强化学习6大前沿算法复现 | 乘风破浪,热情不减
点击左上方蓝字关注我们

学习成就梦想,AI遇见未来。作为国内AI行业的重要一员,百度不仅在人工智能的研究应用上做出了巨大贡献,还致力于培养和选拔最具核心竞争力的AI人才。
强化学习作为人工智能的热门研究领域之一,对发展人机交互、无人驾驶等技术具有重要意义,百度飞桨推出了强化学习的系列课程,帮助更多开发者进入强化学习领域。

强化学习,风声再起
自6月推出《深度学习7日打卡营-世界冠军带你从零实践强化学习》公开课后,同学们反响强烈,掀起了一波强化学习的热潮。
为帮助大家更深入的理解强化学习背后的算法理论,7月14日,课程推出了“你学习,我送书,一起来爬RL的大山”的共学活动。
此次活动提供了六大强化学习经典进阶算法资料:DQN_variant、A2C、PPO、SAC、TD3、MADDPG,同学们可以任选一个感兴趣的算法进行钻研,并输出自己对算法本身,以及基于PARL实现的代码细节的理解。
众人拾柴火焰高,此次我们也特地邀请到了共学活动的评审团成员,用最精炼的语言带大家速览强化学习六大前沿算法!
DQN_variant算法
——Tiny Tony、Kevin pang
要说DQN_variant就要从DQN说起
DQN可以理解为Q-Learning + Deep Learning, 然而实际如果简单合并这两个概念会让训练变得不稳定。因此DQN论文引入了卷积神经网络,并提出两大利器,用于解决DL和RL结合时遇到的问题:
1) 经验回放:主要解决样本关联性和利用效率的问题。使用一个经验池存储多条经验(s,a,r,s),再从中随机抽取一批数据送去训练。
2) 固定Q目标:主要解决算法训练不稳定的问题。复制一个和原来Q网络结构一样的目标Q网络,用于计算Q目标值。
更新:
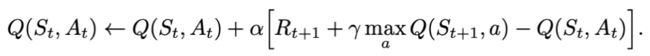
算法:

