论文阅读context-aware crowd counting
摘要
经典做法是在整张图上采用同样的滤波器,通过估计局部比例来补偿透视失真。
2、相关工作
早期的人群计数工作主要采取检测方法,即检测出每个头或人体,然后计数。但是,对于拥挤的场景来说,遮挡会使检测变得很困难,因此,大部分情况下,检测方法就被密度估计图替代,即:训练一个回归器,对图片中的不同部分估计密度图,然后综合各个密度图得到原始图片的人数,这种方法法主要利用高斯函数或随机森林方法。尽管这些方法主要依赖于低级特征,但其效果挺好。现在,大家主要基于CNN方法来回归密度图。
我们要测量的人群密度是地面上单位面积内人的数量。
3、1:尺度感知上下文特征
论文把人群计数问题转化为人群密度回归问题。给定一个含有N张训练图片的数据集![]() ,对应的ground-truth密度图为
,对应的ground-truth密度图为![]()
论文目标是学习一个具有参数 的非线性映射F,将输入图片
的非线性映射F,将输入图片 映射为一个估计的密度图
映射为一个估计的密度图
![]()
使得估计值![]() 与真实值
与真实值![]() 在
在 范数下距离足够近。
范数下距离足够近。
与传统做法相同,前面10层为预训练的VGG-16网络,给定一张图片I,输出为
![]() (1)
(1)
论文把f_v当做基础特征。
但是,![]() 具有一定的局限性,因为其在整张图片上具有相同的感受野。为了客服这个缺陷,论文用特征金字塔来计算尺度特征,在
具有一定的局限性,因为其在整张图片上具有相同的感受野。为了客服这个缺陷,论文用特征金字塔来计算尺度特征,在![]() 的基础上,提取多尺度的上下文信息。计算公式为
的基础上,提取多尺度的上下文信息。计算公式为
![]()
其中,对每个尺度j,![]() 将VGG特征平均为k(j)*k(j)块。F_j是一个卷即核尺寸=1的卷积网络,它将不同通道的特征,在不改变维度的情况下啊,连接在一起。论文这样做的原因是SPP保证了每个特征通道的独立性,因此限制了代表权。论文作者证明了若不做这个,网络性能下降,这也与以前的工作(通常卷积做降维)相反。
将VGG特征平均为k(j)*k(j)块。F_j是一个卷即核尺寸=1的卷积网络,它将不同通道的特征,在不改变维度的情况下啊,连接在一起。论文这样做的原因是SPP保证了每个特征通道的独立性,因此限制了代表权。论文作者证明了若不做这个,网络性能下降,这也与以前的工作(通常卷积做降维)相反。
![]() 代表以双线性插值方式进行上采样,使得特征图与f_v具有相同的维度。
代表以双线性插值方式进行上采样,使得特征图与f_v具有相同的维度。
实际中,论文采用了S=4种不同的尺寸,相对应为![]() ,经作者试验,相对于其他尺寸,这4个尺寸的表现性能更好。
,经作者试验,相对于其他尺寸,这4个尺寸的表现性能更好。
使用论文的尺度感知特征方法,最简单的做法就是将其连接到原始的VGG特征图f_v之后。但,这样不能有效解释尺度会随着图像变化而变化。为了阐述这个事实,作者建议学习预测权重图,在每个空间位置设置每个尺度感知特征的相对影响。此处,定义对比特征为
![]() (3)
(3)
它可以捕捉到在特定空间位置和邻域的特征的不同,它是一个显著的视觉线索。例如,在下图中,我们会首先注意到位于图像中央的女人,因为图像其余部分的边缘都指向她的方向,而她所在位置的边缘不指向。这些对比度特征为我们提供了了解每个图像区域的局部尺度的重要信息。

因此,我们利用它们作为具有权重![]() 的辅助网络的输入,这个辅助网络可以计算权重w_j,w_j是每个S的尺度。
的辅助网络的输入,这个辅助网络可以计算权重w_j,w_j是每个S的尺度。
每个网络会输出一个特定尺寸的权重:
![]() (4)
(4)
其中:
![]() 是一个1×1卷积层,后面跟了一个sigmoid函数来避免被0除。然后,根据这些权重可以得到语境特征
是一个1×1卷积层,后面跟了一个sigmoid函数来避免被0除。然后,根据这些权重可以得到语境特征
![f_I=[f_v|\frac{\sum_{j=1}^{S}w_j\bigodot s_j}{\sum_{j=1}^{S}w_j}]](http://img.e-com-net.com/image/info8/01ff0a8cdaa2435d86538b5e6c44eb34.gif) (5)
(5)
其中[.|.]代表通道级连接操作, 是权重图和特征图的元素乘积。整个过程可以用下图表示
是权重图和特征图的元素乘积。整个过程可以用下图表示
3.2. 几何知道的上下文学习
因为透视失真,适用于每个区域的上下文范围在图像平面上各不相同,因此,场景几何与上下文信息密切相关,可以用来指导网络更好地适应其所需的场景上下文。因此,论文扩展了以前的方法来开发可用的几何信息。方便起见,我们用
代表图像,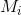 代表对应的透视图(其编码了图像中每平方米的像素数,这个透视图与原图像具有相同的空间分辨率),论文将其作为截断的VGG-16网络的输入,也就是说,等式(1)的特征将被下式替代
代表对应的透视图(其编码了图像中每平方米的像素数,这个透视图与原图像具有相同的空间分辨率),论文将其作为截断的VGG-16网络的输入,也就是说,等式(1)的特征将被下式替代
![]()
其中,![]() 是一个修改过的单通道的VGG网络。为摘初始化这个通道的权重,我们对原始的RGB三通道中进行平均。
是一个修改过的单通道的VGG网络。为摘初始化这个通道的权重,我们对原始的RGB三通道中进行平均。
另外,论文对透视图进行了归一化,与RGB图片的范围一致。尽管这种初始化方式在最终的计数准确度上没有带来显著的变化,但它能够使收敛的更快。
为了进一步地将几何信息传播到我们的后续网络,我们将上述的VGG特征输入公式(4)中辅助网络,其本质上包含几何信息。特别地,每个尺度的权重图由下式计算:
![]() (7)
(7)
这些权重图会在等式(5)中用到。
3.3. 训练细节和损失函数
无论是否具有几何信息,论文的网络均采用了如下定义的损失函数
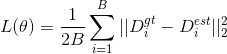 (8)
(8)
其中,B是batch size. ![]() 是ground-truth密度图。特别地,对每张图I_i, 会有一个2D集合
是ground-truth密度图。特别地,对每张图I_i, 会有一个2D集合
![]()
记录场景中每个人头的位置。
密度图![]() 是由具有
是由具有![]() 高斯核按照如下公式计算
高斯核按照如下公式计算
 (9)
(9)
其中![]() 代表正态分布的均值和方差,本论文中
代表正态分布的均值和方差,本论文中 是用的固定值。(问题,c_i是什么?)
