使用Sqoop导出Mysql数据到Hive(实战案例)
教程目录
- 0x00 教程内容
- 0x01 SQL文件准备
- 1. 准备sql脚本
- 2. 执行sql脚本
- 0x02 导出Mysql数据到Hive
- 1. 导出数据到HDFS
- 2. 构建Hive表关联HDFS(movie表)
- 3. 构建Hive表关联HDFS(user_rating表)
- 3.1 模拟增量添加数据操作
- 4. 构建Hive表关联HDFS(users表)
- 4.1 模拟修改与增量数据操作
- 0xFF 总结
0x00 教程内容
- SQL文件准备
- 导出Mysql数据到Hive
前提:
- 安装好了Hive
- 安装好了Sqoop
0x01 SQL文件准备
1. 准备sql脚本
a. 准备建表与添加数据sql文件
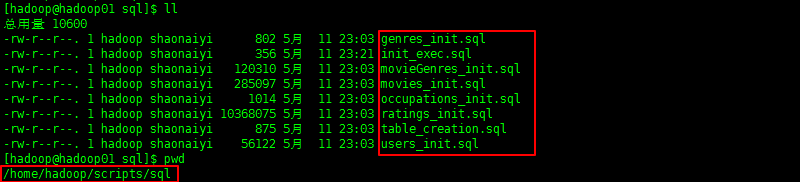
2. 执行sql脚本
source /home/hadoop/scripts/sql/init_exec.sql
PS:文件多的话,可能执行起来会有点慢。
0x02 导出Mysql数据到Hive
1. 导出数据到HDFS
a. 将Mysql中带有电影种类信息的电影数据导入到HDFS中
sqoop import --connect jdbc:mysql://hadoop01:3306/movie \
--username root --password root \
--query 'SELECT movie.*, group_concat(genre.name) FROM movie
JOIN movie_genre ON (movie.id = movie_genre.movie_id)
JOIN genre ON (movie_genre.genre_id = genre.id)
WHERE $CONDITIONS
GROUP BY movie.id' \
--split-by movie.id \
--fields-terminated-by "\t" \
--target-dir /user/hadoop/movielens/movie \
--delete-target-dir
执行后,/user/hadoop/movielens/movie目录下就有数据了。
hadoop fs -ls /user/hadoop/movielens/movie

2. 构建Hive表关联HDFS(movie表)
a. 创建一个movielens数据库:
CREATE DATABASE IF NOT EXISTS movielens;
b. 创建一张临时存放数据的表:
CREATE EXTERNAL TABLE IF NOT EXISTS movielens.movie_temp(
id INT,
title STRING,
release_date STRING,
video_release_date STRING,
imdb_url STRING,
genres ARRAY
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ','
LOCATION '/user/hadoop/movielens/movie';
建完表,movie_temp表就已经有数据了!
select count(*) from movie_temp;

c. 创建一张真实存放数据的表(将临时表的数据导入到这里来)
CREATE EXTERNAL TABLE IF NOT EXISTS movielens.movie(
id INT,
title STRING,
release_date STRING,
video_release_date STRING,
imdb_url STRING,
genres ARRAY)
STORED AS PARQUET;
d. 将临时表的数据导入到这里来
INSERT OVERWRITE TABLE movielens.movie SELECT * FROM movielens.movie_temp;
查看movie表有没有数据:
select count(*) from movie;

