【天池】 UserBehavior用户行为--数据分析练习
写在前面:本文主要涉及mysql和python的基本运用。为方便回顾总结,文中记录了解决思路、代码实现、采坑过程等。内容较多,还请在目录中各取所需。
分析结果在第四节。
目录
- 一、问题描述
- 1.数据集
- 2.分析思路
- 二、数据处理(MySQL)
- 1.数据抽样、导入数据
- 2.转换时间戳到日期格式
- 3.数据清洗
- 4.新增两个辅助列
- 5.最终数据
- 6.导出数据到csv文件
- 三、数据分析(Python)
- 0.准备工作
- 1.网站
- PV
- UV
- 每天
- 每小时
- 转化率
- 成交转化率
- pv-cart-buy
- pv-fav-buy
- 2.用户
- 用户行为
- 复购率
- 单日复购率
- n日内复购率
- 各时段上的行为分布
- 用户质量
- 消费贡献率
- 消费前十
- 用户评分(RMF)
- 3.商品
- 浏览、加购、收藏、购买前十
- 浏览--购买转化比
- 加购--购买转化比
- 销售量分布
- 四、分析总结
一、问题描述
1.数据集
数据下载地址:User Behavior
根据官网介绍,本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于原始数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| UserID | 用户ID,整数类型,序列化后的用户ID |
| ItemID | 商品ID,整数类型,序列化后的商品ID |
| CategoryID | 商品类目ID,整数类型,序列化后的商品所属类目ID |
| BehaviorType | 行为类型,字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| TimeStamp | 时间戳,行为发生的时间戳 |
其中用户行为类型一共有四种,分别是:
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
整个原始数据集大小说明如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 987,994 |
| 商品数量 | 4,162,024 |
| 商品类目数量 | 9,439 |
| 所有行为数量 | 100,150,807 |
可见数据量非常大,受电脑硬件限制,不太可能对整个数据集进行分析,因此采用随机抽样的方法从数据集中随机抽取2%的数据,作为一个抽样样本,进而对该样本进行分析。具体抽样过程将在数据处理中描述。
2.分析思路
本次数据分析将首先使用MySQL数据库,在Workbench上进行数据处理、数据清洗等操作,得到可用于分析的数据。随后用Python进行数据分析和可视化,这过程中会用到pandas、numpy、matplotlib、pyecharts这几个包,因此选择在Jupyter Notebook上操作。
需知,由于实际分析使用的是下载数据的抽样数据,而下载数据本身也是真实数据总体的随机抽样,但是我们在官方描述中并不知道这个数据是如何抽样出来的。因此,我们分析的对象将是抽样数据的抽样数据。样本作为总体的一个代表,样本本身数据的大小不足以说明什么,而且由于不清楚抽样规则我们也无法由样本数据倒推出真实数据,所以分析中应该将目光关注于像某某比率、时间跨度上的某种趋势等这类指标。
同时由于数据的时间跨度为 2017年11月25日至2017年12月3日,为期9天,这样的时间跨度不够长,不足以分析很多以周、月甚至年为单位的周期性指标,比如用户生命周期、用户流失率、回购率(上一期末活跃会员在下一期有购买行为的会员比率)、留存率(某时间节点的活跃会员在一个周期内的留存比率)等。在这样一个短期数据内,更多的应试图寻找一些通用的指标,一些蕴含于每天日常之中的指数。
为了清晰分析思路,此处运用结构化思维和公式化思维,找出了一些可以进行分析的内容,以思维导图形式展现如下。后面的分析都将以这个思路展开,分析图中罗列的各点。
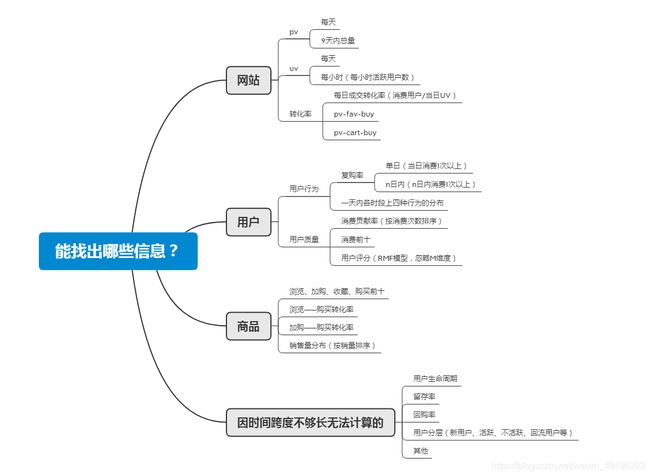
二、数据处理(MySQL)
为方便后面的代码理解,特此说明我在MySQL中,建立名为"ubanalyze"的库,在该库下建立名为"ubsample"的表,初始设置表头有:UserID(主键)、ItemID(主键)、CategoryID、BehaviorType、TimeStamp(主键)。
1.数据抽样、导入数据
第一次面对这么大的数据量,为了将数据导入至数据库,也是好好研究了一番,个中学习过程记录在我另一篇文章中:MySQL练习记录:导入大体积CSV文件
此处截取文中关键操作如下:
- 使用Jupyter Notebook
- 在编辑页输入如下代码读取源文件:
import pandas as pd
data = pd.read_csv(r'<文件路径>')
读取完成后输入data.info()查看数据状态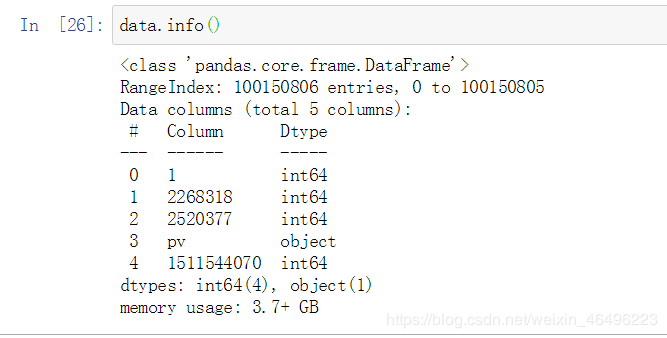
- 输入如下代码进行随机抽样:
data=data.sample(frac=0.02,replace=False,axis=0) #这是我的参数,具体参见下方解释
data.to_csv(r"<抽样完成后另存为新文件的路径>")
sample方法的用法解释:
.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
- n表示要抽取多少行,如想抽取确定多少行数据,可设置该参数。
- frac表示抽取比列,如不确定抽取多少行数据,只需要抽取一定比例数据,可设置该参数,例如frac=0.5表示抽取50%的数据。
- replace表示是否为放回抽样,例如replace=True表示有放回抽样。
- weights表示每个样本的权重。
- random_state表示随机数种子发生器,设置random_state=None,表示数据不重复,random_state=1,表示可以取重复数据。
- axis表示选择抽取数据的行或列,设置axis=0时按行随机抽样,axis=1时按列随机抽样。
-
完整代码如下:
-
然后准备将抽样数据导入数据库。在导入前用EXCEL打开文件发现数据多出来一列,实际上通过代码
data.head()可以知道多出来的是序号列,要将其删除。
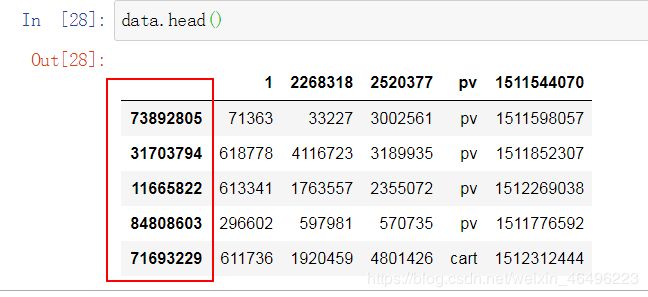
- 现将样本数据导入MySQL,先在workbench中新建一个表,主要是在建表时加上一列记为NonName,与等会要删的列对应,代码如下:

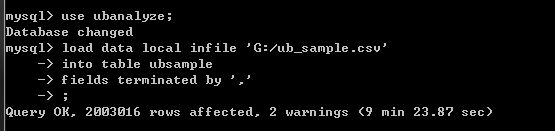
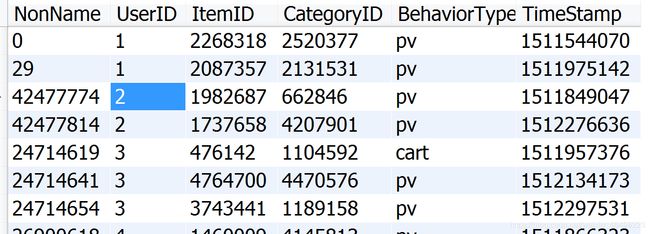
- 打开workbench,可以在相应表中看到已经有数据了:
- 使用DROP语句将目标列删掉,代码如下:
ALTER TABLE <表名> DROP colume <列名>;
实际操作结果如下,可以看到成功删掉了多余列,得到所需的数据集: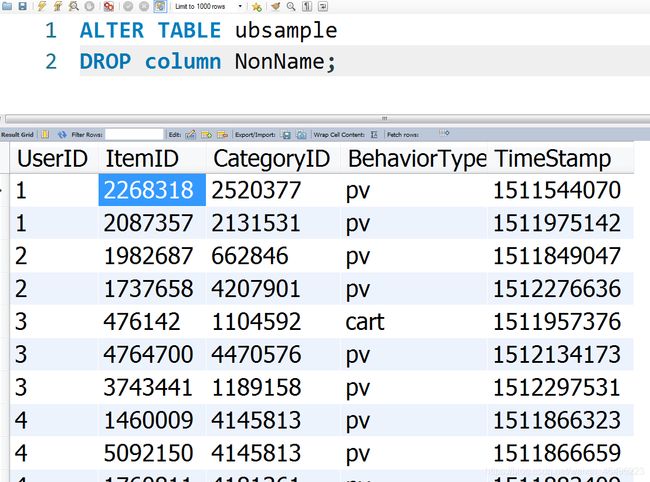
然后对抽样数据集进行数据维度统计,抽样后的样本数据集维度说明如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 712,404 |
| 商品数量 | 746,725 |
| 商品类目数量 | 7,071 |
| 所有行为数量 | 2,003,016 |
2.转换时间戳到日期格式
由于数据集使用的是时间戳,不便于分析,应将之转化为易于识别的日期格式。使用如下代码生成一个新的DateTime列:
SET SQL_SAFE_UPDATES = 0; #更改安全设置,否则更新列时报错
ALTER TABLE <表名> ADD COLUMN <新增列名> TIMESTAMP(0) NULL;
UPDATE <表名>
SET <新增列名> = FROM_UNIXTIME(<时间戳所在列>); #将TimeStamp列的时间戳转化为日期格式赋值到DateTime列
我的执行代码如下:

