数据仓库-hive分区表
什么是分区
在逻辑上分区表与未分区表没有区别,在物理上分区表会将数据按照分区键的列值存储在表目录的子目录中,目录名=“分区键=键值”。其中需要注意的是分区键的值不一定要基于表的某一列(字段),它可以指定任意值,只要查询的时候指定相应的分区键来查询即可。我们可以对分区进行添加、删除、重命名、清空等操作。因为分区在特定的区域(子目录)下检索数据,它作用同DNMS分区一样,都是为了减少扫描成本。
Hive(Inceptor)分区又分为单值分区、范围分区。单值分区又分为静态分区和动态分区。我们先看下分区长啥样。如下,假如有一张表名为persionrank表,记录每个人的评级,有id、name、score字段。我们便可以创建分区rank(注意rank不是表中的列,我们可以把它当做虚拟列),并将相应数据导入指定分区(将数据插入指定目录)。

分区的好处
分区的种类
1、静态分区
单分区
create table t1(
id int
,name string
,hobby array
,add map
)
partitioned by (pt_d string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
; 注:这里分区字段不能和表中的字段重复。
如果分区字段和表中字段相同的话,会报错,如下:
create table t1(
id int
,name string
,hobby array
,add map
)
partitioned by (id int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;
报错信息:FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns
装载数据
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin执行load data
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1 partition ( pt_d = '201701');
查看数据 select * from t1;
1 xiaoming ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 201701
2 lilei ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 201701
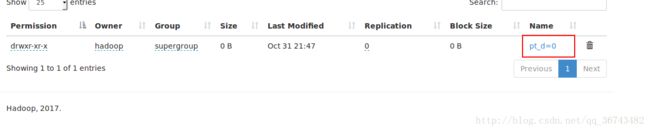
3 lihua ["music","book"] {"heilongjiang":"haerbin"} 201701给t1添加分区
alter table t1 add partition (pt_d ='00000');重新加载一份新的数据
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1 partition ( pt_d = '000000');查看数据:select * from t1;
1 xiaoming ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 000000
2 lilei ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 000000
3 lihua ["music","book"] {"heilongjiang":"haerbin"} 000000
1 xiaoming ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 201701
2 lilei ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 201701
3 lihua ["music","book"] {"heilongjiang":"haerbin"} 201701

可以查询单个分区
select * from t1 where pt_d = ‘000000’多个分区
create table t10(
id int
,name string
,hobby array
,add map
)
partitioned by (pt_d string,sex string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
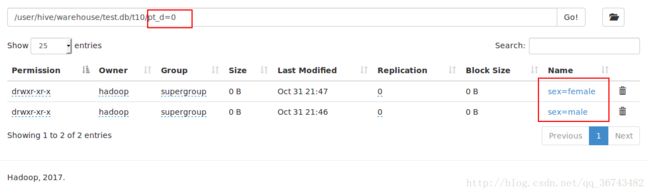
; 装载数据(分区字段必须都要加)
load data local inpath ‘/home/hadoop/Desktop/data’ overwrite into table t10 partition ( pt_d = ‘0’); 如果只是添加一个,会报错:FAILED: SemanticException [Error 10006]: Line 1:88 Partition not found ”0”
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t10 partition ( pt_d = '0',sex='male');
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t10 partition ( pt_d = '0',sex='female');观察HDFS上的文件,可发现多个分区具有顺序性,可以理解为windows的树状文件夹结构。
2、动态分区
如果用上述的静态分区,插入的时候必须首先要知道有什么分区类型,而且每个分区写一个load data,太烦人。使用动态分区可解决以上问题,其可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统自己选择。
首先启动分区功能