e. 最后删除临时表
DROP TABLE movielens.movie_temp;
3. 构建Hive表关联HDFS(user_rating表)
a. 启动Sqoop的metastore服务:
sqoop metastore &
b. 创建一个sqoop job
前提:创建之前确保作业已删除,否则请先删除:
sqoop job --delete user_rating_import --meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop
## 增量的将user_rating的数据从mysql中导入到hdfs中
sqoop job --create user_rating_import \
--meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop \
-- import --connect jdbc:mysql://hadoop01:3306/movie \
--username root --password root \
--table user_rating -m 5 --split-by dt_time \
--incremental append --check-column dt_time \
--fields-terminated-by "\t" \
--target-dir /user/hadoop/movielens/user_rating_stage
报错:
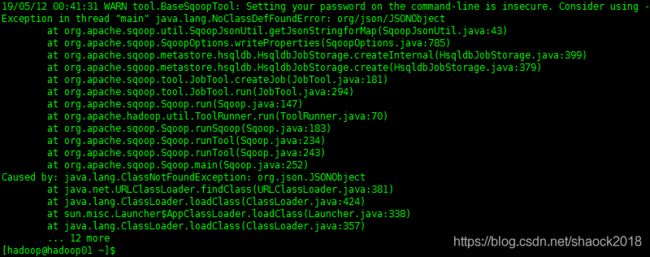
解决:
拷贝java-json.jar包放于$SQOOP_HOME/lib路径下:

c. 执行user_rating_import任务
前提:确保路径下没内容,如果有要先删除。
hadoop fs -rm -r /user/hadoop/movielens/user_rating_stage
执行任务:
sqoop job --exec user_rating_import --meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop
输入Mysql的密码,即可开始同步数据。
查看数据:
hadoop fs -ls /user/hadoop/movielens/user_rating_stage

d. 创建一张临时存放数据的表:
DROP TABLE IF EXISTS user_rating_stage;
CREATE EXTERNAL TABLE user_rating_stage (
id INT,
user_id INT,
movie_id INT,
rating INT,
dt_time STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/user/hadoop/movielens/user_rating_stage';
select count(*) from user_rating_stage;

e. 创建一张以后会含有重复评分的user_rating表
CREATE EXTERNAL TABLE IF NOT EXISTS user_rating (
id INT,
user_id INT,
movie_id INT,
rating INT,
dt_time STRING
)
PARTITIONED BY (year INT, month INT, day INT)
STORED AS AVRO;
f. 挑选user_rating_stage的相应字段插入到user_rating表:
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT INTO TABLE user_rating PARTITION(year, month, day)
SELECT id, user_id, movie_id, rating, dt_time, year(dt_time) as year, month(dt_time) as month, day(dt_time) as day
FROM user_rating_stage;
查看一下是否有数据:
select count(*) from user_rating;

g. 创建评分事实表(没有重复数据的)
CREATE EXTERNAL TABLE IF NOT EXISTS user_rating_fact (
id INT,
user_id INT,
movie_id INT,
rating INT,
dt_time STRING
)
PARTITIONED BY (year INT, month INT, day INT)
STORED AS PARQUET;
将user_rating表进行去重操作:
WITH t1 as (
SELECT
id,
user_id,
movie_id,
rating,
dt_time,
year,
month,
day,
ROW_NUMBER() OVER (PARTITION BY user_id, movie_id ORDER BY dt_time DESC) as rn
FROM user_rating
)
INSERT OVERWRITE TABLE user_rating_fact PARTITION(year, month, day)
SELECT id, user_id, movie_id, rating, dt_time, year, month, day FROM t1 WHERE rn = 1;
查看数据,因为表数据没改变,所以都是10w条:
select count(*) from user_rating_fact;