经检查发现DateTime有2,003,007条数据,相比TimeStamp的2,003,016条数据缺失了9条数据。
通过筛选发现这9条数据的时间戳前面带了符号“-”,导致无法正常转换。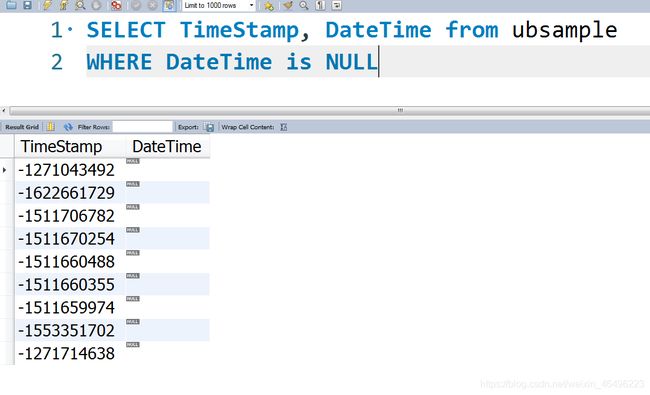
因此针对这9条数据,使用如下代码进行处理,使之顺利生成日期码:
#对带“-”的时间戳进行更改
UPDATE ubsample
SET TimeStamp = right(TimeStamp, 10) #从右截取10位字符串
WHERE TimeStamp like '-%'; #筛选出以“-”开头的9个时间戳
#更新对应的9个日期码
UPDATE ubsample
SET DateTime = FROM_UNIXTIME(TimeStamp) #将TimeStamp列的时间戳转化为日期格式赋值到DateTime列
WHERE DateTime is NULL #将范围限制在这9条数据
由此时间戳转换工作就全部完成。
3.数据清洗
1. 去除不需要的数据
首先通过筛选可以知道DateTime最小日期为’1979-03-16 02:40:06’,最大日期为’2036-10-23 00:03:08’,显然存在不符合分析要求的数据。此处分析我们只需要截取时间跨度在2017年11月25日0时0分0秒到2017年12月4日0时0分0秒之间的数据。
使用如下代码将不必要的代码删除:
SET SQL_SAFE_UPDATES = 0;
DELETE FROM ubsample
WHERE DateTime < '2017-11-25 00:00:00'
OR DateTime > '2017-12-04 00:00:00';
删除了1119条数据。
日期最大最小值均符合要求: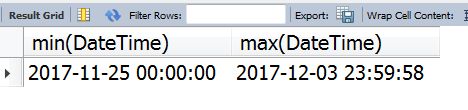
2. 检查有无缺失值
因主键已设置Not Null,故重点检查非主键列。
对CategoryID检查:
SELECT count(CategoryID) as num FROM ubsample
WHERE CategoryID is NULL
对BehaviorType检查:
SELECT count(BehaviorType) as num FROM ubsample
WHERE BehaviorType = ''
对DateTime检查:
SELECT count(DateTime) as num FROM ubsample
WHERE DateTime is NULL
以上全部返回0,说明数据无空值,数据完整。
3. 检查有无异常值
主要针对BehaviorType列,查看有无指定字符之外的数据
SELECT count(BehaviorType) as num FROM ubsample
WHERE BehaviorType <> 'pv' and 'buy' and 'cart' and 'fav'
返回0,说明无异常值。
4. 检查是否需要去重
首先直接在表里翻一翻就能很容易找到同一个用户产生的相似数据,区别只在于发生时间不同:

此处实际上不需要去重,分析可知,在电商平台上,用户可能对同一个产品多次浏览,点击、添加购物车甚至购买等行为都可能多次发生,而且多次相同操作在分析中应该视作不同的行为记录,例如对同一个商品进行一次浏览和不同时间点下的多次浏览,反映出来的用户行为是不一样的。
4.新增两个辅助列
为了分析方便,还需要在表格后面新增"Dates"列,只记录年月日,以及"Hours"列,记录数据的小时数。使用如下代码:
SET SQL_SAFE_UPDATES = 0;
ALTER TABLE ubsample ADD COLUMN Dates CHAR(10) NULL;
UPDATE ubsample
SET Dates = SUBSTRING(DateTime FROM 1 FOR 10);
ALTER TABLE ubsample ADD COLUMN Hours CHAR(10) NULL;
UPDATE ubsample
SET Hours = SUBSTRING(DateTime FROM 12 FOR 2);
完成后可以看到表中已经有相应数据了

5.最终数据
经过上述步骤,现在得到了可以用于分析的数据集,经统计最终的数据情况如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 712,167 |
| 商品数量 | 746,482 |
| 商品类目数量 | 7,071 |
| 所有行为数量 | 2,001,897 |
| 列名称 | 说明 |
|---|---|
| UserID(主键) | 用户ID,整数类型,序列化后的用户ID |
| ItemID(主键) | 商品ID,整数类型,序列化后的商品ID |
| CategoryID | 商品类目ID,整数类型,序列化后的商品所属类目ID |
| BehaviorType | 行为类型,字符串,枚举类型,包括(‘pv’, ‘buy’, ‘cart’, ‘fav’) |
| TimeStamp(主键) | 时间戳,行为发生的时间戳 |
| DateTime | 时间戳转化的日期格式 |
| Dates | 时间戳中对应的年月日 |
| Hours | 时间戳中的小时数 |
6.导出数据到csv文件
在workbench中导出数据到csv文件速度很慢,因此我选择直接登录数据库用指令操作。
在cmd窗口中登录到数据库之后,执行代码应该是:
use <库名>;
SELECT * FROM <表名>
INTO OUTFILE '<导出路径>'
FIELDS TERMINATED BY ',' #字段用逗号分隔
OPTIONALLY ENCLOSED BY '"' #字段用双引号括起
LINES TERMINATED BY '\n'; #每行以换行符分隔
在操作过程中取到了一些问题,执行报错,经百度发现是MySQL的文件写出权限有点问题,首先查询权限情况:
`select @@global.secure_file_priv;`
secure_file_priv这个参数的作用是限制数据导入和导出操作的效果,例如执行LOAD DATA、SELECT … INTO OUTFILE语句和LOAD_FILE()函数。这些操作需要用户具有FILE权限。如果这个参数为NULL,MySQL服务会禁止导入和导出操作,如果这个参数设为一个目录名,MySQL服务只允许在这个目录中执行文件的导入和导出操作。这个目录必须存在,MySQL服务不会创建它。
更多解释可以参考:MYSQL数据导出与导入,secure_file_priv参数设置
而我返回的结果正是NULL

根据查到的资料,可以在my.ini配置文件中修改secure_file_priv参数,我的配置文件中根本没有这个参数,所以我直接新增一行:
#位置权限,不做任何限制
secure_file_priv =
随后重启MySQL服务:
net stop mysql;
net start mysql;
重新登录MySQL,再次查看secure_file_priv参数,显示为空,可见已经没有限制了。再次输入命令,这次就顺利执行,而且很快就导出完成。截图如下:
至此导出操作完成,在目标路径下就可以看到相关文件了。
三、数据分析(Python)
注:本节所有代码均写于一个工作文件,因此需特别注意各变量的命名不要重复和前后关联,无关紧要的中间变量统一命名为temp+数字的格式。
0.准备工作
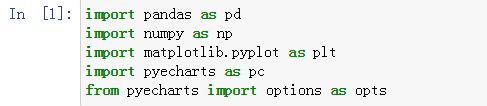
后续分析使用Jupyter Notebook,打开后先加载下面这几个东西,是后面代码都会用到的,其中pyecharts是本次画图选择使用的包:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pyecharts as pc
from pyecharts import options as opts
Tips:这里有个小坑,因为anaconda里没有预载pyecharts,需要手动安装这个库。需知,这个库是从JS平台的echarts移植到python这边的,版本以v1.0.0为界做一个划分,有很大的区别,建议安装v1.0之后的版本,具体了解可参阅:这里。
我安装的是最新版,版本日志可以在这里查看。
安装也很简单,在Jupyter Prompt里输入:
pip install pyrcharts==1.7.1
随后等待安装完成即可,完成后可查看已有的库:
pip list
因为新版pyecharts操作语法变化很大,网上很多教程都是1.0之前的操作方法,在1.0+版本中已不适用,后续作图时建议查阅官方文档学习使用方法:Pyecharts官方文档
由于前期准备好的抽样数据文件是没有表头的,需要在读取该文件时手动设置增加表头,代码如下:
data = pd.read_csv('G:/ubsample.csv',
header=None,
names=['UserID','ItemID','CategoryID','BehaviorType','TimeStamp','DateTime','Dates','Hours']
)
这样数据就符合要求了:

同时可以使用下述代码保存一个副本:
data.to_csv('G:/ubsample_1.csv',index=False)
1.网站
PV
(1)每日PV计算如下:
首先观察,对数据进行按日期和消费行为的分组:
data.groupby(by = ['Dates','BehaviorType']).count()

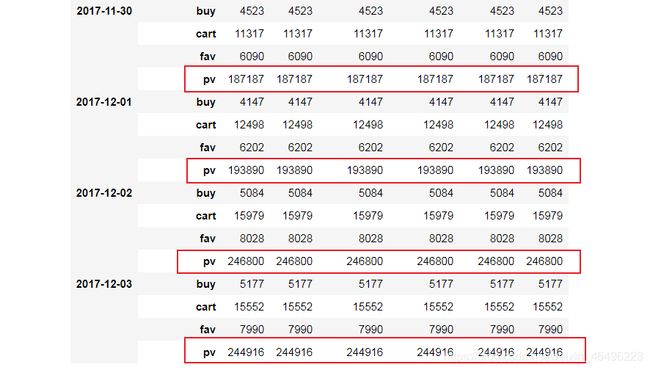
结果如上图所示,现在的目标是把每日浏览量也就是红色方框内的数字提取出来,放到一个单独的列表中。我的方法是使用while循环取数:
#每日pv列表
everyday_pv = data.groupby(['Dates','BehaviorType']).count() #将聚类结果保存为一个中间表
i = 3 #定位条件
list_pv = [] #准备好空列表
while i < 37: #最后一天的定位条件是36
list_pv.append(everyday_pv['UserID'][i]) #将目标数更新到列表中
i += 4
list_pv #输出结果
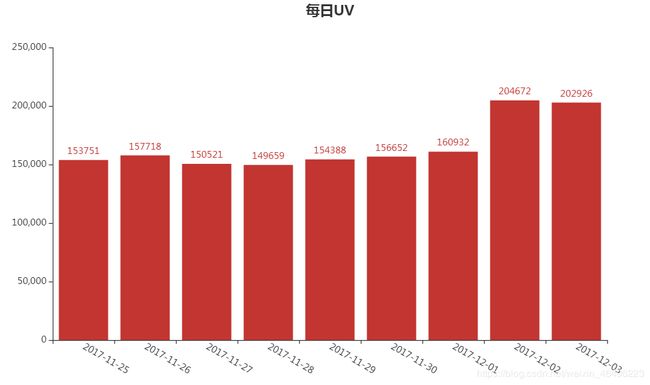
每日PV结果如下图所示:

画成柱状图:
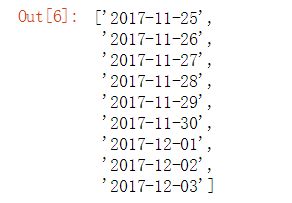
首先生成一组时间列表,范围从2017年11月25日至2017年12月3日,这个列表后面也会用到。
#生成时间列表
import datetime
date_list = []
dt = datetime.datetime.strptime('2017-11-25', "%Y-%m-%d")
date = '2017-11-25'
while date <= '2017-12-03':
date_list.append(date)
dt = dt + datetime.timedelta(1)
date = dt.strftime("%Y-%m-%d")
date_list
然后绘制柱形图,这里代码中y轴赋值我直接复制粘贴了list_pv的结果,因为直接引用的话代码无报错但是图上没有内容,只有横坐标,调试很久也不知道为什么。就不在这里浪费时间了,以后有机会再研究这个问题。
#pv柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(date_list)
.add_yaxis(series_name="pv",
yaxis_data = [186355, 191178, 179766, 177405, 184801, 187187, 193890, 246800, 244916]
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(type_="value"),
title_opts=opts.TitleOpts(title="每日PV", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("每日PV柱状图.html")
)

