CNN及主要模型框架的技术演进
卷积神经网络的要点就是局部连接(Local Connection)、权值共享(Weight Sharing)和池化层(Pooling)中的降采样(Down-Sampling)。其中,局部连接和权值共享降低了参数量,使训练复杂度大大下降,并减轻了过拟合。同时权值共享还赋予了卷积网络对平移的容忍性,而池化层降采样则进一步降低了输出参数量,并赋予模型对轻度形变的容忍性,提高了模型的泛化能力。
卷积神经网络相比传统的机器学习算法,无须手工提取特征,也不需要使用诸如SIFT之类的特征提取算法,可以在训练中自动完成特征的提取和抽象,并同时进行模式分类,大大降低了应用图像识别的难度;相比一般的神经网络,CNN在结构上和图片的空间结构更为贴近,都是2D的有联系的结构,并且CNN的卷积连接方式和人的视觉神经处理光信号的方式类似。
LeNet5:
- 每个卷积层包含三个部分:卷积、池化和非线性激活函数
- 使用卷积提取空间特征
- 降采样(Subsample)的平均池化层(AveragePooling)
- 双曲正切(Tanh)或S型(Sigmoid)的激活函数 MLP作为最后的分类器 层与层之间的稀疏连接减少计算复杂度
它的输入图像为32×32的灰度值图像,后面有3个卷积层,1个全连接层和1个高斯连接层。
经典框架:ILSVRC的top-5错误率
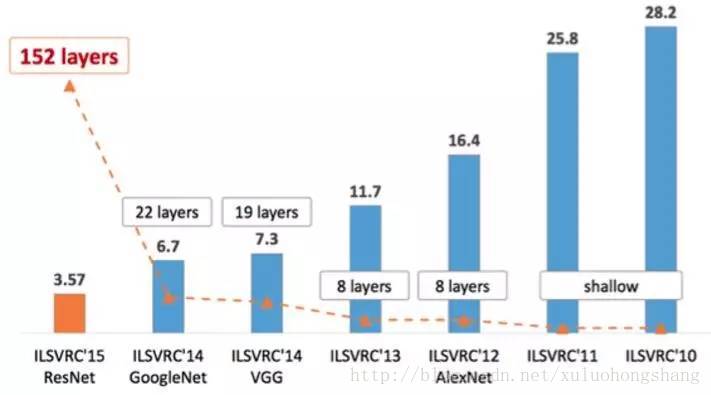
每年度的ILSVRC比赛数据集中大概拥有120万张图片,以及1000类的标注,是ImageNet全部数据的一个子集。比赛一般采用top-5和top-1分类错误率作为模型性能的评测指标。
AlexNet技术特点
首次在CNN中成功应用了ReLU、Dropout和LRN等Trick。AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:
- 成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
- 训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
- 在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
- 提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
- 数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了(256-224)2*2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。
- 整个AlexNet有8个需要训练参数的层(不包括池化层和LRN层),前5层为卷积层,后3层为全连接层。AlexNet最后一层是有1000类输出的Softmax层用作分类。LRN层出现在第1个及第2个卷积层后,而最大池化层出现在两个LRN层及最后一个卷积层后。
VGGNet技术特点
VGGNet是牛津大学计算机视觉组(Visual Geometry Group)和Google的DeepMind公司的研究员一起研发的的深度卷积神经网络。VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3*3的小型卷积核和2*2的最大池化层,VGGNet成功地构筑了16~19层深的卷积神经网络。VGGNet相比之前state-of-the-art的网络结构,错误率大幅下降,并取得了ILSVRC2014比赛分类项目的第2名和定位项目的第1名。