3.1 模拟增量添加数据操作
a. 打开一个终端进入Mysql,插入数据:
insert into user_rating values(0, 196, 242, 5, STR_TO_DATE("1970-01-12 12:47:30", "%Y-%m-%d %T"));
insert into user_rating values(1, 186, 302, 4, STR_TO_DATE("1970-01-12 15:41:57", "%Y-%m-%d %T"));
insert into user_rating values(2, 22, 377, 3, STR_TO_DATE("1970-01-12 12:08:07", "%Y-%m-%d %T"));
insert into user_rating values(3, 244, 51, 1, STR_TO_DATE("1970-01-12 12:36:46", "%Y-%m-%d %T"));
insert into user_rating values(4, 166, 346, 1, STR_TO_DATE("1970-01-12 14:13:17", "%Y-%m-%d %T"));
insert into user_rating values(5, 298, 474, 4, STR_TO_DATE("1970-01-12 13:36:22", "%Y-%m-%d %T"));
insert into user_rating values(6, 115, 265, 2, STR_TO_DATE("1970-01-12 12:46:11", "%Y-%m-%d %T"));
insert into user_rating values(7, 253, 465, 5, STR_TO_DATE("1970-01-12 15:40:28", "%Y-%m-%d %T"));
insert into user_rating values(8, 305, 451, 3, STR_TO_DATE("1970-01-12 14:12:04", "%Y-%m-%d %T"));
b. 重新执行user_rating_import任务
要先删除user_rating_stage路径下的内容:
hadoop fs -rm -r /user/hadoop/movielens/user_rating_stage
重新执行任务:
sqoop job --exec user_rating_import --meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop
输入Mysql的密码,即可开始同步数据。
查看数据:
hadoop fs -cat /user/hadoop/movielens/user_rating_stage/*
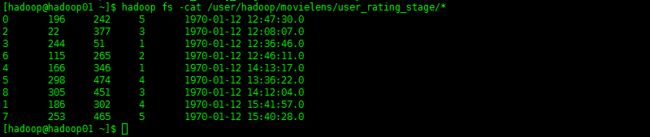
只有我们插入的那几条数据!
c. 将新增的数据插入到评分记录表中:
INSERT INTO TABLE user_rating PARTITION(year, month, day)
SELECT id, user_id, movie_id, rating, dt_time, year(dt_time) as year, month(dt_time) as month, day(dt_time) as day
FROM user_rating_stage;
此时评分记录表含有100000+9=1000009条记录
select count(*) from user_rating;

d. 评分记录表重新操作可以得到评分的实时表:
操作之前看一下我们Mysql的记录,其实我们是已经插入了另外一条了,等一下我们要进行去重操作,最后才会得到我们的评分事实表(user_rating_fact):

e. 去重操作:
WITH t1 as (
SELECT
id,
user_id,
movie_id,
rating,
dt_time,
year,
month,
day,
ROW_NUMBER() OVER (PARTITION BY user_id, movie_id ORDER BY dt_time DESC) as rn
FROM user_rating
)
INSERT OVERWRITE TABLE user_rating_fact PARTITION(year, month, day)
SELECT id, user_id, movie_id, rating, dt_time, year, month, day FROM t1 WHERE rn = 1;
select count(*) from user_rating_fact;
select * from user_rating_fact where id = 1;
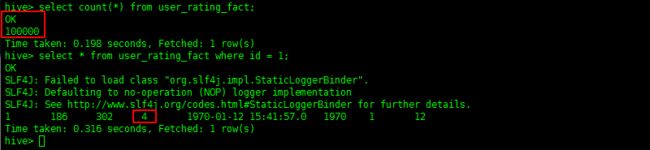
发现,我们id为1的这条记录的评分,是拿了最新的那个时间的,即评分为4的。
4. 构建Hive表关联HDFS(users表)
a. 前提已启动Sqoop的metastore服务,否则:
sqoop metastore &
b. 创建一个sqoop job
前提:创建之前确保作业已删除,否则请先删除:
sqoop job --delete user_import --meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop
sqoop job --create user_import \
--meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop \
-- import --connect jdbc:mysql://hadoop01:3306/movie \
--username root --password root \
-m 5 --split-by last_modified \
--incremental lastmodified --check-column last_modified \
--query 'SELECT user.id, user.gender, user.zip_code, user.age, occupation.occupation, user.last_modified
FROM user JOIN occupation ON user.occupation_id = occupation.id WHERE $CONDITIONS' \
--fields-terminated-by "\t" \
--target-dir /user/hadoop/movielens/user_stage
c. 执行user_import任务
前提:确保路径下没内容,如果有要先删除。
hadoop fs -rm -r /user/hadoop/movielens/user_stage
执行任务:
sqoop job --exec user_import --meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop
输入Mysql的密码,即可开始同步数据。
查看数据:
hadoop fs -ls /user/hadoop/movielens/user_stage