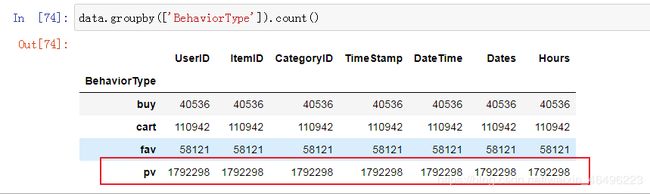
(2)总PV统计BehaviorType中的’pv’数量即可:
data.groupby(['BehaviorType']).count()
结果如下,2017年11月25日至2017年12月3日总浏览量为1,792,298次:
UV
每天
统计口径是每00:00-24:00内相同的客户端IP只被计算一次,因此应以日期为单位,对每一天单独做统计,而且每一天的用户应做去重处理,我的方法如下:
#每日uv
table_uv = (data.groupby(by = ['Dates','UserID']).size()).groupby(['Dates']).count()
table_uv #输出结果
这个方法是我自己想的。大概意思是每个用户可以视为一个独一无二的IP地址,那么只要算出每天有多少个不同的用户访问就是每天的UV了,那么可以对数据按日期和用户ID做二级分组,而作为分组条件,不能直接去数有多少个用户ID,此时就要接着使用size()方法得到每个用户ID在一天内出现了多少次,到这里为止得到的结果像这样:
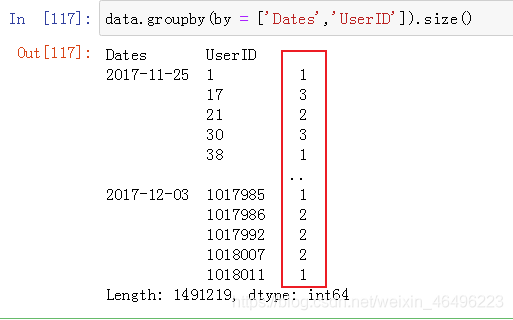
Dates和UserID是分组条件,红色方框内才是由size()产生的数据。在这个基础上,将之视为一个整体,再套一个groupby().count(),这一步就只按日期分组,把一个日期下的对应红色方框内的数据计数(注意不是求和),得到的数据就是每天内有多少个不同的用户了。
UV结果如下图所示,经检验数据确是符合分组去重要求的:

画成柱状图:
与pv类似的,代码稍作修改就行。然而这里的y轴赋值直接引用table_uv就可以了。
#uv柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(date_list)
.add_yaxis(series_name="uv",
yaxis_data = table_uv.tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(type_="value"),
title_opts=opts.TitleOpts(title="每日UV", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("每日UV柱状图.html")
)
最后,将PV与UV数据放在一张图上,看看两者之间的差距:
#PV和UV柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(date_list)
.add_yaxis(series_name="pv",
yaxis_data = [186355, 191178, 179766, 177405, 184801, 187187, 193890, 246800, 244916],
stack="pv"
)
.add_yaxis(series_name="uv",
yaxis_data = table_uv.tolist(),
stack="uv"
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
yaxis_opts=opts.AxisOpts(type_="value"),
title_opts=opts.TitleOpts(title="每日PV-UV", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=True, pos_right='right')
)
.render("每日PV-UV柱状图.html")
)

每小时
统计口径为计算每一天0-24小时内以每1小时为区间,各区间段上有多少用户ID。观察每天的用户活跃时间的分布,并比较2017年11月25日至2017年12月3日每天的数据之间的差异。
类似于每日UV,这里也是求一定时间内不同用户ID的数量,只不过这里的时间区间是一小时。因此算法思路是类似的,可以用如下办法实现:
(pyecharts作图输出结果可以根据点亮、熄灭各个标签做到只在图上显示想看的信息,因此可以一次将9天的数据放在一张图上,不必再单独生成每天的图表)
#每小时活跃用户数
from pyecharts.charts import Line
"""横坐标"""
x_data = []
i = 0
while i < 24:
x_data.append(i)
i += 1
"""定义一个获取纵坐标列表的函数,即每小时的活跃用户数"""
def ydata(day):
temp = data[data['Dates']==day]
hour_uv = (temp.groupby(by = ['Hours','UserID']).size()).groupby(['Hours']).count()
temp1 = pd.DataFrame(hour_uv)
y_data = temp1[0].tolist()
return y_data
"""作图"""
(
Line(init_opts=opts.InitOpts(width="1200px", height="400px")) #初始化表长宽
.add_xaxis(xaxis_data=x_data) #横坐标
.add_yaxis(
series_name="2017-11-25",
stack="活跃度11-25",
y_axis=ydata("2017-11-25"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-26",
stack="活跃度11-26",
y_axis=ydata("2017-11-26"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-27",
stack="活跃度11-27",
y_axis=ydata("2017-11-27"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-28",
stack="活跃度11-28",
y_axis=ydata("2017-11-28"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-29",
stack="活跃度11-29",
y_axis=ydata("2017-11-29"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-11-30",
stack="活跃度11-30",
y_axis=ydata("2017-11-30"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-12-01",
stack="活跃度12-01",
y_axis=ydata("2017-12-01"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-12-02",
stack="活跃度12-02",
y_axis=ydata("2017-12-02"),
label_opts=opts.LabelOpts(is_show=False),
)
.add_yaxis(
series_name="2017-12-03",
stack="活跃度12-03",
y_axis=ydata("2017-12-03"),
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
datazoom_opts=opts.DataZoomOpts(is_show=True, range_start=0, range_end=100), #缩放条
title_opts=opts.TitleOpts(title="当日每小时活跃度总览", subtitle="2017-11-25至2017-12-03", pos_left="center"), #标题
tooltip_opts=opts.TooltipOpts(trigger="axis"), #提示线
legend_opts=opts.LegendOpts( #标签
orient='vertical',
pos_right="right"
),
yaxis_opts=opts.AxisOpts( #纵坐标相关
name='活跃人数',
splitline_opts=opts.SplitLineOpts(is_show=True)
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False), #横坐标相关
)
.render("当日每小时活跃度总览.html")
)
Tips:作图时有个小坑需注意:每一个纵坐标在赋值时,stack这个变量不能令成一样的,如果是一样的输出结果的纵坐标刻度就是9天数据的和,和数据值会对不上。
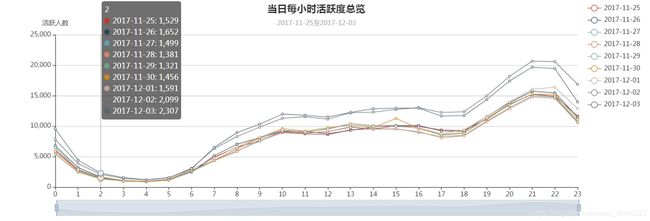
输出结果如下图所示:
转化率
成交转化率
成交转化率定义为成交用户数除以UV。
由UV定义,这里的成交转化率也是单日成交转化率。
第一步,要得到一个包含每日成交量的列表,类似于每日PV的获取,方法如下,将新列表命名为"buy_number":
#每日成交数
everyday_buy = data.groupby(['Dates','BehaviorType']).count()
i = 0 #用于定位到提取数字的位置
buy_number = [] #准备好空列表
while i < 33: #最后一天的定位是32,此处条件大于32小于36即可
buy_number.append(everyday_buy['UserID'][i]) #将目标数更新到列表中
i += 4
buy_number #输出结果
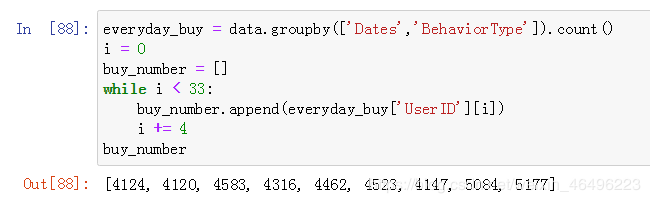
每日成交量结果如下图:
第二步,因为在求UV指标时已经得到了每日指标表格"table_uv",因此只要将每天对应的成交量和UV值相除,也就是“buy_number”和“table_uv”中按顺序对应的数字相除,就是每日成交率了。代码如下:
#每日成交率
i = 0 #计数
turnover_ratio = [] #准备好空列表
for num in buy_number:
tr = round(num/table_uv[i],4) #成交率公式,round函数保留4位有效数字
turnover_ratio.append(tr) #将结果更新到列表
i += 1
turnover_ratio #输出结果
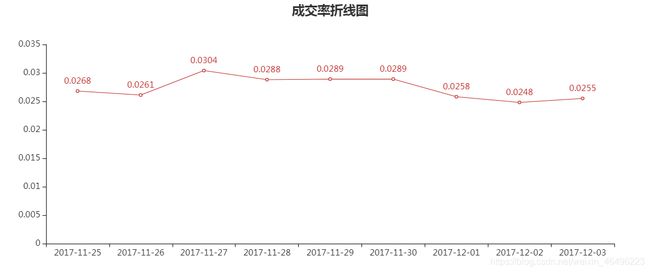
成交转化率最后结果如下:

画成折线图:
#成交率折线图
from pyecharts.charts import Line
(
Line(init_opts=opts.InitOpts(width="1000px", height="400px"))
.add_xaxis(date_list)
.add_yaxis("成交转化率", turnover_ratio)
.set_global_opts(
title_opts=opts.TitleOpts(title="成交转化率折线图", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False),
)
.render("成交转化率折线图.html")
)
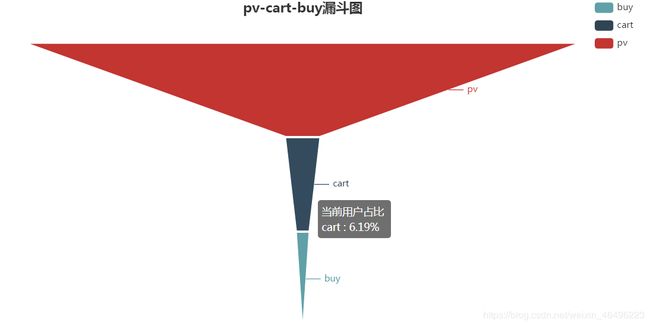
pv-cart-buy
统计口径为2017年11月25日至2017年12月3日,计算这9天内总的转化情况。
#pv-cart-buy转化率
"""建立一个转化率字典dic_conv,其中有些项是空的,随后要填充数据进去"""
dic_conv = {
'Step':['pv','cart','buy'],
'Num':[],
'Conv':[],
'Conv_total':[]
}
"""计算每一步的数据量"""
pv_num = data[data['BehaviorType']=='pv']['UserID'].count()
cart_num = data[data['BehaviorType']=='cart']['UserID'].count()
buy_num = data[data['BehaviorType']=='buy']['UserID'].count()
"""计算转化率"""
pv2pv = round((pv_num/pv_num),4)
pv2cart = round((cart_num/pv_num),4)
cart2buy = round((buy_num/cart_num),4)
pv2buy = round((buy_num/pv_num),4)
"""更新table_conv中的每项数据'Num'列"""
dic_conv['Num'].append(pv_num)
dic_conv['Num'].append(cart_num)
dic_conv['Num'].append(buy_num)
"""更新table_conv中的每步与上一步的转化率'Conv'列"""
dic_conv['Conv'].append(pv2pv)
dic_conv['Conv'].append(pv2cart)
dic_conv['Conv'].append(cart2buy)
"""更新table_conv中的截至每步的总转化率'Conv_total'列"""
dic_conv['Conv_total'].append(pv2pv)
dic_conv['Conv_total'].append(pv2cart)
dic_conv['Conv_total'].append(pv2buy)
pd.DataFrame(dic_conv) #将结果转化为DaraFrame格式,并输出结果