比DQN更进一步的Double DQN
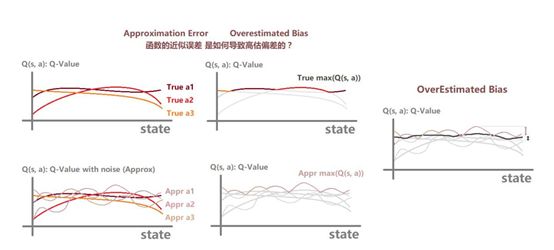
Double DQN是DQN的一种改进,旨在解决DQN训练过程中存在的过估计(Over Estimate)问题。在训练过程中,Double DQN首先使用预测网络(Predict Q Network)计算下一个State的对应各个Action的Q值,然后选取最大的那个Q值对应Action的索引,再使用目标网络(Target Q Network)计算该状态的对应各个状态的Q值,然后选取预测网络中给定Action索引对应的Q值,但是它可能不是最大的那个,从而一定程度上避免了过度估计,提高了训练DQN的稳定性和速度。
实验结果也证明,Double DQN有效地防止了过度估计。注意Double DQN利用了DQN的Target Q Network,所以其实并没有比DQN多使用一个网络。
更新:
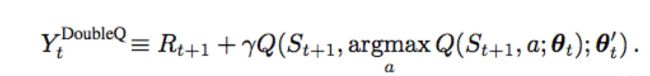
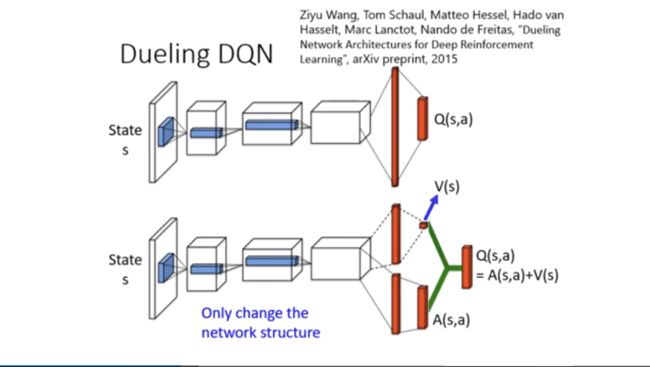
结构上创新的Dueling DQN
Dueling DQN是一种网络结构上的创新,其将网络分成了两部分:值函数和优势函数。
在更新网络时,让模型更倾向于去更新V而不是更新A,这是一种比较有效率的做法。
评
审
团
说
通过此次学习和评审,我们发现,算法的更新与发展离不开对前人成果的分析和学习。因为,在对前人的成果学习的过程中,我们即加深了自己对此类算法的认识与理解,又锻炼了自己的算法复现能力。
因此,接下来,在学习了前人成果经验的基础上,若能将其熟练运用,必能对其优缺点有更为深刻的认识。进而,我们就能在此类算法的发展上、继续提出新的问题、解决问题。在这个不断完善的过程中,我们就有可能写出一个属于自己的算法,甚至有可能让自己的算法成为里程碑式的进步。
PPO算法
——super松、Agravity
Policy Gradient作为policy-based较为基础的算法,有其简单直观的特性,但同时它也有很多弊端,譬如样本利用率底以及使用梯度更新错误步长带来的模型塌陷的问题。在网络中参数的小改动都可能带来策略分布的巨大变化。
为了能够更多更好的利用已有的数据,利用重要性采样,使得用于更新的样本更贴近于新策略产生的样本。PPO论文中的两种提供了两种方法,一种是针对TRPO中约束项权重不好求解,使用一种动态的方式来调整新旧策略散度的权重;第二种则使用clip的方式,直接限制了更新的“步长”。
PPO解决了On-policy转Off-policy时p(x)分布与q(x)分布相差较大的问题.KL散度来计算p(x)分布与q(x)分布差异,并将KL加入PPO模型的似然函数,并采用合理适配β来惩罚KL。(摘自“如意_鸡蛋”的AIStudio项目)
PPO算法是利用了重要性采样的思想,在不知道策略路径的概率p情况下,通过模拟一个近似的q分布,只要p同q分布不差得太远,通过多轮迭代可以快速参数收敛。(摘自“tostq”的CSDN博客)
评
审
团
说
aitrust同学在mujoco环境上训练了“猎豹跑步”,并制作了有趣的B站视频《强化学习算法PPO让猎豹学会奔跑!》,已一键三连。另外几位同学也都尝试了gym的其他环境。其实可以扩展思路去尝试更多的环境和游戏,解决更多实际的问题。
SAC算法
——✌ VividChloe、倪侃_eval()
Actor-Critic框架是一种经典的强化学习结构,评论家Critic通过Q网络评价状态s下动作a预期得到的回报r,表演者Actor遵循策略网络,根据所处状态s输出合适的动作a。
在上述AC框架中作各种改动,就形成了SAC、DDPG、PPO等具体的强化学习算法。
其中,SAC算法在策略目标中加入了熵项(entropy),以期在策略收益最大化的同时使其本身的熵最大,使策略网络具有良好的探索性,避免陷入局部最优。通过引入熵正则化项,传统ReinforcementLearning变为Maximum Entropy Reinforcement Learning(MERL)。相应地,Q函数、V函数也引入了熵项,形成SoftValue Function(SVF)。
在策略选择中,SAC采用了基于能量的模型(EnergyBased Policy,EBP),相比于传统强化学习中的确定性策略模型,EBP中,action值的概率分布贴合Q函数的分布,避免了传统RL中action过于单一的缺陷。传统RL及基于EBP的策略选择图示分别如下图所示:
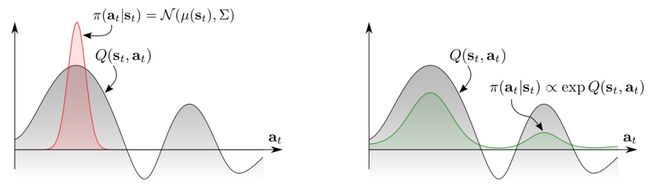
a传统RL策略选择图示
b基于EBP的策略选择图示
在具体的算法实现中,SAC算法为了解决连续空间问题借鉴了SoftPolicy迭代思想,选择随机梯度优化两个网络进行更新。同时为了防止策略提升中产生的过估计现象,独立训练两个Q网络并选择其中较小的估计结果对actor网络进行更新。
评
审
团
说
本次共有三名同学提交SAC学习文章,分别以rlschool库中的四轴飞行器悬停任务或经典的倒立摆控制任务完成了SAC算法实践。通过采用百度强化学习工具库Parl,原本晦涩的SAC实现过程简化为范式化的几十行核心代码。
如意_鸡蛋同学通过SAC算法在经典的倒立摆实例中得分稳步提升,最终获得14766分的结果,体现出SAC算法探索性强,收敛性好等优点,很赞。
TD3算法
——七年期限、不再是pytorch那个少年
TD3(Twin Delayed Deep Deterministic Policy Gradient)是一种面向连续动作空间基于Actor-Critic架构的深度强化学习算法,在DDPG算法基础上,同时对policy网络和value网络进行改进,优化了Q-Value的过高估计问题。
1.使用与双Q学习(Double DQN)相似的思想:使用两个Critic(估值网络Q(s, a))对动作-值进行评估,训练的时候取
![]()
作为估计值,这个结构可以用很小的改动加入到其他算法中,
2.使用延迟学习:更新估值函数的频率大于策略函数
3.使用软更新:更新的时候不直接复制网络参数,而是
![]()
4.使用梯度截取:将用于Actor(策略网络)参数更新的梯度截取到某个范围内
5.使用策略噪声:TD3不仅和其他算法一样,使用epsilon-Greedy 在探索的时候使用了探索噪声,而且还使用了策略噪声,在update参数的时候,用于平滑策略期望。
评
审
团
说
最终一共有五位同学参与了TD3算法活动,其中有几位同学用TD3算法挑战了《再战大作业,助你摆脱大作业难以收敛的恐惧》,是不是只看标题就让你想起了大作业不收敛的恐惧,现在它来了,蠢蠢欲动的你还不来试试吗!!!
大家也是非常认真,将TD3算法安装中遇到的问题、与DDPG算法的差别和代码的差别都为大家进行了标注,有不懂的同学欢迎观看各位大佬的文章,为他们打Call。
A2C算法
——Yao、木兰佳
A2C全称为优势动作评论算法(Advantage Actor Critic),也是属于Policy算法族的,是在Policy Gradient的基础上拆分出两个网络Critic和Actor。A2C使用优势函数代替Critic网络中的原始回报,优势函数可以作为衡量选取动作值和所有动作平均值好坏的指标。
![]()
优势函数
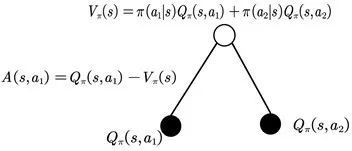
优势函数示意图
状态值函数:该状态下所有可能动作所对应的动作值函数乘以采取该动作的概率的和。
动作值函数:该状态下的a动作对应的值函数。
优势函数:动作值函数相比于当前状态值函数的优势。
如果优势函数大于零,则说明该动作比平均动作好,如果优势函数小于零,则说明当前动作还不如平均动作好。
评
审
团
说
A2C:Policy Gradient下属算法之一,此次作业中Brisingrsdsz同学在AI Studio上面做了相当详细的讲解:A2C的背景、REINFORCE、AC以及A2C和A3C间的优劣区别,从文章中看得出该同学对论文也是“情有独钟”,很是佩服,一位功底很深的研究僧,期待下次的RL文章。各位加油呀~~~,乌拉~~~
MADDPG算法
——孙顺????、Mr.郑先生_????
强化学习中很多场景中都涉及到多个智能体的交互,比如多个机器人的控制,多玩家游戏等等。
传统的PG(policy gradient)算法和 Q-Learning方法都不适应多智能体的环境,主要是因为每个智能体都有自己的策略,从任意一个智能体的角度上看,其他智能体的策略在不断的变化,这样的动态不确定环境对于单个智能体的策略学习是非常不稳定的。(摘自“AI在打野”的知乎作业)
对DQN算法来说,经验回放的方法变的不再适用,因为如果不知道其他智能体的状态,那么不同情况下自身的状态转移会不同。对PG算法来说,环境的不断变化导致了学习的方差进一步增大。(摘自“Mr.郑先生_”的CSDN博客)
为了克服上述问题,有研究者提出了MADDPG(Multi-Agent Deep Deterministic Policy Gradient)方法【论文链接】https://arxiv.org/pdf/1706.02275.pdf。大家可以注意到MADDPG后面的4个字母是“DDPG”,其实MADDPG方法的确是使用DDPG作为基准模型。(摘自“AI在打野”的知乎作业)

