Schedule线程,定时补全空闲slots。可通过scheduleInterval配置,以应用定时填充功能,并指定Schedule时间间隔
Quick Start
这里介绍如何在基于Spring的项目中使用UidGenerator, 具体流程如下:
步骤1: 安装依赖
先下载Java8, MySQL和Maven
设置环境变量
maven无须安装, 设置好MAVEN_HOME即可. 可像下述脚本这样设置JAVA_HOME和MAVEN_HOME, 如已设置请忽略.
export MAVEN_HOME=/xxx/xxx/software/maven/apache-maven-3.3.9
export PATH=$MAVEN_HOME/bin:$PATH
JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_91.jdk/Contents/Home";
export JAVA_HOME;步骤2: 创建表WORKER_NODE
运行sql脚本以导入表WORKER_NODE, 脚本如下:
DROP DATABASE IF EXISTS `xxxx`;
CREATE DATABASE `xxxx` ;
use `xxxx`;
DROP TABLE IF EXISTS WORKER_NODE;
CREATE TABLE WORKER_NODE
(
ID BIGINT NOT NULL AUTO_INCREMENT COMMENT 'auto increment id',
HOST_NAME VARCHAR(64) NOT NULL COMMENT 'host name',
PORT VARCHAR(64) NOT NULL COMMENT 'port',
TYPE INT NOT NULL COMMENT 'node type: ACTUAL or CONTAINER',
LAUNCH_DATE DATE NOT NULL COMMENT 'launch date',
MODIFIED TIMESTAMP NOT NULL COMMENT 'modified time',
CREATED TIMESTAMP NOT NULL COMMENT 'created time',
PRIMARY KEY(ID)
)
COMMENT='DB WorkerID Assigner for UID Generator',ENGINE = INNODB;修改mysql.properties配置中, jdbc.url, jdbc.username和jdbc.password, 确保库地址, 名称, 端口号, 用户名和密码正确.
步骤3: 修改Spring配置
提供了两种生成器: DefaultUidGenerator、CachedUidGenerator。如对UID生成性能有要求, 请使用CachedUidGenerator
对应Spring配置分别为: default-uid-spring.xml、cached-uid-spring.xml
DefaultUidGenerator配置
CachedUidGenerator配置
Mybatis配置
mybatis-spring.xml配置说明如下:
步骤4: 运行示例单测
运行单测CachedUidGeneratorTest, 展示UID生成、解析等功能
@Resource
private UidGenerator uidGenerator;
@Test
public void testSerialGenerate() {
// Generate UID
long uid = uidGenerator.getUID();
// Parse UID into [Timestamp, WorkerId, Sequence]
// {"UID":"180363646902239241","parsed":{ "timestamp":"2017-01-19 12:15:46", "workerId":"4", "sequence":"9" }}
System.out.println(uidGenerator.parseUID(uid));
}关于UID比特分配的建议
对于并发数要求不高、期望长期使用的应用, 可增加timeBits位数, 减少seqBits位数. 例如节点采取用完即弃的WorkerIdAssigner策略, 重启频率为12次/天, 那么配置成{"workerBits":23,"timeBits":31,"seqBits":9}时, 可支持28个节点以整体并发量14400 UID/s的速度持续运行68年.
对于节点重启频率频繁、期望长期使用的应用, 可增加workerBits和timeBits位数, 减少seqBits位数. 例如节点采取用完即弃的WorkerIdAssigner策略, 重启频率为24*12次/天, 那么配置成{"workerBits":27,"timeBits":30,"seqBits":6}时, 可支持37个节点以整体并发量2400 UID/s的速度持续运行34年.
吞吐量测试
在MacBook Pro(2.7GHz Intel Core i5, 8G DDR3)上进行了CachedUidGenerator(单实例)的UID吞吐量测试.
首先固定住workerBits为任选一个值(如20), 分别统计timeBits变化时(如从25至32, 总时长分别对应1年和136年)的吞吐量, 如下表所示:
| timeBits | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
|---|---|---|---|---|---|---|---|---|
| throughput | 6,831,465 | 7,007,279 | 6,679,625 | 6,499,205 | 6,534,971 | 7,617,440 | 6,186,930 | 6,364,997 |
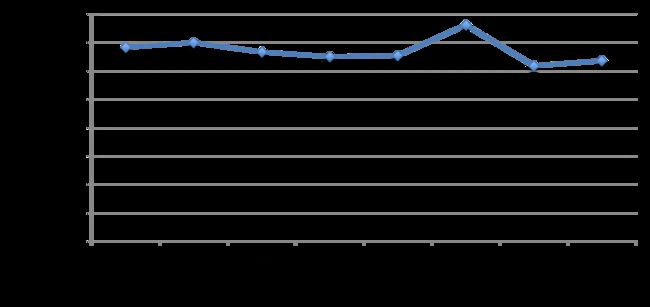
再固定住timeBits为任选一个值(如31), 分别统计workerBits变化时(如从20至29, 总重启次数分别对应1百万和500百万)的吞吐量, 如下表所示:
| workerBits | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 |
|---|---|---|---|---|---|---|---|---|---|---|
| throughput | 6,186,930 | 6,642,727 | 6,581,661 | 6,462,726 | 6,774,609 | 6,414,906 | 6,806,266 | 6,223,617 | 6,438,055 | 6,435,549 |

由此可见, 不管如何配置, CachedUidGenerator总能提供600万/s的稳定吞吐量, 只是使用年限会有所减少. 这真的是太棒了.
最后, 固定住workerBits和timeBits位数(如23和31), 分别统计不同数目(如1至8,本机CPU核数为4)的UID使用者情况下的吞吐量,
| workerBits | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| throughput | 6,462,726 | 6,542,259 | 6,077,717 | 6,377,958 | 7,002,410 | 6,599,113 | 7,360,934 | 6,490,969 |
