Hadoop+zookeeper+yarn的高可用部署
下载获取zookeeper文件,解压缩

拷贝并修改配置文件
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg

关闭服务并清空/tmp/的内容
sbin/stop-dfs.sh
sbin/stop-yarn.sh
rm /tmp/* -fr
在server2和server3和server4这三个结点上创建目录并写入myid
mkdir /tmp/zookeeper
echo 1 > /tmp/zookeeper/myid (server2)
echo 2 > /tmp/zookeeper/myid (server3)
echo 3 > /tmp/zookeeper/myid (server4)

在server2和server3和server4这三个结点上启动zookeeper
/home/hadoop/zookeeper-3.4.9/bin/zkServer.sh start

查看状态,2,4为从节点,3为主节点
/home/hadoop/zookeeper-3.4.9/bin/zkServer.sh status
server2从

server3主

server4从

登录查看信息
bin/zkCli.sh -server 127.0.0.1:2181

编辑文件添加集群信息
cd /home/hadoop/hadoop/etc/hadoop/
vim core-site.xml
编辑文件core-site.xml内容
fs.defaultFS
hdfs://masters
ha.zookeeper.quorum
172.25.33.2:2181,172.25.33.3:2181,172.25.33.4:2181
编辑文件hdfs-site.xml
vim hdfs-site.xml
文件内容如下
dfs.replication
3
dfs.nameservices
masters
dfs.ha.namenodes.masters
h1,h2
dfs.namenode.rpc-address.masters.h1
172.25.33.1:9000
dfs.namenode.http-address.masters.h1
172.25.33.1:9870
dfs.namenode.rpc-address.masters.h2
172.25.33.5:9000
dfs.namenode.http-address.masters.h2
172.25.33.5:9870
dfs.namenode.shared.edits.dir
qjournal://172.25.33.2:8485;172.25.33.3:8485;172.25.33.4:8485/masters
dfs.journalnode.edits.dir
/tmp/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.masters
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
按顺序启动hdfs集群server2/server3/server4
/home/hadoop/hadoop/bin/hdfs --daemon start journalnode
拷贝主机server1的/tmp下的信息到server5
scp -r /tmp/hadoop-hadoop 172.25.33.5:/tmp
在server1上格式化zookeeper
bin/hdfs zkfc -formatZK ##当格式化显示的信息都为info没有error的时候证明格式化没有问题
启动hdfs集群
[hadoop@server1 hadoop]$ sbin/start-dfs.sh ##在启动服务的时候必须保证其它节点没有datanode进行存在,保证实验环境的纯净
//启动之后分别在server1及server5上查看:
注意在查看时可能出现第一次只出现失败回切域,或者只出现namenode的节点的情况,只需要关掉服务再次启动即可,且server1和server5因为是namnode节点内存需要2G
此时查看namenode节点状态


