http与中文编码传输
关于http的RFC文档:http://www.w3.org/Protocols/rfc2616/rfc2616.html
关于http与中文传输的问题,如果不解决,在实际的网络抓取的过程中会产生很多的次生的问题。理解中文传输的编码过程因而尤为重要。
中文的传输过程具体可能是:内存中unicode -> 编码阶段gbk, gb18030, utf8 -> 到urlencode ->最后到可能的base64编码。那到底是什么机制在负责这个转换的过程呢?转换使用的是什么通道呢?
UrlEncode:将字符串以URL编码 。 返回值:字符串。 函数种类:编码处理。比如在谷歌搜索“中国人”的时候,得到的URL如下所示:http://www.google.com.hk/search?q=%D6%D0%B9%FA%C8%CB&client=aff-360daohang&hl=zh-CN&ie=gb2312&newwindow=1,其中%D6%D0%B9%FA%C8%CB部分就是urlencode。那么这个编码的处理方式是怎么样的呢?有没有什么处理工具?
个人尝试的方法就是:
无论如何都把urlencode转化成Utf-8的格式进行数据传输。例如下例:id=java.net.URLEncoder.encode(id, "utf-8");
然后再接受就可以了。urlencoder时必须合并使用的方法。
id=java.net.URLEncoder.encode(id, "utf-8");response.sendRedirect("personalPage.jsp?user="+id);
尝试成功之后,还有一种情况没有考虑到,那就是gb2312编码格式下中文字符的直接传输。能否不经过utf-8的编码来搞定参数的传递?
附一些自己找到的资料:
主要用于将字符串以URL编码,返回一个字符串。
使用方法:
1、ASP中的用法:Server.URLEncode(“内容”) 例如:
<% response.write Server.UrlEncode("工具网") %>
2、PHP中的用法:urlencode(“内容”) 例如:
3、JSP中的用法:URLEncoder.encode(“内容”) 例如:
<% java.net.URLEncoder.encode("工具网"); %>
个人亲自尝试的中文传输方法,即只需编码,另一端无需解码:
<%
id=java.net.URLEncoder.encode(id, "UTF-8");
response.sendRedirect("/index.jsp?error="+id);
%>
4、javascript中的用法:encodeURI(“内容”) 例如:
encodeURI("工具网");
5、Python中的用法:
import urllib2
urllib2.quote("工具网")
主要对字符串进行URL解码,返回已解码的字符串
1、ASP中的用法:Server.UrlDecode(“内容”) 例如:
<% response.write Server.UrlDecode("%E5%B7%A5%E5%85%B7%E7%BD%91") %>
2、PHP中的用法:urldecode(“内容”) 例如:
3、JSP中的用法:URLDecoder.decode(“内容”) 例如:
<% java.net.URLDecoder.decode("%E5%B7%A5%E5%85%B7%E7%BD%91"); %>
4、javascript中的用法 例如:
decodeURI("%E5%B7%A5%E5%85%B7%E7%BD%91");
5、Python中的用法 例如:
import urllib2
urllib2.unquote("%E5%B7%A5%E5%85%B7%E7%BD%91")
Unicode 与 Utf-8码间的内码规则模板为:
原始码(16进制) UTF-8编码(二进制)
--------------------------------------------
0000 - 007F 0xxxxxxx
0080 - 07FF 110xxxxx 10xxxxxx
0800 - FFFF 1110xxxx 10xxxxxx 10xxxxxx (中文字在此区间)
……
--------------------------------------------
例如:
百度中查询“中国人”,会将中文URL参数转为Gb2312码的16进制表示,一个中文字用2个字节
http://www.baidu.com/s?wd=%D6%D0%B9%FA%C8%CB
Google中查询“中国人”,会将中文URL参数转为Utf-8编码的16进制表示,一个中文字用3个字节
http://www.google.cn/search?client=opera&rls=en&q=%E4%B8%AD%E5%9B%BD%E4%BA%BA&sourceid=opera&ie=utf-8&oe=utf-8
在为Apple的IPhone、ipad等设备开发iOS app应用程序访问 HTTP 资源时需要对 URL 进行 Encode,比如像拼出来的 http://www.baidu.com/s?wd=中国人,其中的中国人、 特殊符号&%和空格都必须进行转译才能正确访问。
在 Java、.net 和 JS 中都有相应的 encodeURL 方法可用,在 Objective-C 语言中,你可以试下
- (NSString *)stringByAddingPercentEscapesUsingEncoding:(NSStringEncoding)enc;