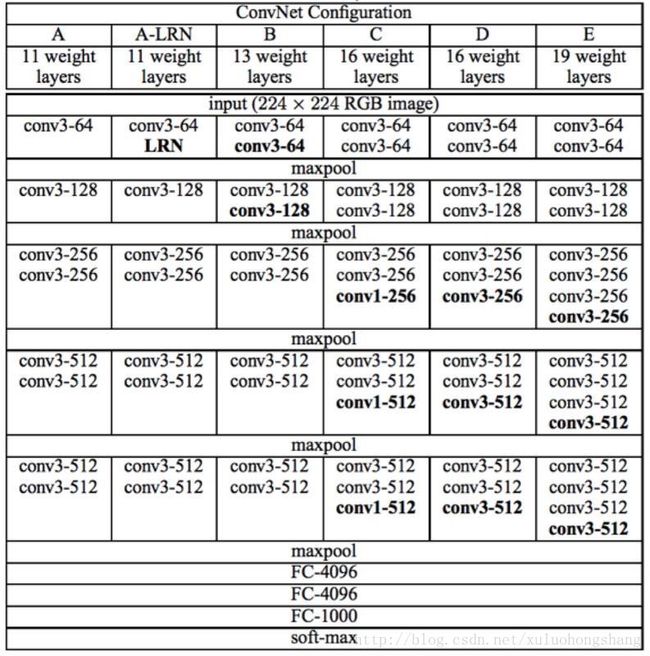
VGGNet论文中全部使用了3*3的卷积核和2*2的池化核,通过不断加深网络结构来提升性能。下图所示为VGGNet各级别的网络结构图,和每一级别的参数量,从11层的网络一直到19层的网络都有详尽的性能测试。
![]()
虽然从A到E每一级网络逐渐变深,但是网络的参数量并没有增长很多,这是因为参数量主要都消耗在最后3个全连接层。前面的卷积部分虽然很深,但是消耗的参数量不大,不过训练比较耗时的部分依然是卷积,因其计算量比较大。
VGGNet拥有5段卷积,每一段内有2~3个卷积层,同时每段尾部会连接一个最大池化层用来缩小图片尺寸。每段内的卷积核数量一样,越靠后的段的卷积核数量越多,其中经常出现多个完全一样的3*3的卷积层堆叠在一起的情况,这其实是非常有用的设计。
两个3*3的卷积层串联相当于1个5*5的卷积层,即一个像素会跟周围5*5的像素产生关联,可以说感受野大小为5*5。而3个3*3的卷积层串联的效果则相当于1个7*7的卷积层。除此之外,3个串联的3*3的卷积层,拥有比1个7*7的卷积层更少的参数量,只有后者的55%。
最重要的是,3个3*3的卷积层拥有比1个7*7的卷积层更多的非线性变换(前者可以使用三次ReLU激活函数,而后者只有一次),使得CNN对特征的学习能力更强。
作者在对比各级网络时总结出了以下几个观点。
- LRN层作用不大
- 越深的网络效果越好
- 1*1的卷积也是很有效的,但是没有3*3的卷积好,大一些的卷积核可以学习更大的空间特征。
GoogleNet(InceptionNet)技术特点
首次出现在ILSVRC2014的比赛中(和VGGNet同年),就以较大优势取得了第一名。那届比赛中的InceptionNet通常被称为InceptionV1,它最大的特点是控制了计算量和参数量的同时,获得了非常好的分类性能——top-5错误率6.67%,只有AlexNet的一半不到。
InceptionV1有22层深,比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率,可以说是非常优秀并且非常实用的模型。
InceptionV1降低参数量的目的有两点:第一,参数越多模型越庞大,需要供模型学习的数据量就越大,而目前高质量的数据非常昂贵;第二,参数越多,耗费的计算资源也会更大。
InceptionV1参数少但效果好的原因除了模型层数更深、表达能力更强外,还有两点:
一是去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。
二是InceptionV1中精心设计的Inception Module提高了参数的利用效率,其结构如下图所示。这一部分也借鉴了Network In Network的思想,形象的解释就是Inception Module本身如同大网络中的一个小网络,其结构可以反复堆叠在一起形成大网络。
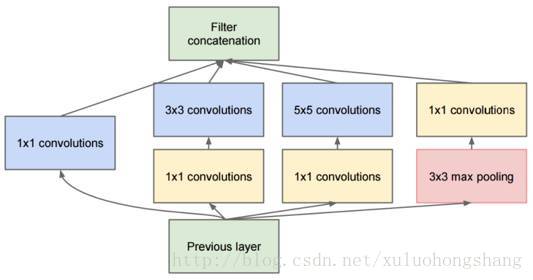
Inception Module的基本结构,其中有4个分支:
第一个分支对输入进行1*1的卷积,这其实也是NIN中提出的一个重要结构。1*1的卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。4个分支都用到了1*1卷积,来进行低成本(计算量比3*3小很多)的跨通道的特征变换。