查看journalnode的节点状态均相同

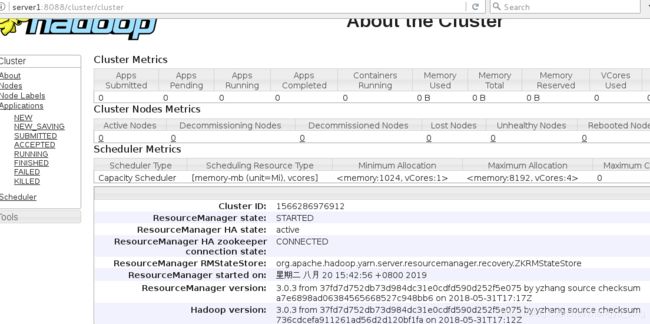
网页查看此时的状态
server1为主
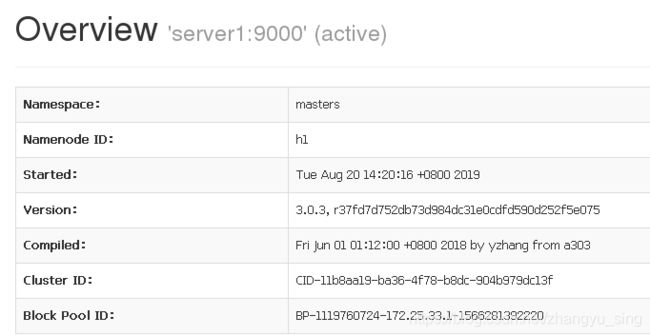
server5为备
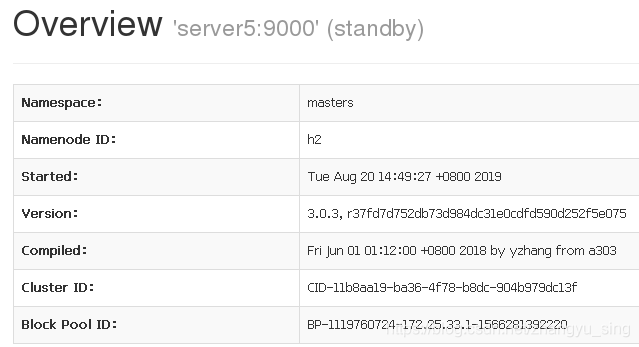
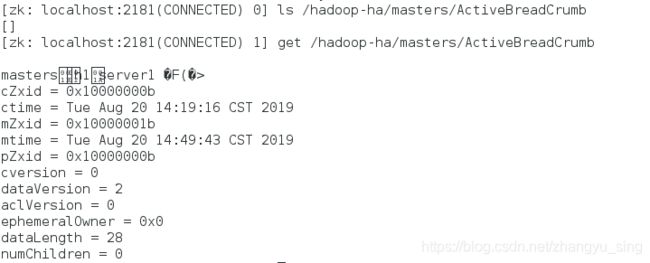
查看信息
/home/hadoop/zookeeper-3.4.9/bin/zkCli.sh
ls /hadoop-ha/masters/ActiveBreadCrumb
get /hadoop-ha/masters/ActiveBreadCrumb
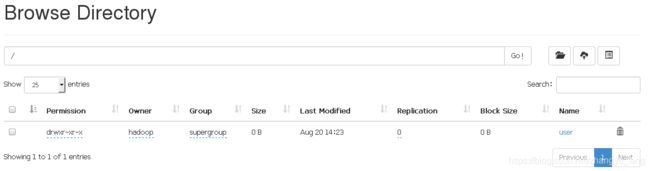
在server1上尝试写入数据
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop
bin/hdfs dfs -ls
bin/hdfs dfs -put etc/hadoop/ input
网页查看

此时尝试杀死主机server1的nodename节点,发现server5变为主机节点,访问正常
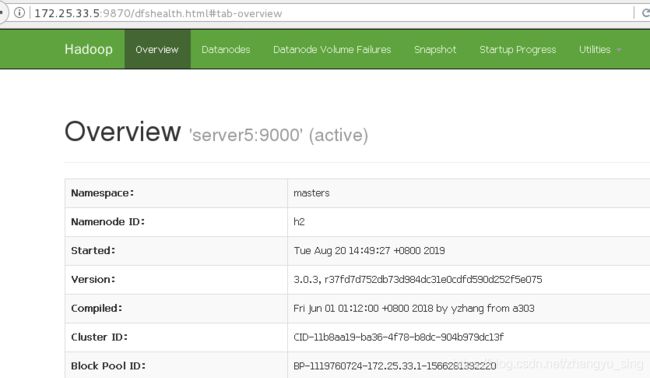
访问结果
配置yarn的高可用
修改配置文件etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
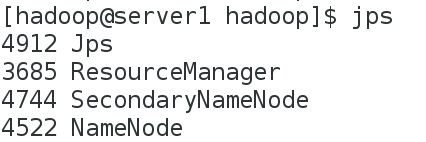
启动服务测试后关闭
sbin/start-yarn.sh
查看结果
jps
修改文件etc/hadoop/yarn-site.xml内容如下
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
RM_CLUSTER
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
172.25.33.1
yarn.resourcemanager.hostname.rm2
172.25.33.5
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
yarn.resourcemanager.zk-address
172.25.33.2:2181,172.25.33.3:2181,172.25.33.4:2181
在主机sever1启动yarn服务,作为rm1
cd /home/hadoop/hadoop
sbin/start-yarn.sh

手动放开server5的yarn服务,作为rm2
sbin/yarn-daemon.sh start resourcemanager

查看结果

在zookeeper节点进行查看
sbin/yarn-daemon.sh start resourcemanager

可以把 RM 与 NN 分离运行,这样可以更好的保证程序的运行性能。
网页查看此时状态

此时尝试关闭server5节点的rm,发现服务转移至server1

kill -9 9339