来对完整的 URL(带请求参数的)进行编码,比如执行下面的代码:
NSString *url=@"http://www.baidu.com/s?wd=中国人"; NSString *encodedValue = [url stringByAddingPercentEscapesUsingEncoding:NSUTF8StringEncoding];
上面代码转换出的 encodedValue 是:
http://www.baidu.com/s?wd=%D6%D0%B9%FA%C8%CB
可见,它不会转换 URL 中的 ?%& 符号,这也正常,因为它肯定分不出哪个 & 是参数的连接符号还是参数值,你可以单独编码参数,然后在拼接成 URL 之前把属性参数值中的 ?%& 等符号分别替换成相应的编码。
base64的编码方式:
Base64 c#加密函数

- public static string Encrypt(string pToEncrypt)
- {
- byte[] barray=System.Text.UnicodeEncoding.Unicode.GetBytes(pToEncrypt);
- return Convert.ToBase64String(barray);
- }
Base64 c#解密函数
- public string Decrypt(string pToDecrypt)
- {
- byte[] mingwen = Convert.FromBase64String(pToDecrypt);
- string str = System.Text.UnicodeEncoding.Unicode.GetString(mingwen);
- return str;
- }
加密后的字符串如果存在"/" "+" "=", 在WEB的传输过程中(含有request之类动作)会发生改变,分别对应为
“/” 在客户端变为 "2F"
"+" ..........." "
"=" ..........."%3D"
所以在客户端对字符串解密前应该恢复为正确的base64码,下面是asp中的编码
- str=Replace(str," ","+")
- str=Replace(str,"%2F","/")
- str=Replace(str,"%3D","=")
以下来源:
http://blog.sina.com.cn/s/blog_70ca15d20100r1qy.html
今天着实出了一个生产问题,抽奖项目的一个查询交易报JS错误,打不开链接。
页面中用了: windows.opern()方法打开一个页面,url中的参数(抽奖活动信息)包含引号,url提前结束。
由于没有用URLEncoder,吃了亏……,下面做个小结,避免以后范同样的错误,也请各位读者引以为戒:

网页中的表单使用POST方法提交时,数据内容的类型是 application/x-www-form-urlencoded,这种类型会:
1.字符"a"-"z","A"-"Z","0"-"9",".","-","*",和"_" 都不会被编码;
2.将空格转换为加号 (+) ;
3.将非文本内容转换成"%xy"的形式,xy是两位16进制的数值;
4.在每个 name=value 对之间放置 & 符号。
web设计者面临的众多难题之一便是怎样处理不同操作系统间的差异性。这些差异性能引起URL方面的问题:例如,一些操作系统允许文件名中含有空格符,有些又不允许。大多数操作系统不会认为文件名中含有符号“#”会有什么特殊含义;但是在一个URL中,符号“#”表示该文件名已经结束,后面会紧跟一个fragment(部分)标识符。其他的特殊字符,非字母数字字符集,它们在URL或另一个操作系统上都有其特殊的含义,表述着相似的问题。为了解决这些问题,在URL中使用的字符就必须是一个ASCII字符集的固定字集中的元素,具体如下:
1.大写字母A-Z
2.小写字母a-z
3.数字 0-9
4.标点符 - _ . ! ~ * ' (和 ,)
诸如字符: / & ? @ # ; $ + = 和 %也可以被使用,但是它们各有其特殊的用途,如果一个文件名包括了这些字符( / & ? @ # ; $ + = %),这些字符和所有其他字符就应该被编码。
编码过程非常简单,任何字符只要不是ASCII码数字,字母,或者前面提到的标点符,它们都将被转换成字节形式,每个字节都写成这种形式:一个“%”后面跟着两位16进制的数值。空格是一个特殊情况,因为它们太平常了。它除了被编码成“ ”以外,还能编码为一个“+”。加号(+)本身被编码为+。当/ # = & 和?作为名字的一部分来使用时,而不是作为URL部分之间的分隔符来使用时,它们都应该被编码。
URLEncoder的两种静态方法:
public static String encode(String s)
public static String encode(String s, String encoding) throws UnsupportedEncodingException
与URLEncoder 类相对应的URLDecoder 类有两种静态方法。它们解码以x-www-form-url-encoded这种形式编码的string。也就是说,它们把所有的加号(+)转换成空格符,把所有的%xx分别转换成与之相对应的字符:
public static String decode(String s) throws Exception