绘制漏斗图
#pv-cart-buy漏斗图
x_data = dic_conv2['Step']
y_data = round((pd.DataFrame(dic_conv2)['Conv_total']*100),3).tolist()
data_funnel_2 = [[x_data[i], y_data[i]] for i in range(len(x_data))]
(
Funnel()
.add(
series_name="当前用户占比",
data_pair=data_funnel_2,
gap=2,
tooltip_opts=opts.TooltipOpts(
trigger="item",
formatter="{a}
{b} : {c}%"
),
label_opts=opts.LabelOpts(
is_show=True,
position="outside"
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="pv-cart-buy漏斗图", pos_left="center"),
legend_opts=opts.LegendOpts(
orient='vertical',
pos_right="right"
),
)
.render("pv-cart-buy漏斗图.html")
)
pv-fav-buy
统计口径为2017年11月25日至2017年12月3日,计算这9天内总的转化情况。
#pv-fav-buy转化率
"""建立一个转化率字典dic_conv,其中有些项是空的,随后要填充数据进去"""
dic_conv = {
'Step':['pv','fav','buy'],
'Num':[],
'Conv':[],
'Conv_total':[]
}
"""计算每一步的数据量"""
pv_num = data[data['BehaviorType']=='pv']['UserID'].count()
fav_num = data[data['BehaviorType']=='fav']['UserID'].count()
buy_num = data[data['BehaviorType']=='buy']['UserID'].count()
"""计算转化率"""
pv2pv = round((pv_num/pv_num),4)
pv2fav = round((fav_num/pv_num),4)
fav2buy = round((buy_num/fav_num),4)
pv2buy = round((buy_num/pv_num),4)
"""更新table_conv中的每项数据'Num'列"""
dic_conv['Num'].append(pv_num)
dic_conv['Num'].append(fav_num)
dic_conv['Num'].append(buy_num)
"""更新table_conv中的每步与上一步的转化率'Conv'列"""
dic_conv['Conv'].append(pv2pv)
dic_conv['Conv'].append(pv2fav)
dic_conv['Conv'].append(fav2buy)
"""更新table_conv中的截至每步的总转化率'Conv_total'列"""
dic_conv['Conv_total'].append(pv2pv)
dic_conv['Conv_total'].append(pv2fav)
dic_conv['Conv_total'].append(pv2buy)
pd.DataFrame(dic_conv) #将结果转化为DaraFrame格式,并输出结果
结果如下图所示:

绘制漏斗图
#pv-fav-buy漏斗图
from pyecharts.charts import Funnel
x_data = dic_conv1['Step']
y_data = round((pd.DataFrame(dic_conv1)['Conv_total']*100),3).tolist()
data_funnel_1 = [[x_data[i], y_data[i]] for i in range(len(x_data))]
(
Funnel()
.add(
series_name="当前用户占比",
data_pair=data_funnel_1,
gap=2,
tooltip_opts=opts.TooltipOpts(
trigger="item",
formatter="{a}
{b} : {c}%"
),
label_opts=opts.LabelOpts(
is_show=True,
position="outside"
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="pv-fav-buy漏斗图", pos_left="center"),
legend_opts=opts.LegendOpts(
orient='vertical',
pos_right="right"
),
)
.render("pv-fav-buy漏斗图.html")
)

2.用户
用户行为
复购率
复购率定义为某段时期内有两次及以上购买行为的用户数占总成交用户数的比重。
单日复购率
此处统计口径是2017年11月25日至2017年12月3日这9天内,当天消费一次以上的用户数量。思路如下:
第一步,在数据中将消费行为buy筛选出来:
data[data['BehaviorType']=='buy'] #筛选buy
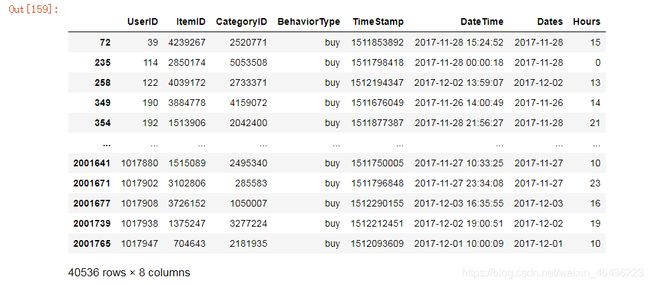
由上表可知总共产生消费行为40,536次。
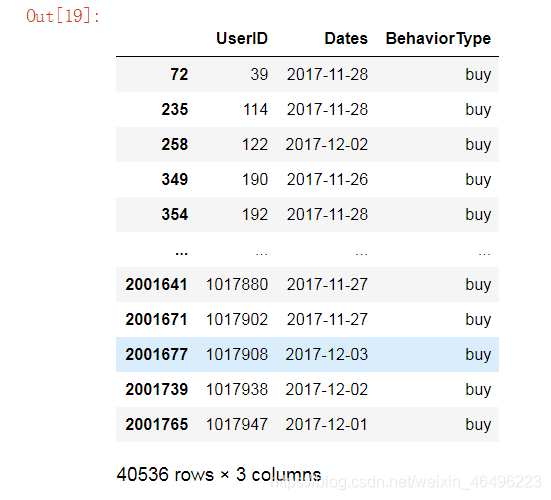
第二步,只将UserID、BehaviorType和Dates这三列提取出来,过滤掉其他无关信息。
在上一步基础上代码更新至:
temp = data[data['BehaviorType']=='buy'] #筛选buy
temp1 = temp[{'UserID','BehaviorType','Dates'}] #过滤掉无关信息
temp1 #输出
结果如下图所示:
第三步,然后对表temp1进行透视,透视行选择UserID,透视列选择Dates,然后对BehaviorType也就是buy做计数count,生成透视表"pivoted_table"。
在上一步基础上代码更新至:
temp = data[data['BehaviorType']=='buy'] #筛选buy
temp1 = temp[{'UserID','BehaviorType','Dates'}] #过滤掉无关信息
pivoted_table = temp1.pivot_table(index='UserID', columns= 'Dates', values='BehaviorType', aggfunc='count') #对temp1透视,记作pivoted_table
pivoted_table #输出结果
参数解释:
- data.pivot_table(····)表示对data表进行透视
- index = ‘<透视表的行>’
- columns = ‘<透视表的列>’
- values = ‘<选择那个参数进行计算>’
- aggfunc = ‘<计算的规则>’
结果如下图所示:
(由下图可知共有38,783名用户产生消费行为,他们之中有些人消费了一次以上)

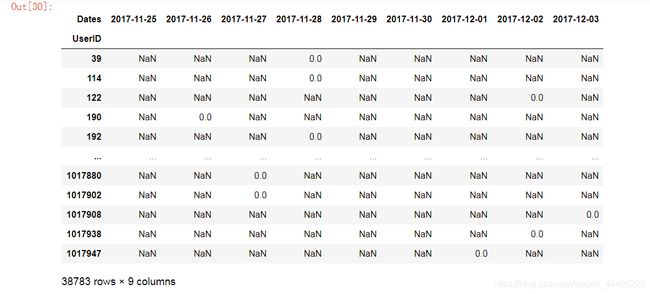
第四步,从透视表上可以发现,NaN表示用户在对应日期没有消费,非零数表示用户在对应日期产生的消费行为次数,可以看见大多数用户都是1次。现在要进一步筛选出这些用户中产生1次以上消费行为的。因此就要使用隐函数进行逻辑判断,将表内值大于1的数改为1,将值等于1的数改为0,NaN值保持NaN值不变。
在上一步基础上代码更新至:
temp = data[data['BehaviorType']=='buy'] #筛选buy
temp1 = temp[{'UserID','BehaviorType','Dates'}] #过滤掉无关信息
pivoted_table = data2.pivot_table(index='UserID', columns= 'Dates', values='BehaviorType', aggfunc='count') #对temp1透视,记作pivoted_table
temp2 = pivoted_table.applymap(lambda x :1 if x>1 else 0 if x==1 else np.NaN) #对表中值做逻辑修改
temp2 #输出结果
结果如下图所示:
第五步,因为NaN值在运算时会被忽略,所以temp2.sum()将表示每天消费1次以上的人数,temp2.count()将表示每天消费的人数。
temp2.sum()

temp2.count()
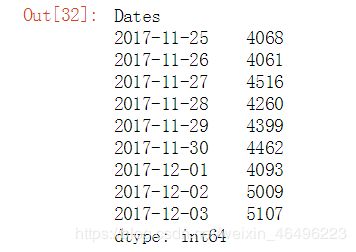
第六步,结果
简单的将temp2.sum()与temp2.count()相除,皆可以得到每日复购率:
rebuy_ratio = round(temp2.sum()/temp2.count(),3) #保留三位有效数字
rebuy_ratio
每日复购率结果如下图所示:

完整代码如下:
#每日复购率
temp = data[data['BehaviorType']=='buy']
temp1 = temp[{'UserID','BehaviorType','Dates'}]
pivoted_table = temp1.pivot_table(index='UserID', columns= 'Dates', values='BehaviorType', aggfunc='count')
temp2 = pivoted_table.applymap(lambda x :1 if x>1 else 0 if x==1 else np.NaN)
rebuy_ratio = round(temp2.sum()/temp2.count(),3)
rebuy_ratio
画成折线图:
#每日复购率折线图
from pyecharts.charts import Line
(
Line(init_opts=opts.InitOpts(width="1000px", height="400px"))
.add_xaxis(date_list)
.add_yaxis("复购率", rebuy_ratio)
.set_global_opts(
title_opts=opts.TitleOpts(title="每日复购率折线图", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False),
)
.render("每日复购率折线图.html")
)

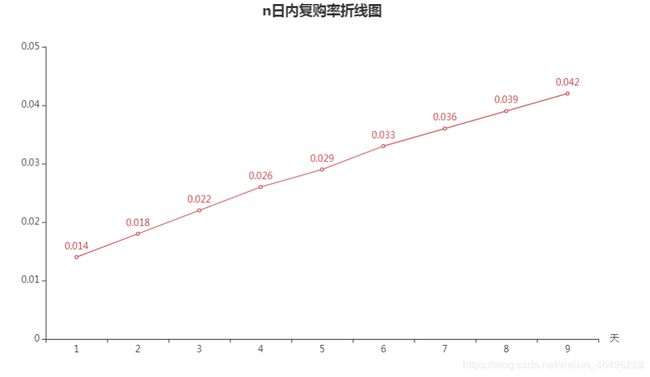
n日内复购率
显然,刚才求的单日复购率就是n=1时的特殊情况。
首先回到求单日复购率的第三步,观察该透视表,现在想要求得n日内复购率,就需要考察每个用户在n日内有没有消费1次以上,计算求单日复购率时我们在关注列,现在应该关注行。示意图如下:

统计口径是在n日内,消费1次以上用户占n日内有消费用户的比例(其中在一天内消费1次以上也要算作是n日内消费1次以上,n可以等于1),由于“n日内”可以划出多个区间,所以还要对结果取平均值。
第一步,新增一辅助列"X",记录每个人n日内消费次数,其值就是n个日期区间内的数值求和。为方便计算求和,先将透视表中的NaN值替换为0。
temp = pivoted_table.fillna(0) #将NaN替换成0
第二步,假设n=4,就需要计算出11月25至11月28日、11月26至11月29日、11月27至11月30日、11月28至12月1日、11月29至12月2日、11月30至12月3日这6个区间上复购率,然后求平均值。
具体求复购率的思想和单日复购率类似,对X列结果做逻辑替换,大于1的数换成1,等于1的数换成0,等于0的数换成NaN,这样对X计数(count)就是有消费行为的人数,对X求和(sum)就是消费大于1次的人数。二者之比就是复购率。
为在一个代码里实现所有的区间取值情况,要使用while循环。
首先实现取遍所有区间的循环:
n_rebuy = [] #具体n值下的各区间复购率列表
i = 0 #区间起始位置
while i+n <= 9:
temp['X'] = temp.iloc[:, i:i+n].sum(axis=1) #区间求和
temp['X'] = temp['X'].apply(lambda x: 1 if x>1 else 0 if x==1 else np.NaN) #逻辑替换
num = round(temp['X'].sum()/temp['X'].count(),3) #复购率,保留3位有效数字
n_rebuy.append(num) #将结果存进列表
i += 1
第三步,对于一个具体的n值,n日内复购率就是第二步求得的列表"n_rebuy"中所有值的平均值。
为在一个代码里实现所有的n取值情况,还要在第二步基础上再套一个while循环。最后完整代码如下:
# n日内复购率
temp = pivoted_table.fillna(0) #将NaN替换成0
rebuy_ratio_n = [] #最后结果列表
n = 1 #n起始数字
while n <= 9: #n循环条件
n_rebuy = []
i = 0
while i+n <= 9: #区间循环条件
temp['X'] = temp.iloc[:, i:i+n].sum(axis=1)
temp['X'] = temp['X'].apply(lambda x: 1 if x>1 else 0 if x==1 else np.NaN)
num = round(temp['X'].sum()/temp['X'].count(),3)
n_rebuy.append(num)
i += 1
n_ratio = round(np.mean(n_rebuy),3)
rebuy_ratio_n.append(n_ratio)
n += 1
rebuy_ratio_n
![]()
画成折线图:
# n日内复购率折线图
from pyecharts.charts import Line
(
Line()
.add_xaxis(['1','2','3','4','5','6','7','8','9']) #注意,不能是数字
.add_yaxis("复购率", rebuy_ratio_n)
.set_global_opts(
title_opts=opts.TitleOpts(title="n日内复购率折线图", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(name='天',type_="category", boundary_gap=True)
)
.render("n日内复购率折线图.html")
)
各时段上的行为分布
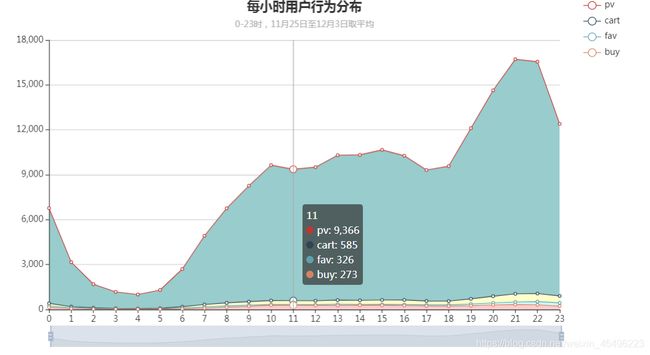
统计口径为以每小时为单位,计算整个日期范围上每个时段上的四种用户行为的数量,对结果求平均值。将结果生成一张面积图。
#各时段行为分布,面积图
from pyecharts.charts import Line
"""定义一个函数,后面用函数获取纵坐标Y值"""
def bt_by_hour_list(type):
temp = (round((data[data['BehaviorType'] == type]).groupby(['Hours']).count()/9)
)['UserID'].tolist()
return temp
x_data = [] #横坐标
i = 0
while i < 24:
x_data.append(i)
i += 1
"""作图"""
(
Line()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="pv",
stack="pv",
y_axis=bt_by_hour_list('pv'),
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(opacity=1, color='#99CCCC'),
)
.add_yaxis(
series_name="cart",
stack="cart",
y_axis=bt_by_hour_list('cart'),
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(opacity=1, color='#FFFFCC'),
)
.add_yaxis(
series_name="fav",
stack="fav",
y_axis=bt_by_hour_list('fav'),
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(opacity=1, color='#CCFFFF'),
)
.add_yaxis(
series_name="buy",
stack="buy",
y_axis=bt_by_hour_list('buy'),
symbol="emptyCircle",
is_symbol_show=True,
label_opts=opts.LabelOpts(is_show=False),
areastyle_opts=opts.AreaStyleOpts(opacity=1, color='#FFCCCC'),
)
.set_global_opts(
datazoom_opts=opts.DataZoomOpts(is_show=True, range_start=0, range_end=100), #缩放条
title_opts=opts.TitleOpts(title="每小时用户行为分布", subtitle="0-23时,11月25日至12月3日取平均", pos_left="center"), #标题
tooltip_opts=opts.TooltipOpts(trigger="axis"), #提示线
legend_opts=opts.LegendOpts( #标签
orient='vertical',
pos_right="right"
),
yaxis_opts=opts.AxisOpts( #纵坐标
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
.render("每小时用户行为分布.html")
)
运行结果如下图所示:
用户质量
消费贡献率
统计口径为将消费的用户按消费次数升序排序,计算用户消费贡献的累积情况,得到前多少名用户产生了百分之多少消费量这样的数据。
第一步,得到计算所需的表格。大概思路是在源数据中提取出买家,计算每个买家消费了多少次,然后将买家按消费次数排序,并用一列表示消费数额的累加值。
temp = data[data['BehaviorType'] == 'buy'] #筛选出买家
temp1 = temp[{'UserID','BehaviorType'}] #只选出UserID和BehaviorType两列
temp2 = temp1.groupby('UserID').BehaviorType.count().sort_values().reset_index() #按用户分组,计算每个用户消费次数,并排序,重置索引序号
temp2['sum'] = temp2.BehaviorType.cumsum() #cumsum函数,逐行计算并累积
temp2
这一步结果如下:

第二步,计算贡献率,即将sum列的数字依次除以总数,即最后一个数40,536。
在第一步基础上代码更新如下,并直接画出曲线图:
#消费贡献率线图
from pyecharts.charts import Line
temp = data[data['BehaviorType'] == 'buy'] #筛选出买家
temp1 = temp[{'UserID','BehaviorType'}] #只选出UserID和BehaviorType两列
temp2 = temp1.groupby('UserID').BehaviorType.count().sort_values().reset_index() #按用户分组,计算每个用户消费次数,并排序,重置索引序号
temp2['sum'] = temp2.BehaviorType.cumsum() #cumsum函数,逐行计算并累积
a_list = temp2['sum'].tolist() #提取出sum,分子列表
b = temp2['sum'].max() #分母
prop = [] #纵坐标
for a in a_list:
result = round(a/b, 5)
prop.append(result)
i = 1
x_data = [] #横坐标
while i < 38784:
x_data.append(i)
i += 1
"""作图"""
(
Line(init_opts=opts.InitOpts(width="1200px", height="400px"))
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name="累积贡献率",
y_axis=prop,
label_opts=opts.LabelOpts(is_show=True)
)
.set_global_opts(
datazoom_opts=opts.DataZoomOpts(is_show=True, range_start=0, range_end=100), #缩放条
title_opts=opts.TitleOpts(title="用户累积消费贡献率", pos_left="center"), #标题
tooltip_opts=opts.TooltipOpts(trigger="axis",axis_pointer_type="cross"), #提示线
legend_opts=opts.LegendOpts(is_show=False),
yaxis_opts=opts.AxisOpts(
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
xaxis_opts=opts.AxisOpts(boundary_gap=False),
)
.render("用户累积消费贡献率.html")
)
结果如下图所示:

注:这个图我研究了很久还是没能调整出我想要的样子,下面附一张用plot函数绘图的结果。
#消费贡献率,plot作图
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这两行为了能在图上正确显示中文字符
temp = data[data['BehaviorType'] == 'buy'] #筛选出买家
temp1 = temp[{'UserID','BehaviorType'}] #只选出UserID和BehaviorType两列
temp2 = temp1.groupby('UserID').BehaviorType.count().sort_values().reset_index() #按用户分组,计算每个用户消费次数,并排序,重置索引序号
temp2['sum'] = temp2.BehaviorType.cumsum() #cumsum函数,逐行计算并累积
a_list = temp2['sum'].tolist() #提取出sum,分子列表
b = temp2['sum'].max() #分母
prop = [] #纵坐标
for a in a_list:
result = round(a/b, 5)
prop.append(result)
"""作图"""
plt.title('消费贡献率')
plt.xlabel(u'累计人数')
plt.ylabel(u'累计消费贡献')
plt.plot(pd.DataFrame(prop))
plt.show()

消费前十
统计口径为消费次数前十的用户。
#消费前十
temp = data[data['BehaviorType'] == 'buy'] #筛选出买家
temp1 = temp[{'UserID','BehaviorType'}] #只选出UserID和BehaviorType两列
top_user = temp1.groupby('UserID').BehaviorType.count().sort_values(ascending=False).reset_index() #按用户分组,计算每个用户消费次数,降序排序,重置索引序号
top_user.head(10) #输出前十
结果如下图所示:
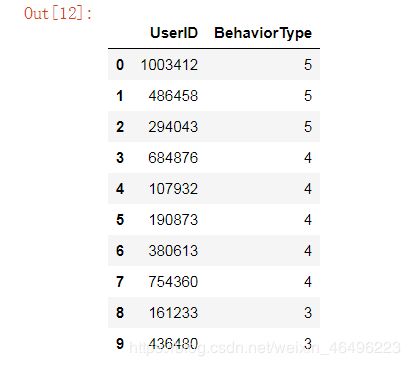
做成柱状图:
#消费前十柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(((top_user.head(10))['UserID']).tolist())
.add_yaxis("用户",
((top_user.head(10))['BehaviorType']).tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts=opts.TitleOpts(title="消费前十用户", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("消费前十柱状图.html")
)

做成词云图:
#消费前十词云图
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
data_topuser = [
(1003412,5),
(486458,5),
(294043,5),
(684876,4),
(107932,4),
(190873,4),
(380613,4),
(754360,4),
(161233,3),
(436480,3)
]
(
WordCloud()
.add(series_name="用户", data_pair=data_topuser)
.set_global_opts(
title_opts=opts.TitleOpts(
title="消费前十用户",
pos_left='center'
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("消费前十词云图.html")
)