第二个分支先使用了1*1卷积,然后连接3*3卷积,相当于进行了两次特征变换。第三个分支类似,先是1*1的卷积,然后连接5*5卷积。最后一个分支则是3*3最大池化后直接使用1*1卷积。
4个分支在最后通过一个聚合操作合并(在输出通道数这个维度上聚合)。
同时,Google Inception Net还是一个大家族,包括:
- 2014年9月的论文Going Deeper with Convolutions提出的Inception V1(top-5错误率6.67%)。
- 2015年2月的论文Batch Normalization:Accelerating Deep Network Training by Reducing Internal Covariate提出的InceptionV2(top-5错误率4.8%)。
- 2015年12月的论文Rethinking the Inception Architecture for Computer Vision提出的Inception V3(top-5错误率3.5%)。
- 2016年2月的论文Inception-v4,Inception-ResNet and the Impact of Residual Connections on Learning提出的InceptionV4(top-5错误率3.08%)。
InceptionV2学习了VGGNet,用两个3*3的卷积代替5*5的大卷积(用以降低参数量并减轻过拟合),还提出了著名的Batch Normalization(以下简称BN)方法。BN是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化(normalization)处理,使输出规范化到N(0,1)的正态分布,减少了Internal Covariate Shift(内部神经元分布的改变)。
BN的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍,达到之前的准确率所需要的迭代次数只有1/14,训练时间大大缩短。而达到之前的准确率后,可以继续训练,并最终取得远超于InceptionV1模型的性能——top-5错误率4.8%,已经优于人眼水平。因为BN某种意义上还起到了正则化的作用,所以可以减少或者取消Dropout,简化网络结构。
ResNet技术特点
ResNet(Residual Neural Network)由微软研究院的Kaiming He等4名华人提出,通过使用Residual Unit成功训练152层深的神经网络,在ILSVRC2015比赛中获得了冠军,取得3.57%的top-5错误率,同时参数量却比VGGNet低,效果非常突出。
ResNet的结构可以极快地加速超深神经网络的训练,模型的准确率也有非常大的提升。
ResNet最初的灵感出自这个问题:在不断加神经网络的深度时,会出现一个Degradation的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是ResNet的灵感来源。假定某段神经网络的输入是x,期望输出是H(x),如果我们直接把输入x传到输出作为初始结果,那么此时我们需要学习的目标就是F(x)=H(x)-x。
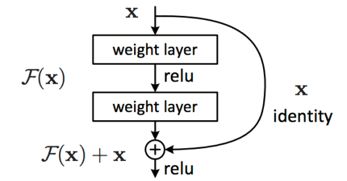
这就是一个ResNet的残差学习单元(Residual Unit),ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别H(x)-x,即残差。