public static String decode(String s, String encoding)
// Java 1.4 throws UnsupportedEncodingException
以下来源:
http://tech.sina.com.cn/s/2008-07-07/1053722241.shtml
/*
网页中的表单使用POST方法提交时,数据内容的类型是 application/x-www-form-urlencoded,这种类型会:
1.字符"a"-"z","A"-"Z","0"-"9",".","-","*",和"_" 都不会被编码;
2.将空格转换为加号 (+) ;
3.将非文本内容转换成"%xy"的形式,xy是两位16进制的数值;
4.在每个 name=value 对之间放置 & 符号。
*/
URLEncoder类包含将字符串转换为application/x-www-form-urlencoded MIME 格式的静态方法。
web设计者面临的众多难题之一便是怎样处理不同操作系统间的差异性。这些差异性能引起URL方面的问题:例如,一些操作系统允许文件名中含有空格符,有些又不允许。大多数操作系统不会认为文件名中含有符号“#”会有什么特殊含义;但是在一个URL中,符号“#”表示该文件名已经结束,后面会紧跟一个fragment(部分)标识符。其他的特殊字符,非字母数字字符集,它们在URL或另一个操作系统上都有其特殊的含义,表述着相似的问题。为了解决这些问题,我们在URL中使用的字符就必须是一个ASCII字符集的固定字集中的元素,具体如下:
1.大写字母A-Z
2.小写字母a-z
3.数字 0-9
4.标点符 - _ . ! ~ * ' (和 ,)
诸如字符: / & ? @ # ; $ + = 和 %也可以被使用,但是它们各有其特殊的用途,如果一个文件名包括了这些字符( / & ? @ # ; $ + = %),这些字符和所有其他字符就应该被编码。
编码过程非常简单,任何字符只要不是ASCII码数字,字母,或者前面提到的标点符,它们都将被转换成字节形式,每个字节都写成这种形式:一个“%”后面跟着两位16进制的数值。空格是一个特殊情况,因为它们太平常了。它除了被编码成“%20”以外,还能编码为一个“+”。加号(+)本身被编码为%2B。当/ # = & 和?作为名字的一部分来使用时,而不是作为URL部分之间的分隔符来使用时,它们都应该被编码。
WARNING这种策略在存在大量字符集的异构环境中效果不甚理想。例如:在U.S. Windows 系统中, é 被编码为 %E9. 在 U.S. Mac中被编码为%8E。这种不确定性的存在是现存的URI的一个明显的不足。所以在将来URI的规范当中应该通过国际资源标识符(IRIs)进行改善。
类URL并不自动执行编码或解码工作。你能生成一个URL对象,它可以包括非法的ASCII和非ASCII字符和/或%xx。当用方法getPath() 和toExternalForm( ) 作为输出方法时,这种字符和转移符不会自动编码或解码。你应对被用来生成一个URL对象的字符串对象负责,确保所有字符都会被恰当地编码。
幸运的是,java提供了一个类URLEncoder把string编码成这种形式。Java1.2增加了一个类URLDecoder它能以这种形式解码string。这两个类都不用初始化:
public class URLDecoder extends Object
public class URLEncoder extends Object
一、URLEncoder
在java1.3和早期版本中,类java.net.URLEncoder包括一个简单的静态方法encode( ), 它对string以如下规则进行编码:
public static String encode(String s)
这个方法总是用它所在平台的默认编码形式,所以在不同系统上,它就会产生不同的结果。结果java1.4中,这个方法被另一种方法取代了。该方法要求你自己指定编码形式:
public static String encode(String s, String encoding) throws UnsupportedEncodingException
两种关于编码的方法,都把任何非字母数字字符转换成%xx(除了空格,下划线(_),连字符(?),句号(。),和星号(*))。两者也都编码所以的非ASCII字符。空格被转换成一个加号。这些方法有一点过分累赘了;它们也把“~”,“‘”,“()”转换成%xx,即使它们完全用不着这样做。尽管这样,但是这种转换并没被URL规范所禁止。所以web浏览器会自然地处理这些被过分编码后的URL。
两中关于编码的方法都返回一个新的被编码后的string,java1.3的方法encode( ) 使用了平台的默认编码形式,得到%xx。这些编码形式典型的有:在 U.S. Unix 系统上的ISO-8859-1, 在U.S. Windows 系统上的Cp1252,在U.S. Macs上的MacRoman,和其他本地字符集等。因为编码解码过程都是与本地操作平台相关的,所以这些方法是令人不爽的,不能跨平台的。
这就明确地回答了为什么在java1.4中这种方法被抛弃了,转而投向了要求以自己指定编码形式的这种方法。尽管如此,如果你执意要使用所在平台的默认编码形式,你的程序将会像在java1.3中的程序一样,是本地平台相关的。在另一种编码的方法中,你应该总是用UTF-8,而不是其他什么。UTF-8比起你选的其他的编码形式来说,它能与新的web浏览器和更多的其他软件相兼容。