用户评分(RMF)
参考通用的RFM 模型,模型中R指最近一次购买时间,M值消费金额,F指购买频率。由于本次数据集中没有消费金额这一项,故只根据R、F两个维度作用户划分。
此处设定评分标准如下:
| R(最近一次消费时间) | F(消费频率) |
|---|---|
| 12月2至12月3日:4分 | 5次:5分 |
| 11月30至12月1日:3分 | 4次:4分 |
| 11月28至11月29日:2分 | 3次:3分 |
| 11月25至11月27日:1分 | 2次:2分 |
| 无消费:0分 | 1次:1分 |
| 0次:0分 |
计算F维度:
F值计算比较简单,只需对消费行为做变换,将’buy’换成1,其他三个都换成0,然后按用户分组后计算求和就可以了。
# RMF F维度
temp = data[{'UserID','BehaviorType'}] #筛选需要的列
temp1 = temp.replace(['pv','cart','fav','buy'], [0,0,0,1]) #替换值
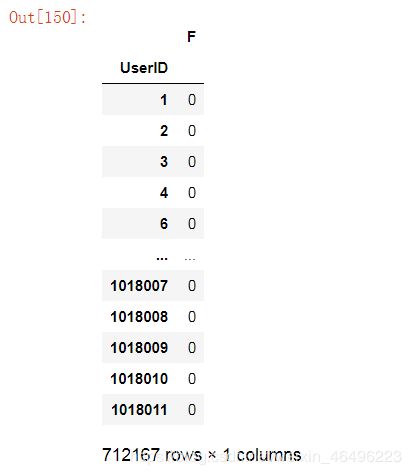
rmf_F = temp1.groupby('UserID').sum() #计算F值
rmf_F = rmf_F.rename(columns = {'BehaviorType':'F'}) #对列重命名
rmf_F
计算R维度:
对所有用户统计,其中有消费行为的用户根据消费时期所在区间打分,未消费用户直接0分。我的思路是分两步得到结果:
第一步:先对消费行为做变换,将’buy’换成1,其他三个都换成0。同时只选取需要用到的列。
temp = data.replace(['pv','cart','fav','buy'], [0,0,0,1]) #替换值
temp1 = temp[{'UserID','BehaviorType','Dates'}]
temp1

第二步:将日期按打分标准做替换,手动输入替换条件。然后将Dates列和BehaviorType两列的对应值相乘,乘积就是R维度的得分。
temp2 = temp1.replace(date_list, [1,1,1,2,2,3,3,4,4])
temp2['R'] = temp2.apply(lambda x: x['Dates']*x['BehaviorType'], axis = 1) #乘积运算
temp2

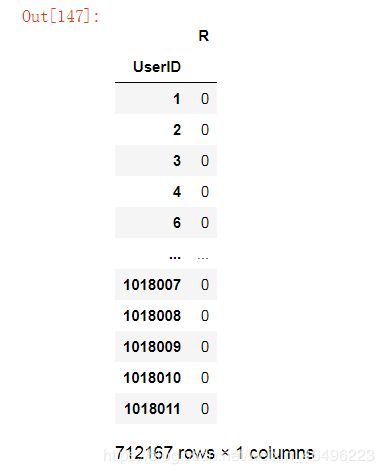
第三步:将上面的结果只选取UserID和R两列,然后按用户分组,求每组内最大值,结果就是每一个用户的R维度得分。
(temp2[{'UserID', 'R'}]).groupby('UserID').max()
R维度完整代码如下:
# RMF R维度
temp = data.replace(['pv','cart','fav','buy'], [0,0,0,1]) #替换值
temp1 = temp[{'UserID','BehaviorType','Dates'}]
temp2 = temp1.replace(date_list, [1,1,1,2,2,3,3,4,4])
temp2['R'] = temp2.apply(lambda x: x['Dates']*x['BehaviorType'], axis = 1) #乘积运算
rmf_R = (temp2[{'UserID', 'R'}]).groupby('UserID').max()
rmf_R
将F值作为横坐标,R值作为纵坐标,组成一组二维坐标:
# RMF二维坐标
r_list = rmf_R['R'].tolist() #纵坐标列表
f_list = rmf_F['F'].tolist() #横坐标列表
fr_data = [] #二维坐标列表
"""先添加横坐标"""
for f in f_list:
list_in = []
list_in.append(f)
fr_data.append(list_in)
"""再添加纵坐标"""
i = 0
for r in r_list:
fr_data[i].append(r)
i += 1
fr_data #输出结果
画气泡图:
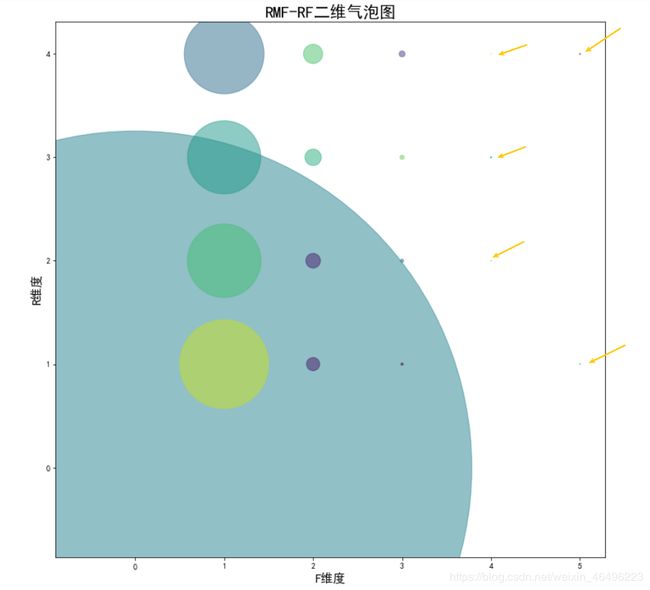
对于这个结果,最好是能用气泡图的形式进行展示,即根据二维坐标画出一个点后,再用这个点的大小表示有多少个值聚集在这里。就我实践而言,用pyrcharts暂时没找到作图方法,用matplotlib可以实现。
matplotlib中画气泡图需要三个变量,分别是横坐标、纵坐标和大小参数。首先需要将全部坐标集fr_data中的坐标去重,去重后的坐标集就是要在图上描绘的点集,横纵坐标的变量值都可以从中提取出来。然后计算各个坐标在fr_data中的数量,这个数量就是对应坐标点的大小参数。
# RMF气泡图
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这两行为了能在图上正确显示中文字符
"""坐标去重"""
sca_data = [] #去重后坐标列表
for item in fr_data:
if item not in sca_data:
sca_data.append(item)
"""三个作图变量"""
x_data = []
for i in sca_data:
x_data.append(i[0])
y_data = []
for i in sca_data:
y_data.append(i[1])
size_data = []
for sca in sca_data:
num = fr_data.count(sca)
size_data.append(num)
"""作图"""
colors = np.random.rand(len(x_data)) #随机上色
plt.figure(figsize=(12,12)) #图像大小
plt.scatter(x_data, y_data, size_data, colors, alpha=0.5) #赋值,alpha是透明度
plt.title('RMF-RF二维气泡图',fontsize=20)
plt.xlabel('F维度',fontsize=15)
plt.ylabel('R维度',fontsize=15)
plt.show()
(有些点太小,图中用箭头标记出来了)
再说一下用pyecharts画的散点图,虽然暂时没找到方法直观展示第三维度,但是可以从图上清楚看到用户评分都分布在哪些点上。
# RMF散点图,pyecharts
from pyecharts.charts import Scatter
"""坐标去重"""
sca_data = [] #去重后坐标列表
for item in fr_data:
if item not in sca_data:
sca_data.append(item)
"""作图"""
x_data = [d[0] for d in sca_data]
y_data = [d[1] for d in sca_data]
(
Scatter()
.add_xaxis(xaxis_data=x_data)
.add_yaxis(
series_name = '',
y_axis=y_data,
label_opts=opts.LabelOpts(is_show=False),
)
.set_series_opts()
.set_global_opts(
title_opts=opts.TitleOpts(title="RMF_RF二维散点图", pos_left='center'),
xaxis_opts=opts.AxisOpts(
name='F值',
type_="value",
splitline_opts=opts.SplitLineOpts(is_show=True)
),
yaxis_opts=opts.AxisOpts(
name='R值',
type_="value",
axistick_opts=opts.AxisTickOpts(is_show=True),
splitline_opts=opts.SplitLineOpts(is_show=True),
),
)
.render("RMF散点图.html")
)

3.商品
浏览、加购、收藏、购买前十
(1)浏览前十
统计口径为ItemID列下浏览(pv)排名前十的产品。
#浏览前十
temp = data[data['BehaviorType'] == 'pv']
temp1 = temp[{'ItemID','BehaviorType'}]
top_pv = temp1.groupby('ItemID').BehaviorType.count().sort_values(ascending=False).reset_index()
top_pv.head(10)

做成柱状图:
#浏览前十柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(((top_pv.head(10))['ItemID']).tolist())
.add_yaxis("用户",
((top_pv.head(10))['BehaviorType']).tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts=opts.TitleOpts(title="浏览量前十产品", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("浏览前十柱状图.html")
)

做成词云图:
#浏览前十词云图
from pyecharts.charts import WordCloud
data_toppv = [
(812879,578),
(3845720,517),
(2331370,406),
(138964,383),
(2032668,375),
(1535294,362),
(2338453,361),
(4211339,353),
(3031354,345),
(59883,342)
]
(
WordCloud()
.add(series_name="产品", data_pair=data_toppv)
.set_global_opts(
title_opts=opts.TitleOpts(
title="浏览量前十产品",
pos_left='center'
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("浏览前十词云图.html")
)

(2)加购前十
统计口径为ItemID列下加购(cart)排名前十的产品。
#加购前十
#加购前十
temp = data[data['BehaviorType'] == 'cart']
temp1 = temp[{'ItemID','BehaviorType'}]
top_cart = temp1.groupby('ItemID').BehaviorType.count().sort_values(ascending=False).reset_index()
top_cart.head(10)

做成柱状图:
#加购前十柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(((top_cart.head(10))['ItemID']).tolist())
.add_yaxis("用户",
((top_cart.head(10))['BehaviorType']).tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts=opts.TitleOpts(title="加购量前十产品", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("加购前十柱状图.html")
)
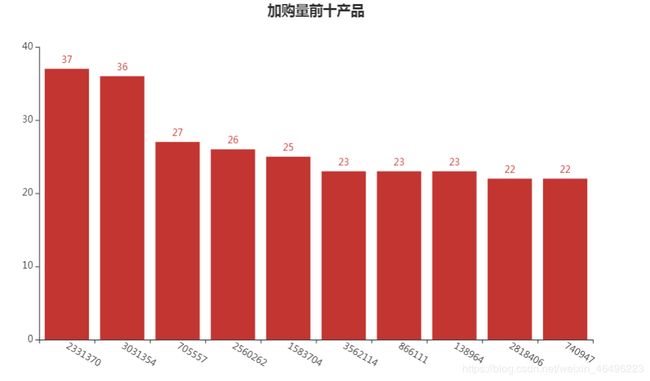
做成词云图:
#加购前十词云图
from pyecharts.charts import WordCloud
data_topcart = [
(2331370,37),
(3031354,36),
(705557,27),
(2560262,26),
(1583704,25),
(3562114,23),
(866111,23),
(138964,23),
(2818406,22),
(740947,22)
]
(
WordCloud()
.add(series_name="产品", data_pair=data_topcart)
.set_global_opts(
title_opts=opts.TitleOpts(
title="加购量前十产品",
pos_left='center'
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("加购前十词云图.html")
)

(3)收藏前十
统计口径为ItemID列下收藏(fav)排名前十的产品。
#收藏前十
temp = data[data['BehaviorType'] == 'fav']
temp1 = temp[{'ItemID','BehaviorType'}]
top_fav = temp1.groupby('ItemID').BehaviorType.count().sort_values(ascending=False).reset_index()
top_fav.head(10)
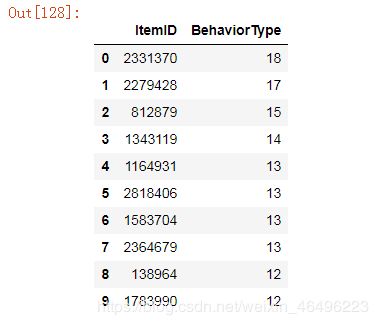
做成柱状图:
#收藏前十柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(((top_fav.head(10))['ItemID']).tolist())
.add_yaxis("用户",
((top_fav.head(10))['BehaviorType']).tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts=opts.TitleOpts(title="收藏量前十产品", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("收藏前十柱状图.html")
)