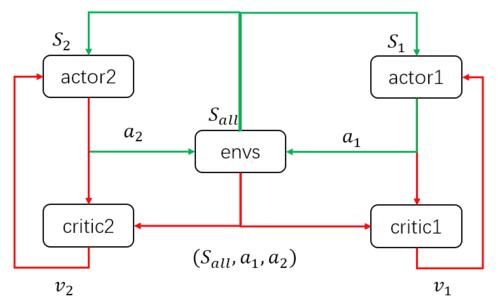
上图是论文里面MADDPG的伪代码,可以看到MADDPG和DDPG是类似的,但最主要的不同在于:在DDPG算法中,Critic的输入是自身的观测-行动数据,而MADDPG中,每个Agent的Critic除了输入自身的observation、action信息外,还有其他agent的action、observation等信息,也就是说MADDPG的Critic可以从更宏观的视角给Actor“打分”。(摘自“AI在打野”的知乎作业)
换言之,MADDPG就是令每个Agent的Critic部分能够获取其余所有Agent的动作信息,进行中心化训练和非中心化执行,即在训练的时候,引入可以观察全局的Critic来指导Actor训练,而测试的时候只使用有局部观测的actor采取行动。多智能体学习示意图如下图所示(摘自“Mr.郑先生_”的CSDN博客):
评
审
团
说
MADDPG算法的难点就在于多智能体与环境的交互上,多智能体之间又有合作与竞争,这在我们的生活中也是类似的,比如一场激动人心的篮球赛或是足球赛,我们既要学会和队友合作,又跟对手有竞争关系。假如我们融入其中(假设自己就是篮球场/足球场上的一位球员),你有没有想过,有哪些策略能让所在队伍的得分最高?
在学习算法的同时回归生活,往往会有新的发现!
百度AI Studio课程平台
看到这你是不是也心动了?可自己错过了课程怎么办!?
别担心,我们的强化学习课程现在还可以学习,扫码加入课程,即可观看完整课节内容,亲自动手实践,遇到作业问题还可以到讨论区寻找答案。