例子7-8是使用URLEncoder.encode( ) 来打印输出各种被编码后的string。它需要在java1.4或更新的版本中编译和运行。
Example 7-8. x-www-form-urlencoded strings
import java.net.URLEncoder; import java.net.URLDecoder; import java.io.UnsupportedEncodingException; public class EncoderTest { public static void main(String[] args) { try { System.out.println(URLEncoder.encode("This string has spaces","UTF-8")); System.out.println(URLEncoder.encode("This*string*has*asterisks","UTF-8")); System.out.println(URLEncoder.encode("This%string%has%percent%signs", "UTF-8")); System.out.println(URLEncoder.encode("This+string+has+pluses","UTF-8")); System.out.println(URLEncoder.encode("This/string/has/slashes","UTF-8")); System.out.println(URLEncoder.encode("This"string"has"quote"marks", "UTF-8")); System.out.println(URLEncoder.encode("This:string:has:colons","UTF-8")); System.out.println(URLEncoder.encode("This~string~has~tildes","UTF-8")); System.out.println(URLEncoder.encode("This(string)has(parentheses)", "UTF-8")); System.out.println(URLEncoder.encode("This.string.has.periods","UTF-8")); System.out.println(URLEncoder.encode("This=string=has=equals=signs", "UTF-8")); System.out.println(URLEncoder.encode("This&string&has&ersands","UTF-8")); System.out.println(URLEncoder.encode("Thiséstringéhasé non-ASCII characters","UTF-8")); // System.out.println(URLEncoder.encode("this中华人民共和国","UTF-8")); } catch (UnsupportedEncodingException ex) {throw new RuntimeException(" Broken VM does not support UTF-8"); } } }
下面就是它的输出。需要注意的是这些代码应该以其他编码形式被保存而不是以ASCII码的形式,还有就是你选择的编码形式应该作为一个参数传给编译器,让编译器能据此对源代码中的非ASCII字符作出正确的解释。
% javac -encoding UTF8 EncoderTest %
java EncoderTest
This+string+has+spaces
This*string*has*asterisks
This%25string%25has%25percent%25signs
This%2Bstring%2Bhas%2Bpluses
This%2Fstring%2Fhas%2Fslashes
This%22string%22has%22quote%22marks
This%3Astring%3Ahas%3Acolons
This%7Estring%7Ehas%7Etildes
This%28string%29has%28parentheses%29
This.string.has.periods
This%3Dstring%3Dhas%3Dequals%3Dsigns
This%26string%26has%26ampersands
This%C3%A9string%C3%A9has%C3%A9non-ASCII+characters
特别需要注意的是这个方法编码了符号,“\” ,&,=,和:。它不会尝试着去规定在一个URL中这些字符怎样被使用。由此,所以你不得不分块编码你的URL,而不是把整个URL一次传给这个方法。这是很重要的,因为对类URLEncoder最通常的用法就是查询string,为了和服务器端使用GET方法的程序进行交互。例如,假设你想编码这个查询sting,它用来搜索AltaVista网站:
pg=q&kl=XX&stype=stext&q=+"Java+I/O"&search.x=38&search.y=3
这段代码对其进行编码:
String query = URLEncoder.encode( "pg=q&kl=XX&stype=stext&q=+"Java+I/O"&search.x=38&search.y=3");System.out.println(query);