hive> set hive.exec.dynamic.partition=true;假设已有一张表par_tab,前两列是名称name和国籍nation,后两列是分区列,性别sex和日期dt,数据如下:
create table par_dam(
name string,
nation string,
)partitioned by (sex string,date string)
并加载数据
select * from par_tab;
OK
lily china man 2013-03-28
nancy china man 2013-03-28
hanmeimei america man 2013-03-28
jan china man 2013-03-29
mary america man 2013-03-29
lilei china man 2013-03-29
heyong china man 2013-03-29
yiku japan man 2013-03-29
emoji japan man 2013-03-29
Time taken: 1.141 seconds, Fetched: 9 row(s)现在我把这张表的内容直接插入到另一张表par_dnm中,并实现sex为静态分区,dt动态分区(不指定到底是哪日,让系统自己分配决定)
create table par_dam(
name string,
nation string,
)partitioned by (sex string,date string)
insert overwrite table par_dnm partition(sex='man',dt)
select name, nation, dt from par_tab;插入后看下目录结构
drwxr-xr-x - hadoop supergroup 0 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man
drwxr-xr-x - hadoop supergroup 0 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-28
-rwxr-xr-x 1 hadoop supergroup 41 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-28/000000_0
drwxr-xr-x - hadoop supergroup 0 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-29
-rwxr-xr-x 1 hadoop supergroup 71 2017-03-29 10:32 /user/hive/warehouse/par_dnm/sex=man/dt=2013-03-29/000000_0![]()
再查看分区数
show partitions par_dnm;
OK
sex=man/dt=2013-03-28
sex=man/dt=2013-03-29
Time taken: 0.065 seconds, Fetched: 2 row(s)
证明动态分区成功。
动态分区不允许主分区采用动态列而副分区采用静态列,这样将导致所有的主分区都要创建副分区静态列所定义的分区。
动态分区可以允许所有的分区列都是动态分区列,但是要首先设置一个参数hive.exec.dynamic.partition.mode :
set hive.exec.dynamic.partition.mode;它的默认值是strick,即不允许分区列全部是动态的,这是为了防止用户有可能原意是只在子分区内进行动态建分区,但是由于疏忽忘记为主分区列指定值了,这将导致一个dml语句在短时间内创建大量的新的分区(对应大量新的文件夹),对系统性能带来影响。所以我们要设置:
set hive.exec.dynamic.partition.mode=nostrick;![]() 现在我把这张表的内容直接插入到另一张表par_dnm中,并实现sex为静态分区,dt动态分区(不指定到底是哪日,让系统自己分配决定)
现在我把这张表的内容直接插入到另一张表par_dnm中,并实现sex为静态分区,dt动态分区(不指定到底是哪日,让系统自己分配决定)
insert overwrite table par_dnm partition(sex,dt)
select name,nation,sex,dt from par_tab;
表分区的增删修查
1、增加分区
一次增加一个分区
alter table testljb add partition (age=2);![]()
![]()
![]()
一次增加多个分区
alter table testljb add partition(age=3) partition(age=4);![]()
![]()
![]()
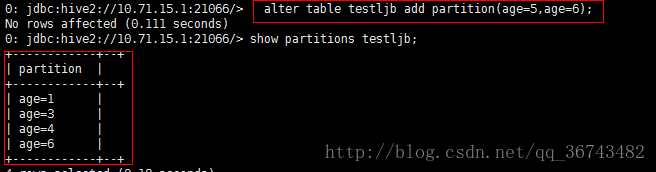
注意:一定不能写成如下方式:
alter table testljb add partition(age=5,age=6);![]()
![]()
![]()
如果我们show partitions table_name 会发现仅仅添加了age=6的分区。
![]()
![]()
![]()
有个表具有两个分区字段:age分区和sex分区。那么我们添加一个age分区为1,sex分区为male的数据,可以这样添加:
alter table testljb add partition(age=1,sex='male');![]()
![]()
![]()
2、删除分区
删除分区age=1
alter table testljb drop partition(age=1);![]()
![]()
![]()
3、修复分区
修复分区就是重新同步hdfs上的分区信息。
msck repair table table_name;
![]()
![]()
![]()
4、查询分区
show partitions table_name;![]()
![]()
![]()