课程精华版也已经在B站发布,快来一起学习刷弹幕吧!

榜单公布:
学习送书活动获奖名单
秉持着公正、公开的原则,经过评审团日日夜夜的认真评议,共学活动的获奖名单终于出炉!想了解具体的代码实现,请移步课程讨论区查看项目链接。
DQN_variant
强化学习圣经:深渊上的坑、三岁、jy_503、秋水中的鱼、阿布军师
A2C
强化学习圣经:Brisingrsdsz、wjswmxb、jy_503、__y__、醉爱墨
PPO
强化学习圣经:aitrust、如意_鸡蛋、tos氏龙
SAC
强化学习圣经:YY应觉月光寒、如意_鸡蛋、liuleifeichuan
TD3
强化学习圣经:thunder95、AI在打野、nanting03、如意_鸡蛋
MADDPG
强化学习圣经:AI在打野、hujx、forrestneo、huangdihe、jsdbzcm、shipeng20041
恭喜以上获奖同学,礼品将会按照毕业信息的地址发出。欢迎大家参与更多的百度飞桨课程,超多惊喜好礼等着你!
特别鸣谢:百度官方帮帮团成员
此次活动特别感谢以下百度飞桨官方帮帮团成员,公平公正,制定评分标准,严格按照标准评审;以身作则,认真研读算法理论和代码,输出文章,参与并撰写了这篇稿件。同时,也特别感谢你机智过人的脑瓜子同学的编辑排版工作。
正因为你们的奉献和付出,百度飞桨的使用体验得以完美,开源互助机制得以完善。
开源精神,永不停歇。

Tiny Tony

Kevin Pang

Super松

Agravity

✌ VividChloe
倪侃_eval()

七年期限

不再是pytorch那个少年

Yao

木兰佳

孙顺????

Mr.郑先生_????

你机智过人的脑瓜子