不幸的是,得到的输出是:
pg%3Dq%26kl%3DXX%26stype%3Dstext%26q%3D%2B%22Java%2BI%2FO%22%26search.x%3D38%26search.y%3D3
出现这个问题就是方法URLEncoder.encode( ) 在进行盲目地编码。它不能区分在URL或者查询string中被用到的特殊字符(象前面string中的“=”,和“&”)和确实需要被编码的字符。由此,所以URL需要像下面这样一次只编码一块:
String query = URLEncoder.encode("pg"); query += "="; query += URLEncoder.encode("q"); query += "&"; query += URLEncoder.encode("kl"); query += "="; query += URLEncoder.encode("XX"); query += "&"; query += URLEncoder.encode("stype"); query += "="; query += URLEncoder.encode("stext"); query += "&"; query += URLEncoder.encode("q"); query += "="; query += URLEncoder.encode(""Java I/O""); query += "&"; query += URLEncoder.encode("search.x"); query += "="; query += URLEncoder.encode("38"); query += "&"; query += URLEncoder.encode("search.y"); query += "="; query += URLEncoder.encode("3"); System.out.println(query);
这才是你真正想得到的输出:
pg=q&kl=XX&stype=stext&q=%2B%22Java+I%2FO%22&search.x=38&search.y=3
例子7-9是一个QueryString类。在一个java对象中,它使用了类URLEncoder来编码连续的属性名和属性值对,这个java对象被用来发送数据到服务器端的程序。
当你在创建一个QueryString对象时,你可以把查询string中的第一个属性对传递给类QueryString的构造函数,得到初始string。如果要继续加入后面的属性对,就应调用方法add(),它也能接受两个string作为参数,能对它们进行编码。方法getQuery( )返回一个属性对被逐个编码后得到的整个string。
Example 7-9. -The QueryString class
package com.macfaq.net; import java.net.URLEncoder; import java.io.UnsupportedEncodingException; public class QueryString { private StringBuffer query = new StringBuffer(); public QueryString(String name, String value) { encode(name, value); } public synchronized void add(String name, String value) { query.append('&'); encode(name, value); } private synchronized void encode(String name, String value) { try { query.append(URLEncoder.encode(name, "UTF-8")); query.append('='); query.append(URLEncoder.encode(value, "UTF-8")); } catch (UnsupportedEncodingException ex) { throw new RuntimeException("Broken VM does not support UTF-8"); } } public String getQuery() { return query.toString(); } public String toString() { return getQuery(); } }
利用这个类,现在我们就能对前面那个例子中的string进行编码了:
QueryString qs = new QueryString("pg", "q"); qs.add("kl", "XX"); qs.add("stype", "stext"); qs.add("q", "+"Java I/O""); qs.add("search.x", "38"); qs.add("search.y", "3"); String url = "http://www.altavista.com/cgi-bin/query?" + qs; System.out.println(url);
二、URLDecoder
与URLEncoder 类相对应的URLDecoder 类有两种静态方法。它们解码以x-www-form-url-encoded这种形式编码的string。也就是说,它们把所有的加号(+)转换成空格符,把所有的%xx分别转换成与之相对应的字符:
public static String decode(String s) throws Exception public static String decode(String s, String encoding) // Java 1.4 throws UnsupportedEncodingException
第一种解码方法在java1.3和java1.2中使用。第二种解码方法在java1.4和更新的版本中使用。如果你拿不定主意用哪种编码方式,那就选择UTF-8吧。它比其他任何的编码形式更有可能得到正确的结果。
如果string包含了一个“%”,但紧跟其后的不是两位16进制的数或者被解码成非法序列,该方法就会抛出IllegalArgumentException 异常。当下次再出现这种情况时,它可能就不会被抛出了。这是与运行环境相关的,当检查到有非法序列时,抛不抛出IllegalArgumentException 异常,这时到底会发生什么是不确定的。在Sun's JDK 1.4中,不会抛出什么异常,它会把一些莫名其妙的字节加进不能被顺利编码的string中。这的确令人头疼,可能就是一个安全漏洞。
由于这个方法没有触及到非转义字符,所以你可以把整个URL作为参数传给该方法,不用像之前那样分块进行。例如:
String input = "http://www.altavista.com/cgi-bin/" + "query? pg=q&kl=XX&stype=stext&q=%2B%22Java+I%2FO%22&search.x=38&search.y=3"; try { String output = URLDecoder.decode(input, "UTF-8"); System.out.println(output); }
原文来自:http://jishudaima.iteye.com/blog/957169
request对象读取请求参数时默认采用的英文字符集ISO-8859-1。如果请求参数的值含有中文字符,读出的字符串将是乱码。读取含中文字符的参数值需要正确的设置request对象的字符编码。JSP页面需要在调用getParameter()方法之前,调用setCharacterEncoding()方法设置使用什么字符集。常用的表示中文的字符集有:GB2312、GBK、GB18030、BIG5、UTF-8。字符集的设置应该和发送请求的JSP页面的编码一致。
<%@ page language="java" contentType="text/html; charset=GB18030"
pageEncoding="GB18030"%>
<%
//设置字符集语句需要放在所有getParameter()方法之前
request.setCharacterEncoding("GB18030");
String name = request.getParameter("name");
if(name!=null) {
out.println("
姓名:" + name+"
");}
%>
正确读取中文字符串的情况:
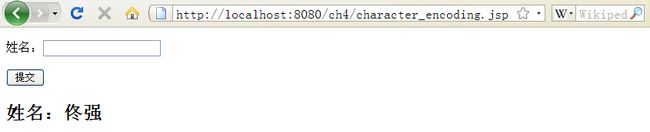
去掉request.setCharaterEncoding("GB18030")出现乱码的情况:
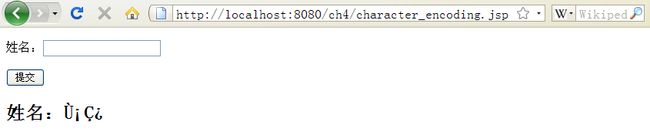
原文链接:http://jishudaima.iteye.com/blog/957169
一就是指定页面编码指定为<%@ page contentType="text/html; charset=gb2312"%>和,然后request. getParameter()得到参数后通过getBytes()转码。我原来用jsp+servlet写程序时,也是这样处理,而且可行。但由于现在整个项目所有页面编码均指定为utf-8,所以全改为gb2312不太现实。 网上也有说通过添加过滤器的方式,设置request如下:request.seCharacterEncoding ("utf-8"),得到参数后通过new String(iso.getBytes("ISO-8859-1"),"utf-8")即可。尝试了一下,依旧失败。奇数乱码,偶数正常。
二就是通过java.net.URLEncoder.encode(keywords)和decode方法来处理。在发送请求之前,先通过encode()对汉字进行编码,在处理参数时,用decode解码。如下示例:
<%
String paramValue = "汉字参数";
%>
提交">
这种方法或许可行,但由于我用的struts框架,按此方法不好处理。
花了一个晚上和一个上午,终于找到第三种可行的办法。通过javascript的escape来对参数进行处理后传输,再在后台调用一个模拟实现了javascript的escape和unescape方法的工具类对参数进行解码。步骤如下:
1. JSP页面,对含汉字的参数调用两次escape。
document.forms[0].action = "/query.do?act=getResult&queryValue=" + escape(escape(queryCondition));
document.forms[0].submit();
为何要调用两次escape,我没弄明白。测试了一下,如果只调用一次,在后台通过request. getParameter(“queryValue”)还真得不到值。