做成词云图:
#收藏前十词云图
from pyecharts.charts import WordCloud
data_topfav = [
(2331370,18),
(2279426,17),
(812879,15),
(1343119,14),
(1164931,13),
(2818406,13),
(1583704,13),
(2364679,13),
(138964,12),
(1783990,12)
]
(
WordCloud()
.add(series_name="产品", data_pair=data_topfav)
.set_global_opts(
title_opts=opts.TitleOpts(
title="收藏量前十产品",
pos_left='center'
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("收藏前十词云图.html")
)

(4)购买前十
统计口径为ItemID列下销量(buy)排名前十的产品。
#购买前十
temp = data[data['BehaviorType'] == 'buy']
temp1 = temp[{'ItemID','BehaviorType'}]
top_buy = temp1.groupby('ItemID').BehaviorType.count().sort_values(ascending=False).reset_index()
top_buy.head(10)
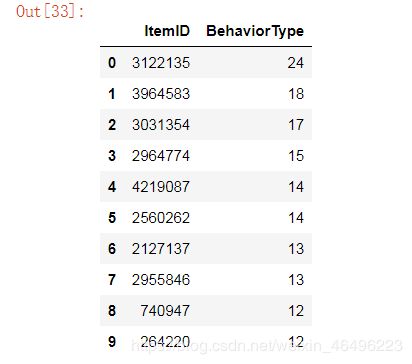
做成柱状图:
#购买前十柱状图
from pyecharts.charts import Bar
(
Bar()
.add_xaxis(((top_buy.head(10))['ItemID']).tolist())
.add_yaxis("用户",
((top_buy.head(10))['BehaviorType']).tolist()
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-30)),
title_opts=opts.TitleOpts(title="购买量前十产品", pos_left='center'),
legend_opts=opts.LegendOpts(is_show=False)
)
.render("购买前十柱状图.html")
)
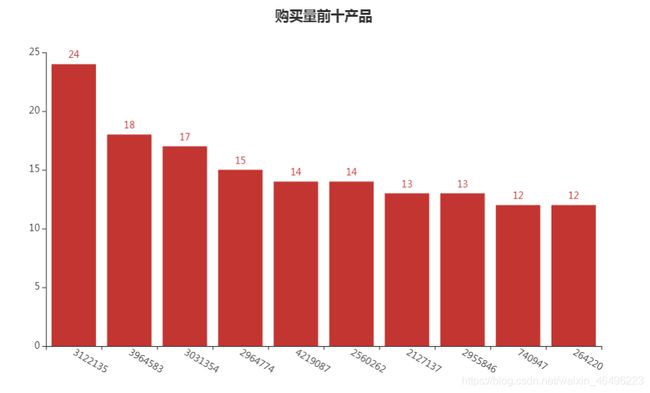
做成词云图:
#购买前十词云图
from pyecharts.charts import WordCloud
data_topbuy = [
(3122135,24),
(3964583,18),
(3031354,17),
(2964774,15),
(4219087,14),
(2560262,14),
(2127137,13),
(2955846,13),
(740947,12),
(264220,12)
]
(
WordCloud()
.add(series_name="产品", data_pair=data_topbuy)
.set_global_opts(
title_opts=opts.TitleOpts(
title="购买量前十产品",
pos_left='center'
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("购买前十词云图.html")
)

浏览–购买转化比
不同于之前分析的转化率,那个是以全站的角度来看的,展示的是全站商品被浏览后有百分之多少的商品会进入更深层次的消费行为。而这里分析的是具体商品,展示一个具体商品在被购买前会被浏览几次。
第一步,将Behaviortype中的fav和cart过滤掉,然后进行列表透视:
temp = data[data['BehaviorType'] != 'fav'] #过滤fav
temp1 = temp[temp['BehaviorType'] != 'cart'] #过滤cart
temp2 = temp1.pivot_table(index='ItemID', columns= 'BehaviorType', values='Dates', aggfunc='count') #透视
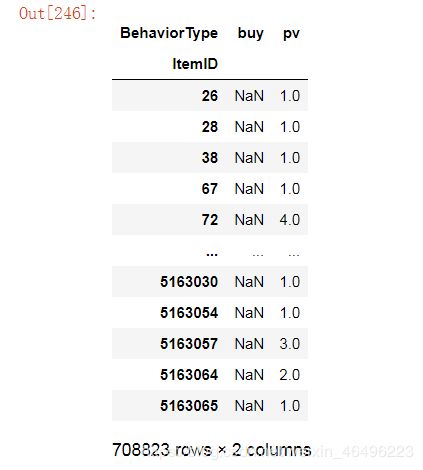
第二步,用透视表buy列除以pv列,结果就是对应商品的转化比了。上一步代码更新如下:
#浏览-购买转化比
temp = data[data['BehaviorType'] != 'fav'] #过滤fav
temp1 = temp[temp['BehaviorType'] != 'cart'] #过滤cart
temp2 = temp1.pivot_table(index='ItemID', columns= 'BehaviorType', values='Dates', aggfunc='count') #透视
temp2['X'] = temp2.apply(lambda x: x['buy']/x['pv'], axis=1) #求转化比,存在辅助列X中
item_p2b = pd.DataFrame(temp2.X).sort_values(by='X',ascending=False) #对X列降序排序
item_p2b
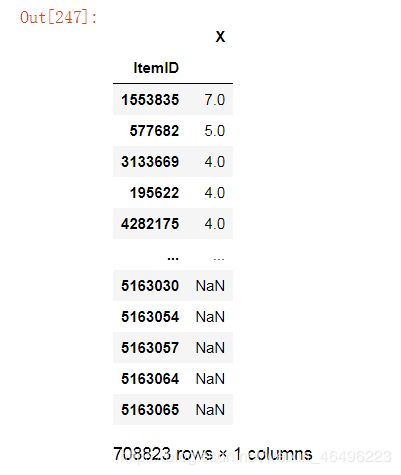
显然,这里求出具体数值结果的是哪些同时有buy和pv记录的商品。
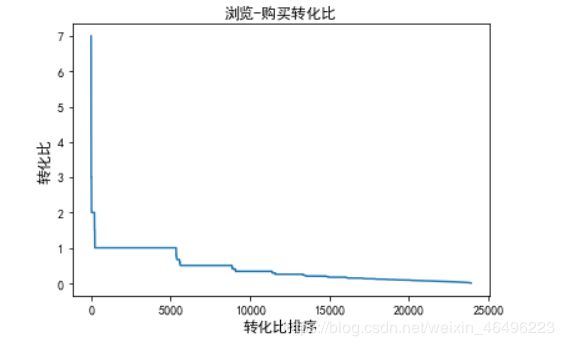
因pyecharts作图效果不理想,这里用plot函数作图:
#浏览-购买转化比图示
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这两行为了能在图上正确显示中文字符
"""作图"""
plt.title('浏览-购买转化比')
plt.xlabel(u'转化比排序',fontsize=12)
plt.ylabel(u'转化比',fontsize=12)
plt.plot((item_p2b.reset_index())['X'])
plt.show()
加购–购买转化比
类似的
#加购-购买转化比
temp = data[data['BehaviorType'] != 'pv'] #过滤pv
temp1 = temp[temp['BehaviorType'] != 'fav'] #过滤fav
temp2 = temp1.pivot_table(index='ItemID', columns= 'BehaviorType', values='Dates', aggfunc='count') #透视
temp2['X'] = temp2.apply(lambda x: x['buy']/x['cart'], axis=1) #求转化比,存在辅助列X中
item_c2b = pd.DataFrame(temp2.X).sort_values(by='X',ascending=False) #对X列降序排序
item_c2b

同样的,这里使用plot函数作图。
#加购-购买转化比图示
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这两行为了能在图上正确显示中文字符
"""作图"""
plt.title('加购-购买转化比')
plt.xlabel(u'转化比排序',fontsize=12)
plt.ylabel(u'转化比',fontsize=12)
plt.plot((item_c2b.reset_index())['X'])
plt.show()

销售量分布
统计口径为具体商品的销售量分布情况。这里的所求其实就是前面计算的销量前十的变量top_buy。

使用plot函数画销量分布示意图:
#销量分布图示
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] #这两行为了能在图上正确显示中文字符
"""作图"""
plt.title('销量分布图示')
plt.xlabel(u'销量排序',fontsize=12)
plt.ylabel(u'销量',fontsize=12)
plt.plot(top_buy['BehaviorType'])
plt.show()

四、分析总结
本次从总量100,150,807条的数据源中随机抽样了2%的数据进行分析,共计2,001,897条样本数据,样本数据构成如下:
| 维度 | 数量 |
|---|---|
| 用户数量 | 712,167 |
| 商品数量 | 746,482 |
| 商品类目数量 | 7,071 |
| 所有行为数量 | 2,001,897 |
在统计过程中,可从得到如下样本数据:
| 指标 | 样本数据 |
|---|---|
| 总浏览量(次) | 1,792,298 |
| 消费用户数(人) | 38,783 |
| 消费总量(次) | 40,536 |
| 卖出的商品(种) | 34,396 |
数据时间跨度为2017年11月25日至12月3日,为期9天。