d. 创建一张临时用户表user_stage:
DROP TABLE IF EXISTS user_stage;
CREATE EXTERNAL TABLE user_stage (
id INT,
gender STRING,
zip_code STRING,
age INT,
occupation STRING,
last_modified STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION '/user/hadoop/movielens/user_stage';
e. 创建用户历史表user_rating_history:
CREATE EXTERNAL TABLE IF NOT EXISTS user_history (
id INT,
gender STRING,
zip_code STRING,
age INT,
occupation STRING,
last_modified STRING
)
PARTITIONED BY (year INT, month INT, day INT)
STORED AS AVRO;
f. 将临时表的数据先插入到user_history表:
INSERT INTO TABLE user_history PARTITION(year, month, day)
SELECT *, year(last_modified) as year, month(last_modified) as month, day(last_modified) as day FROM user_stage;
执行完,我们的user_history表的数据就是Mysql未改变前的数据。
g. 创建一张用户表users(不要用user,因为可能会跟内置的用户冲突):
CREATE EXTERNAL TABLE IF NOT EXISTS users (
id INT,
gender STRING,
zip_code STRING,
age INT,
occupation STRING,
last_modified STRING
)
STORED AS PARQUET;
合并修改更新后的user(左连接:排除users表中修改过的数据,等下直接拿user_stage倒进来就可以了)
INSERT OVERWRITE TABLE users
SELECT users.id, users.gender, users.zip_code, users.age, users.occupation, users.last_modified
FROM users LEFT JOIN user_stage ON users.id = user_stage.id WHERE user_stage.id IS NULL;
INSERT INTO TABLE users SELECT id, gender, zip_code, age, occupation, last_modified FROM user_stage;
第一次没有修改,也没有添加,所以users表数据与user_stage一样。
4.1 模拟修改与增量数据操作
a. 更新Mysql的数据:
update user set gender='F', last_modified=now() where id=1;
insert into user values(944, 'F', "345642", 20, 19, now());
b. 同步Mysql数据到HDFS:
hadoop fs -rm -r /user/hadoop/movielens/user_stage
sqoop job --exec user_import --meta-connect jdbc:hsqldb:hsql://hadoop01:16000/sqoop
输入Mysql的密码即可同步!
hadoop fs -cat /user/hadoop/movielens/user_stage/*

c. 插入数据到user_history:
INSERT INTO TABLE user_history PARTITION(year, month, day) SELECT *, year(last_modified) as year, month(last_modified) as month, day(last_modified) as day FROM user_stage;
d. 合并修改更新后的user
INSERT OVERWRITE TABLE users
SELECT users.id, users.gender, users.zip_code, users.age, users.occupation, users.last_modified
FROM users LEFT JOIN user_stage ON users.id = user_stage.id WHERE user_stage.id IS NULL;

原本943条条记录,进过上面命令,排除了1条修改过的记录,还有943-1=942条。
e. 插入临时表里面的数据:
INSERT INTO TABLE users SELECT id, gender, zip_code, age, occupation, last_modified FROM user_stage;

942+2=944条记录。
0xFF 总结
- 过程繁琐,写教程难度大,写了好几个钟,辛苦了。
- 本教程的特色是加上我们的增量、已经修改增量,比较贴切企业开发每天的数据。
作者简介:邵奈一
大学大数据讲师、大学市场洞察者、专栏编辑
公众号、微博、CSDN:邵奈一
本系列课均为本人:邵奈一原创,如转载请标明出处
福利:
邵奈一的技术博客导航