2. 通过调用工具类Escape. unescape()方法进行解码得可得到中文。实在佩服写这个工具类的人。这世上真是什么强人都有。Escape如下:
public class Escape {
private final static String[] hex = { "00", "01", "02", "03", "04", "05",
"06", "07", "08", "09", "0A", "0B", "0C", "0D", "0E", "0F", "10",
"11", "12", "13", "14", "15", "16", "17", "18", "19", "1A", "1B",
"1C", "1D", "1E", "1F", "20", "21", "22", "23", "24", "25", "26",
"27", "28", "29", "2A", "2B", "2C", "2D", "2E", "2F", "30", "31",
"32", "33", "34", "35", "36", "37", "38", "39", "3A", "3B", "3C",
"3D", "3E", "3F", "40", "41", "42", "43", "44", "45", "46", "47",
"48", "49", "4A", "4B", "4C", "4D", "4E", "4F", "50", "51", "52",
"53", "54", "55", "56", "57", "58", "59", "5A", "5B", "5C", "5D",
"5E", "5F", "60", "61", "62", "63", "64", "65", "66", "67", "68",
"69", "6A", "6B", "6C", "6D", "6E", "6F", "70", "71", "72", "73",
"74", "75", "76", "77", "78", "79", "7A", "7B", "7C", "7D", "7E",
"7F", "80", "81", "82", "83", "84", "85", "86", "87", "88", "89",
"8A", "8B", "8C", "8D", "8E", "8F", "90", "91", "92", "93", "94",
"95", "96", "97", "98", "99", "9A", "9B", "9C", "9D", "9E", "9F",
"A0", "A1", "A2", "A3", "A4", "A5", "A6", "A7", "A8", "A9", "AA",
"AB", "AC", "AD", "AE", "AF", "B0", "B1", "B2", "B3", "B4", "B5",
"B6", "B7", "B8", "B9", "BA", "BB", "BC", "BD", "BE", "BF", "C0",
"C1", "C2", "C3", "C4", "C5", "C6", "C7", "C8", "C9", "CA", "CB",
"CC", "CD", "CE", "CF", "D0", "D1", "D2", "D3", "D4", "D5", "D6",
"D7", "D8", "D9", "DA", "DB", "DC", "DD", "DE", "DF", "E0", "E1",
"E2", "E3", "E4", "E5", "E6", "E7", "E8", "E9", "EA", "EB", "EC",
"ED", "EE", "EF", "F0", "F1", "F2", "F3", "F4", "F5", "F6", "F7",
"F8", "F9", "FA", "FB", "FC", "FD", "FE", "FF" };
private final static byte[] val = { 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x00, 0x01,
0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x0A, 0x0B, 0x0C, 0x0D, 0x0E, 0x0F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F,
0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F, 0x3F };
/** */
/**
* 编码
*
* @param s
* @return
*/
public static String escape(String s) {
StringBuffer sbuf = new StringBuffer();
int len = s.length();
for (int i = 0; i < len; i++) {
int ch = s.charAt(i);
if ('A' <= ch && ch <= 'Z') {
sbuf.append((char) ch);
} else if ('a' <= ch && ch <= 'z') {
sbuf.append((char) ch);
} else if ('0' <= ch && ch <= '9') {
sbuf.append((char) ch);
} else if (ch == '-' || ch == '_' || ch == '.' || ch == '!'