是用的固定值。(问题,c_i是什么?)
为最小化损失函数(8),论文采用SGD和Adam,当数据集中图片尺寸不一样,batch_size=1,图片尺寸一样时,bath_size=32.
另外,训练中,随机在1/4的位置上对图片进行裁剪。
4、实验
这一部分主要是对论文提出的方法做评价,论文首先介绍了实验中用到的评价方式和评价数据集,然后将论文方法与其他流行的方法做了比较。
4、1 评价指标
以前在密集人群的评价主要采用MAE(mean absolute error)平均绝对误差和均方误差的平方根RMSE(root mean squared error)作为评价指标之。他们的定义如下:
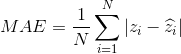

其中,N是测试图片的个数,z_i代表第i张图片的真实人数,![]() 代表第i张图片的预测人数。
代表第i张图片的预测人数。
注记:
网络的输出是一张密度图,对应的人数可以按照下面公式计算:
![]()
4.2 数据集和ground-truth 数据
论文采用了5个不同的数据集进行比较。前4个数据集是最近几篇文章发布的,第5个数据集是作者们在积极制作的,并将尽快开源。
ShanghaiTech, 这个数据集包含了1198张标注图像,共含有330165个人。被分为A和B数据集,
其中A数据集含有482张图片,300张在训练集中,
B数据集包含716张图片,400张在训练集中。
为进行比较,我们以相同的方式生成密度图,特别地,对Part A,采用论文《Single-Image Crowd Counting via Multi-
Column Convolutional Neural Network》介绍的几何自适应核,对part B,用固定核。
UCF-QNRF:数据集中包含了1535张图片,共1251642个人,训练集中有1201张图片。不像ShanghaiTech,数据集中的分辨率和尺度变化很不相同,密度图通过自适应高斯核生成。
UCF-CC-50:数据集中仅包含50张图片,人数从94到4543个,对深度学习的挑战比较大。采用固定核和交叉验证,将图像分成组,取出其中4组用于训练,其他的用于测试
网络结构,主要包含4个部分
x = self.frontend(x)
x = self.context(x)
x = self.backend(x)
x = self.output_layer(x)先来看第一部分:frontend()
self.frontend_feat = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512]
self.frontend = make_layers(self.frontend_feat)
def make_layers(cfg, in_channels = 3,batch_norm=False,dilation = False):#dilation:膨胀
if dilation:
d_rate = 2
else:
d_rate = 1
layers = []
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=d_rate,dilation = d_rate)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
可以看出,网络结构共有10个卷积层为
conv1+relu1+conv2+relu2+pool1+conv3+relu3+conv4+relu4+pool2+conv5+relu5+conv6+relu6+conv7+relu7+pool3+conv8+relu8+conv9+relu9+conv10+relu10+pool4
第二部分:context
self.context = ContextualModule(512, 512)
class ContextualModule(nn.Module):
def __init__(self, features, out_features=512, sizes=(1, 2, 3, 6)):
super(ContextualModule, self).__init__()
self.scales = []
self.scales = nn.ModuleList([self._make_scale(features, size) for size in sizes])
self.bottleneck = nn.Conv2d(features * 2, out_features, kernel_size=1)
self.relu = nn.ReLU()
self.weight_net = nn.Conv2d(features,features,kernel_size=1)
def __make_weight(self,feature,scale_feature):
weight_feature = feature - scale_feature
return F.sigmoid(self.weight_net(weight_feature))
def _make_scale(self, features, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, features, kernel_size=1, bias=False)
return nn.Sequential(prior, conv)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
multi_scales = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.scales]
weights = [self.__make_weight(feats,scale_feature) for scale_feature in multi_scales]
overall_features = [(multi_scales[0]*weights[0]+multi_scales[1]*weights[1]+multi_scales[2]*weights[2]+multi_scales[3]*weights[3])/(weights[0]+weights[1]+weights[2]+weights[3])]+ [feats]
bottle = self.bottleneck(torch.cat(overall_features, 1))
return self.relu(bottle)第三部分backend()
self.backend = make_layers(self.backend_feat,in_channels = 512,batch_norm=True, dilation = True)第四部分 output_layer(),就是一个普通的卷积层
self.output_layer = nn.Conv2d(64, 1, kernel_size=1)