1、全站日常pv和uv在工作日和周末无显著区别,大型促销活动可引起数据的显著上升,在促销周期预热阶段即可引起30%左右的上涨,随着正式促销日的临近,预计涨幅会进一步加大。
从上图中可以发现,在11月25日至12月1日这个范围内,网站浏览量主要在18-19万区间波动,访问用户主要在15-16万区间波动,数据属于比较稳定。而在12月2日和12月3日这两天浏览量稳定在24万左右,访问用户稳定在20万左右,两个指标均较之前涨幅约30%,涨幅明显。虽然这两天是周末,但考虑到11月25日和11月26日也是周末但两次周末差距明显,所以更大可能是12月2日和12月3日这两天推出了双十二促销的预热活动,全站进入双十二促销周期。如果有后面一段时间的数据,应该能期望看到这两个数据持续处于和12月2日、12月3日相近的水平,甚至继续上涨。
相对的,可以把11月25日至12月1日的数据表现视作网站在无特殊活动时期的情况,可见在平时周末数据和工作日数据并无明显差异。
2、全站活跃用户数在24小时内走势稳定,趋势不受促销活动影响。全体用户使用习惯较为一致。
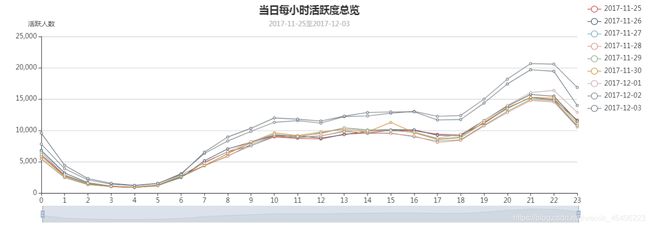
从上图中可以发现,一天24小时内用户的活跃度走势十分稳定,虽然在促销周期内数据值较平时有明显的差别,但数据变化趋势依旧没变。这可以说明网站是否做活动并不会影响到用户日常生活的节奏。可以看出数据走势明显分为三个阶段:
第一阶段为0时到7时,这段时间数据处于低位,呈U形,常识可知大多数用户这段时间在睡觉休息,这也侧面说明某宝的用户绝大部分分布于东八时区,即国内用户占绝大多数。
第二阶段为7时到18时,这段时间数据回升,稳定在一万左右,这段时间可能是工作日上班时间,或者是周末有其他活动和事务,即大多数用户都有事要做,不会大量浏览网站。
第三阶段是18时至24时,这段时间数据明显上升,每小时涨幅大概在20%,且在21时和22时达到峰值,23时起数据下行,说明大多用户还是习惯于在晚上的空闲时间浏览网站。随着时间进入深夜,数据回到第一阶段。
3、宏观来说全站浏览—购买转化率在2.26%,其中用户把商品放进购物车的概率略高于把商品加入收藏,而被加入收藏的商品有更大可能被买下来,即收藏夹里的商品有着相对更高的“含金量”。
全站日常成交率在2%~3%,大型促销活动之前的一段时间成交率会相对较低,不过也不会低于波动区间。
具体来说有55%的售出商品在被购买前经历了1次以上的浏览,30.5%的售出商品是不经过浏览被直接下单的。放进购物车的商品中有53.8%最后以单件购买的形式成交。
有88.4%的商品的销量是1,高销量商品只占少数,且销量与低量商品有显著差距,高销量商品之间的销量差距倒不是很明显。
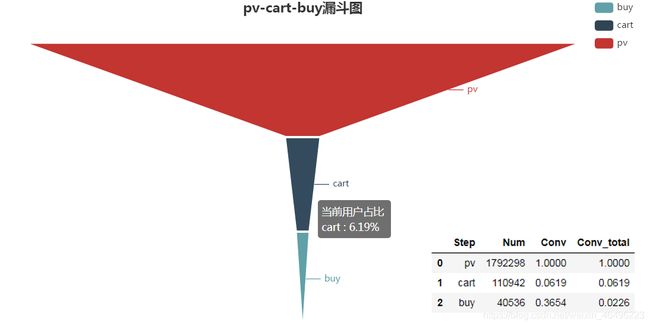
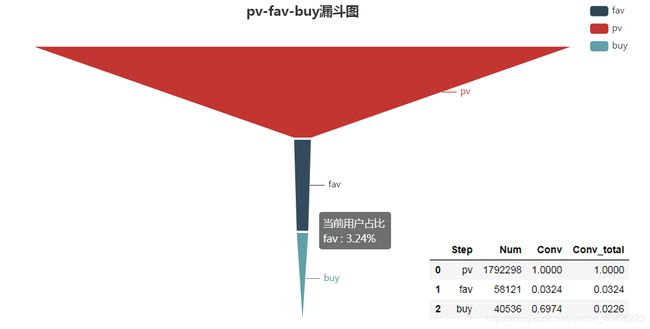
从上面两张图可以发现,全站商品的浏览到购买转化率是2.26%,其中加购和收藏作为中间环节,浏览到加购的转化率6.19%略高于浏览到收藏的转化率3.24%,说明加入购物车是用户更倾向使用的操作。而中间环节到购买的转化率,收藏(69.7%)明显高于加购(36.5%),这说明相较于放在购物车里的商品,用户有更大几率下单收藏的商品。
从每日成交率图中可以观察到,成交率在一个不大的范围内波动,基本稳定在2%到3%这个区间。其中工作日成交率略高于周末成交率,这可能是因为在工作日有企业用户下单或者个人因工作需要买东西比较干脆,亦或是其他原因,或者仅仅是正常的波动,恰好这段时间成交率高于周末,这需要更长时间范围的数据来验证。
另外12月2日和12月3日这两天成交率位于这段时间的最低值,而前述已知这两天网站活跃度是更大的,更大的浏览和用户活跃却有着相对更低的成交率,据此可以推测受促销周期影响,大多用户开始延后交易日期,等待双十二的促销再下单。因此这样的数据暂时下降是可以被接受的。
具体到某一个商品,由上面两图可以知道,有少数商品的浏览—购买转化比大于1,最大值是7,可见有些商品是用户直接下单购买的,甚至在买前不用浏览,这种情况一般是刚需采购或者不需要比价的小商品亦或是老顾客定期回购等。而转化比大于等于1商品约有5000种,由统计规则知,这里面还不包含完全没有浏览记录只有购买记录的商品,这类商品没有出现在图表中,理论上它们的转化比是无穷大,从计算该转化比的中间变量可知,这类商品有34396-item_p2b.count()=34396-23898=10498种,占到了10498/34396=30.5%。如果将这一部分商品算上,则浏览—购买转化比大于1的商品占到了全部出售商品的15498/34396=45%。可见有过半的商品在被购买前都经过了多次浏览,甚至仅仅只是被浏览过。
类似地由加购—购买转化比图示可知,少数商品的转化比大于1,最大值是9,这其中有可能是一次购买多个或者有的是被用户直接下单。另外有很大一部分转化比等于1,约有5000/9297=53.8%(9297来自于item_c2b.count()),这些商品被用户放进购物车,然后下单购买,购买数为1,这是最常见的消费行为。除此之外还有一部分转化比小于1,这些商品在放进购物车后并没有被下单,或者过段时间后用户不想买了,这也是常有的事。
由销量分布图示,图上可见大部分出售商品销量只有1个,大约占到了(34296-4000)/34396=88.4%,有极少数商品卖出了很多次,虽然占比很少,但高销量商品还是拉开了比较稳定的差距,前十的销量均大于10个,最大销量达到了24个。由此可见极少数的高销量商品也是销量中重要的组成部分。
4、24小时内用户行为分布与全站转化率、24小时内活跃用户分布相一致,三者相互对应,无异常值。这意味着从网站角度来看,每个用户是相近的,想提高收益等指标最好的办法就是做活动增加参与用户数,扩大用户基数。

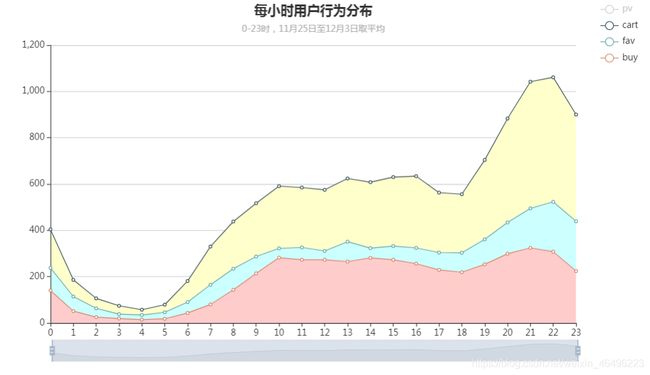
上面两图可以发现四种用户行为中,浏览量远超其他三种,若把浏览曲线隐去,可见另外三种行为加购量大于收藏量大于购买量,这与前面分析的转化率是相一致的,实际上这就是全站转化率的另一种观察角度。另外,四条曲线的走势和前面的24小时用户活跃度曲线也十分相近,行为数据与在线用户数量正相关。综上可以了解到网站的每一个用户都有相似的使用特点,不存在明显的超级用户团体,用户对网站的贡献相对平均,因此网站一些指标、数据的上涨将主要依靠参与用户数的增加。
5、单日复购率在1.4%左右,不受星期几和促销活动影响。短期来看复购率稳步提高,每天增涨0.4%左右。长期复购率需要更多数据支持,猜想将稳定于一个范围。
从上面两图可知,如果只看单日复购率,即一天内有哪些用户消费了一次以上,这个比例是稳定在1.4%左右,而且在休息日和促销周期无显著变化,这说明一天内是否多次购买取决于用户自己的考虑,与是否是周末、网站是否在做活动均无显著关系,且这样的用户占比稳定。如果看n日内复购率,则可见随着n的增加,复购率稳步增加,且呈现出较为明显的增长斜率,这说明随着日期范围的增长,有越来越多的用户会出现2次购买,这也侧面说明某宝并不是一次性平台,随着时间增长,越来越多的用户会再次在平台上购物。不过由于数据取样时间不够长,不能确定在更长时间范围内复购率是否还会保持这样的直线增长,更大的可能是在一段足够长的时间长度后趋于一个稳定范围。
6、短期来看,大部分消费用户都是低质量用户且细分类型分布均匀,高质量用户少有且分布不完全。但高质量用户的作用十分巨大,他们可贡献可观的销量,短期内高分用户的出现意味着平台具有一定发展潜力,预估随着时间增长,高分用户会越来越多。
参考RMF模型对用户进行打分,忽略M(消费金额)维度,只考察R、F两个维度。
首先回顾一下评分标准如下:
| R(最近一次消费时间) | F(消费频率) |
|---|---|
| 12月2至12月3日:4分 | 5次:5分 |
| 11月30至12月1日:3分 | 4次:4分 |
| 11月28至11月29日:2分 | 3次:3分 |
| 11月25至11月27日:1分 | 2次:2分 |
| 无消费:0分 | 1次:1分 |
| 0次:0分 |
从上面的气泡图中可以发现,很大一部分用户评分是(0,0),即没有任何消费记录。F评分为1的用户较为均匀的分布在R的四个评分上,这有相当一部分用户,这说明除去无消费用户,有相当一部分用户在短期(9天)内只消费过1次。F评分为2的用户也较为均匀的分布在R的四个评分上,不过体量明显小于F为1的用户,这说明有一小部分用户在短期(9天)内只消费过2次,虽然这部分用户数远小于只消费1次的用户,但在图上也还可识别。剩下的消费3次的用户就很少了,消费4次和5次的用户在图上几乎快看不见了,且也不再在R维度上都有得分。好消息是质量最高的用户,即得分(5,4)的用户在短期内就能出现,说明了平台的潜力和质量。估计随着时间增长,高分用户会越来越多。
结合消费贡献率图示,进一步可知绝大部分消费1次的用户贡献了约90%的销量,在这期间贡献率的增长直线斜率十分稳定。但是到了尾端的时候,增长斜率有一小段明显增大,可知这是由于小部分用户的消费拉升了贡献率,即有小部分用户消费了十分客观的商品量,这部分用户也就是在前面获得高分的那些用户。
7、下面来看四组具体的排名,展示了各个环节中用户最关注的10个商品。其中编号3031354表现最好,在浏览、加购、购买这三组榜单中均有出现,可能是近期流行或热单,其他跨组上榜的商品还有2331370、138964等7种。
大体上四类操作的前十产品各不相同,说明每个环节上用户的关注度都不太一样,浏览量高的并不一定会加到购物车或收藏,同样加购或收藏高的也并不一定会被购买。
至于是否有商品同时出现在上述四个TOP之中,经筛选结果如下:
| 所在范围 | 商品编号 |
|---|---|
| 浏览&加购 | 2331370, 138964, 3031354 |
| 浏览&收藏 | 2331370, 138964, 812879 |
| 浏览&购买 | 3031354 |
| 加购&收藏 | 1583704, 2331370, 138964, 2818406 |
| 加购&购买 | 3031354, 740947, 2560262 |
| 收藏&购买 | 无 |
| 浏览&加购&购买 | 3031354 |
| 浏览&收藏&购买 | 无 |
| 收藏&加购&购买 | 无 |
| 浏览&加购&收藏&购买 | 无 |
从上面的表格中可以关注到,有些商品不止出现在一个TOP10中,其中比较引人注意的是编号3031354、2331370, 138964这三个,其中3031354出现了4次,而且是唯一一个在浏览、加购、购买三个环节都是TOP10的商品,2331370出现了3次,138964出现了3次。
参考文献
- Pandas 中 SettingwithCopyWarning 的原理和解决方案
- pyecharts操作手册
- Python—padas(DataFrame)的常用操作
- Python之DataFrame常用方法小结
- 用 python 画散点图与气泡图
版本日志:
2020.4.4 初稿完成
2020.4.5 修改了一些错别字和不通顺语