|| ch == '~' || ch == '*' || ch == '\'' || ch == '('
|| ch == ')') {
sbuf.append((char) ch);
} else if (ch <= 0x007F) {
sbuf.append('%');
sbuf.append(hex[ch]);
} else {
sbuf.append('%');
sbuf.append('u');
sbuf.append(hex[(ch >>> 8)]);
sbuf.append(hex[(0x00FF & ch)]);
}
}
return sbuf.toString();
}
/** */
/**
* 解码 说明:本方法保证 不论参数s是否经过escape()编码,均能得到正确的“解码”结果
*
* @param s
* @return
*/
public static String unescape(String s) {
StringBuffer sbuf = new StringBuffer();
int i = 0;
int len = s.length();
while (i < len) {
int ch = s.charAt(i);
if ('A' <= ch && ch <= 'Z') {
sbuf.append((char) ch);
} else if ('a' <= ch && ch <= 'z') {
sbuf.append((char) ch);
} else if ('0' <= ch && ch <= '9') {
sbuf.append((char) ch);
} else if (ch == '-' || ch == '_' || ch == '.' || ch == '!'
|| ch == '~' || ch == '*' || ch == '\'' || ch == '('
|| ch == ')') {
sbuf.append((char) ch);
} else if (ch == '%') {
int cint = 0;
if ('u' != s.charAt(i + 1)) {
cint = (cint << 4) | val[s.charAt(i + 1)];
cint = (cint << 4) | val[s.charAt(i + 2)];
i += 2;
} else {
cint = (cint << 4) | val[s.charAt(i + 2)];
cint = (cint << 4) | val[s.charAt(i + 3)];
cint = (cint << 4) | val[s.charAt(i + 4)];
cint = (cint << 4) | val[s.charAt(i + 5)];
i += 5;
}
sbuf.append((char) cint);
} else {
sbuf.append((char) ch);
}
i++;
}
return sbuf.toString();
}
}
在后台文件里面生成页面链接时,如遇到中文参数时,也可调用Escape. escape()方法达
到javascript的escape()功能。和上面一样,也是需要调用两次。示例:
paramString += "&queryName=" + this.getQueryName() + "&queryValue="
+ Escape.escape(Escape.escape(this.getQueryValue()));
资料来源:http://blog.sina.com.cn/s/blog_632bb1950100l77z.html
http请求是以ISO-8859-1的编码来传送url的,如果页面的content-type为utf-8,那么在发送请求时,会将字符转成utf-8后进行传送.
这样服务器收到字节流后,将它转成相应的字符,request.getParameter("user")直接得到了字符串,从字节流到字符流的转换系统帮我们做了(这就是错误来源)。
一个字符串以什么样的编码转换成字节流,就必须以什么样的编码进行还原.因此,先把它还原成ISO8859_1的编码方式,再按照我们的方式编码,就不会出现乱码了。
于是就有了上面注释起来的那个代码的解决方案:
String name = new String(request.getParameter("user").getBytes("ISO8859_1"),"UTF-8");
String name = new String(request.getParameter("user").getBytes("ISO8859_1"),"GBK");
后面的根据charset的声明来该,如果是GBK,就改成相应的就可以了。
如果是第一个页面输入信息提交到第二个页面显示
在第二个页面开始的时候<%@ page contentType="text/html; charset=gb2312" %>
将里面的charset改为charset=ISO8859_1即可。
韩顺平对中文的讲解:
java不是中国人写的,因而在网络传输的时候不支持中文。三种方法是:
1、重新转码,new String(u.getBytes("iso-8895-1"), "gb2312");
2、通过过滤器来解决问题
3、通过配置server.xml文件来解决