上图所示为VGGNet-19,以及一个34层深的普通卷积网络,和34层深的ResNet网络的对比图。可以看到普通直连的卷积神经网络和ResNet的最大区别在于,ResNet有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这种结构也被称为shortcut或skip connections。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
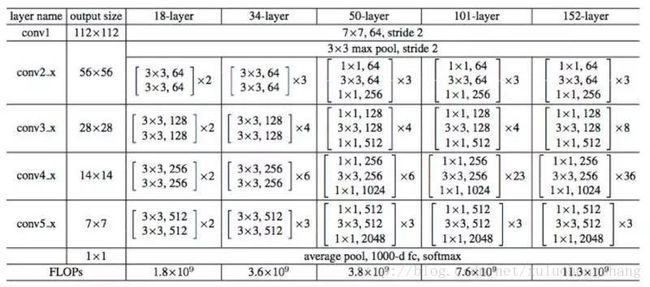
上图所示为ResNet在不同层数时的网络配置,其中基础结构很类似,都是前面提到的两层和三层的残差学习单元的堆叠。在使用了ResNet的结构后,可以发现层数不断加深导致的训练集上误差增大的现象被消除了,ResNet网络的训练误差会随着层数增大而逐渐减小,并且在测试集上的表现也会变好。
总结发展路线:
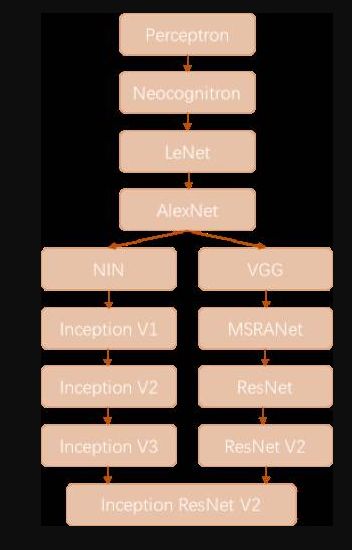
历史性事件:
1957年由Frank Resenblatt提出Perceptron(感知机),而Perceptron不仅是卷积网络,也是神经网络的始祖。Neocognitron(神经认知机)是一种多层级的神经网络,由日本科学家Kunihiko Fukushima于20世纪80年代提出,具有一定程度的视觉认知的功能,并直接启发了后来的卷积神经网络。
LeNet-5由CNN之父YannLeCun于1997年提出,首次提出了多层级联的卷积结构,可对手写数字进行有效识别。可以看到前面这三次关于卷积神经网络的技术突破,间隔时间非常长,需要十余年甚至更久才出现一次理论创新。
而后于2012年,Hinton的学生Alex依靠8层深的卷积神经网络一举获得了ILSVRC?2012比赛的冠军,瞬间点燃了卷积神经网络研究的热潮。AlexNet成功应用了ReLU激活函数、Dropout、最大覆盖池化、LRN层、GPU加速等新技术,并启发了后续更多的技术创新,卷积神经网络的研究从此进入快车道。
在AlexNet之后,我们可以将卷积神经网络的发展分为两类,一类是网络结构上的改进调整(图6-18中的左侧分支),另一类是网络深度的增加(图18中的右侧分支)。
2013年,颜水成教授的Network in Network工作首次发表,优化了卷积神经网络的结构,并推广了1*1的卷积结构。在改进卷积网络结构的工作中,后继者还有2014年的Google Inception Net V1,提出了Inception Module这个可以反复堆叠的高效的卷积网络结构,并获得了当年ILSVRC比赛的冠军。
2015年初的Inception V2提出了Batch Normalization,大大加速了训练过程,并提升了网络性能。2015年年末的Inception V3则继续优化了网络结构,提出了Factorization in Small Convolutions的思想,分解大尺寸卷积为多个小卷积乃至一维卷积。
2015年,微软的ResNet成功训练了152层深的网络,一举拿下了当年ILSVRC比赛的冠军,top-5错误率降低至3.46%。
其他………
我们可以看到,自AlexNet于2012年提出后,深度学习领域的研究发展极其迅速,基本上每年甚至每几个月都会出现新一代的技术。新的技术往往伴随着新的网络结构,更深的网络的训练方法等,并在图像识别等领域不断创造新的准确率记录。