从零开始学Python学习笔记---之--pandas数据框(3)
在pandas数据框(2)我们使用pandas模块实现观测的筛选、变量的重命名、数据类型的变换、排序、重复观测的删除、和数据集的抽样,这期我们继续介绍pandas模块的其他新知识点。包括频数统计、缺失值处理、数据映射、数据汇总。
一、频数统计
我们以被调查用户的收入数据为例,来谈谈频数统计函数value_counts
#读数据 import pandas as pd income = pd.read_excel('income.xlsx') #数据前4行 print(income.head(4))
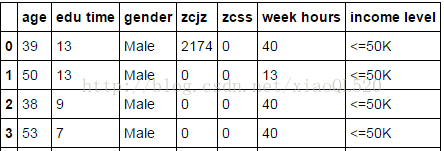
图片来源:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q
频数统计,顾名思义就是统计某个离散变量各水平的频次
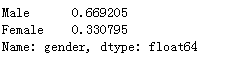
countedIncome =income.gender.value_counts() print(countedIncome)
这里统计的是性别男女的人数,是一个绝对值,如果想进一步查看男女的百分比例,可以通过下面的方式实现:
percentIncome = income.gender.value_counts()/sum(income.gender.value_counts()) print(percentIncome)
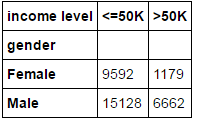
如上是单变量的频数统计,如果需要统计两个离散变量的交叉统计表,该如何实现?pandas模块提供了crosstab函数,我们来看看其用法:
result = pd.crosstab(index=income.gender,columns=income['income level']) print(result)
二、缺失值处理
在数据分析或建模过程中,我们希望数据集是干净的,没有缺失、异常之类,但面临的实际情况确实数据集很脏,例如对于缺失值我们该如何解决?一般情况,缺失值可以通过删除或替补的方式来处理。首先是要监控每个变量是否存在缺失,缺失的比例如何?这里我们借助于pandas模块中的isnull函数、dropna函数和fillna函数
#导入第三方模块库 import pandas as pd import numpy as np #手工编造一个含缺失值的数据框: df =pd.DataFrame([[1,2,3,4],[np.NaN,6,7,np.NaN],[11,np.NaN,12,13],[100,200,300,400],[20,40,60,np.NaN]], columns=['x1','x2','x3','x4']) print(df)

使用isnull函数检查数据集的缺失情况:
#总览数据集是否存才缺失 print(any(df.isnull),'\n') #每一列是否有缺失值,及缺失比例 is_null = [] null_ratio = [] for col in df.columns: is_null.append(any(pd.isnull(df[col]))) null_ratio.append(float(round(sum(pd.isnull(df[col]))/df.shape[0],2))) print(is_null,'\n',null_ratio,'\n') #每一行是否有缺失 is_null = [] for index in list(df.index): is_null.append(any(pd.isnull(df.iloc[index,:]))) print(is_null,'\n')

对缺失数据进行处理
删除法
dropna函数,有两种删除模式,一种是对含有缺失的行(任意一列)进行删除,另一种是删除那些全是缺失(所有列)的行,具体如下:
#对缺失数据进行处理 #删除法 #删除任何含有缺失的观测数据 print(df.dropna())
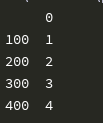
#删除每行中所有变量都为缺失值的观测 print(df.dropna(how='all'))
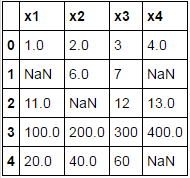
由于df数据集不存在行全为缺失的观测,故没有实现删除
替补法
fillna函数提供前向替补、后向替补和函数替补的几种方法,具体可参见下面的代码示例:
#前向替补 print(df.fillna(method='ffill'))

#后向替补 print(df.fillna(method='bfill'))

#不同的列用不同的函数替补 data =df.fillna(value={'x1':df.x1.mean(), 'x2':df.x2.median(), 'x4':df.x4.max()}) print(data)

三、数据映射
大家都知道,Python在做循环时,效率还是很低的,如何避开循环达到相同的效果呢?这就是接下来我们要研究的映射函数apply。该函数的目的就是将用户指定的函数运用到数据集的纵轴即各个变量或横轴即各个行。
例如以上面的统计数据集df各行和各列是否存在缺失为例,原先是这样的:
#总览数据集是否存才缺失 print(any(df.isnull()),'\n') #每一列是否有缺失值,及缺失比例 is_null = [] null_ratio = [] for col in df.columns: is_null.append(any(pd.isnull(df[col]))) null_ratio.append(float(round(sum(pd.isnull(df[col]))/df.shape[0],2))) print(is_null,'\n',null_ratio,'\n') #每一行是否有缺失 is_null = [] for index in list(df.index): is_null.append(any(pd.isnull(df.iloc[index,:]))) print(is_null,'\n')

现在通过映射函数可以这样简介而快速的实现:
#查看各列各行是否有缺失 #创建一个判断对象是否含缺失的匿名函数 isNull = lambda x :any(pd.isnull(x)) #使用apply映射函数 #axis=0表示将isNull函数映射到各列 data = df.apply(func=isNull,axis=0) print(data)

#axis=1表示将isNull函数映射到各行 data = df.apply(func=isNull,axis=1) print(data)

再如,需要计算每个学生的总成绩,或各科的平均分,也可以用apply函数实现:
#读取数据 score = pd.read_csv('test.csv') print(score.head(3))
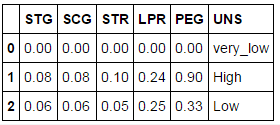
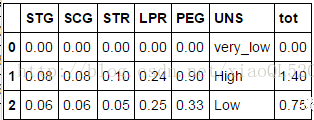
#读取数据 score = pd.read_csv('test.csv') print(score.head(3)) #每个学生的平均成绩 score['tot'] =score.iloc[:,0:5].apply(func = np.sum,axis =1)
图片来源:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q
#每门学科的平均分数 score.iloc[:,0:5].apply(func = np.mean,axis =0)

四、数据汇总
如果你想要做类似SQL中的聚合操作,pandas也提供了实现该功能的函数,即groupby函数与aggregate函数的搭配使用,我们以上面的收入数据集为例作为演示:
print(income.head(2))

#对性别gender做分组统计 groupby_gender = income.groupby(['gender']) groupby_gender.aggregate(np.mean)

以上结果,默认会对所有数值型变量作性别的均值统计。
#对性别gender和收入水平两个变量做分组统计 grouped = income.groupby(['gender','income level']) grouped.aggregate(np.mean)

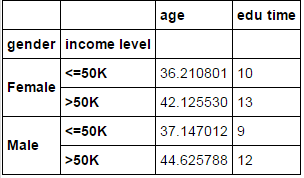
#对性别和收入水平两个变量做分组统计,但不同的变量做不同的聚合 grouped = income.groupby(['gender','income level']) #例如,对年龄算平均值,对教育时长算中位数 grouped.aggregate({'age':np.mean,'edu time':np.median})
学习地址:http://mp.weixin.qq.com/s/b8Lce66ViRuvxtAYM8e28Q