本文将通过编译器生成的汇编代码分析C程序在IA-32体系PC上的运行流程
实验环境: gcc 4.8.2
C语言程序的内存结构
C代码如下
int g(int x)
{
return x + 1;
}
int f(int x)
{
return g(x);
}
int main(void)
{
return f(2) + 3;
}使用编译命令gcc -S -O0 -o main.s main.c -m32编译出汇编文件,如下
g:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %eax
addl $1, %eax
popl %ebp
ret
f:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl 8(%ebp), %eax
movl %eax, (%esp)
call g
leave
main:
pushl %ebp
movl %esp, %ebp
subl $4, %esp
movl $2, (%esp)
call f
addl $3, %eax
leave
入口点位于main,由main开始分析
- pushl %ebp
- subl $4, %esp
- movl %ebp, (%esp)
- 这是进入main函数后的第一个操作,保存了原来的ebp,即main开始执行之前的栈现场
- movl %esp, %ebp
- esp的值进入ebp,这儿将栈底设置为进入main之前的栈顶,即此处开始,ebp后面新增的栈都是main函数中的操作造成的,每次ebp的变化都意味着当前所处的函数的变化
- subl $4, %esp
- movl $2, (%esp)
- 以上两句实际上是执行了pushl $2, %esp,将立即数2入栈,
- 这句执行完成以后,使用gdb查看eip的值为0x8048418
- call f
- pushl %eip
- jmp f
- 调用f函数,上面两句入栈的立即数2就是函数f的参数,并将eip指向f的入口地址
- addl $3, %eax
- eax中存储的是函数f调用返回的结果,这条语句在eax上加上了立即数3
- leave
- movl %ebp, %esp
- popl %ebp
- 这两句将ebp还原到了调用main之前的现场,main函数调用到此为止
- ret
- popl %eip
- 将eip指回调用main之前的地址,退出函数main
进入main以后的第一个函数调用f(x)
- pushl %ebp
- movl %esp, %ebp
- 这儿的作用和main中一样,不重复说明
- subl $4, %esp
- 为参数留出栈空间
- movl 8(%ebp), %eax
- 栈地址是向下增长的,这儿ebp+8是获取了压入eip和参数前的地址,这条语句就是将参数存入eax
- movl %eax, (%esp)
- eax入栈,即参数入栈,c代码中函数g的参数就是函数f接收的参数,所以直接调用g函数
- call g
- pushl %eip
- jmp g
- leave
- 以上两行和main一致,不再重复
- ret
- 和main中作用一致
最后一个函数调用g(x)
- pushl %ebp
- movl %esp, %ebp
- 和前面描述一致,不赘述
- movl 8(%ebp), %eax
- 依然和f中的功能一致
- addl $1, %eax
- 函数g的功能,即在参数上+1
- popl %ebp
- movl (%esp), %ebp
- addl $4, %esp
- 恢复调用g之前的栈
- ret
- popl %eip
- 将eip指回调用函数g之前的地址,即回到函数f中
C语言程序在IA-32机器上的运行过程中,最重要的几条指令即push/pop,call/ret,其中push/pop实现了栈的基本操作,call/ret维护了函数的调用栈,确保了函数调用流程的连续
使用ddd抓了两张call前后的eip变化,可以很清晰的看出eip在call时的非线性改变
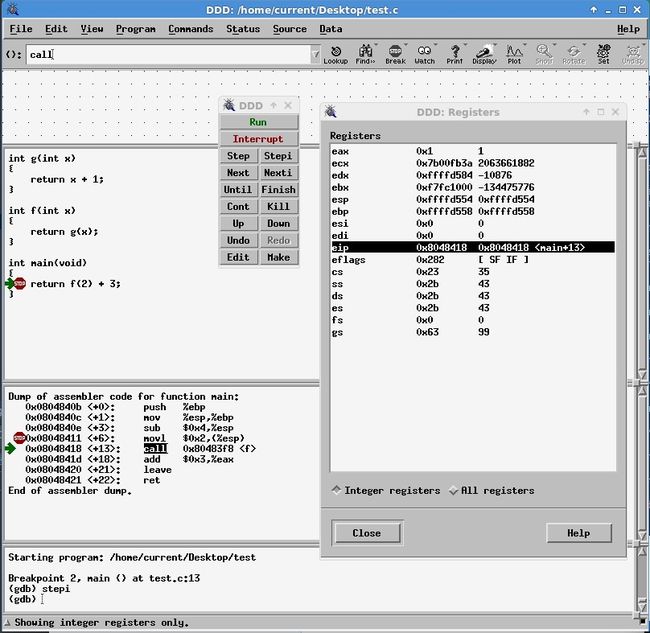
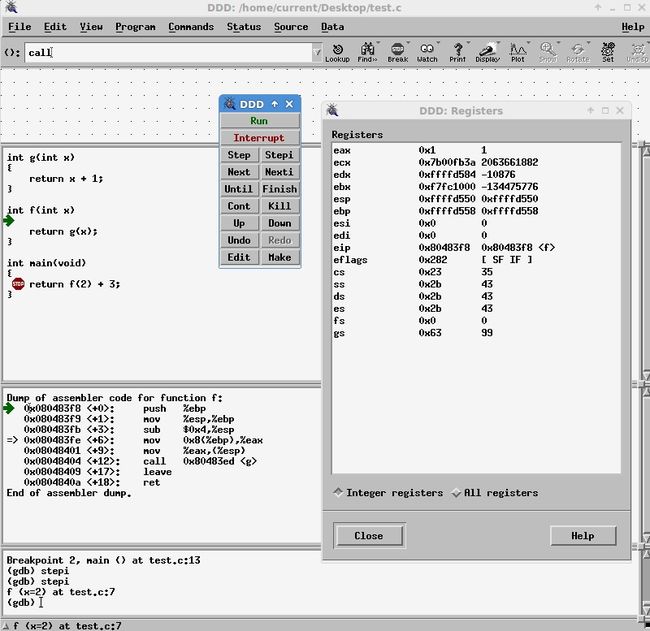
最后再看一下编译器优化可以做到的效果,以gcc -S -O3 -o test.s test.c -m32编译上述代码,得到的汇编如下
g:
movl 4(%esp), %eax
addl $1, %eax
ret
f:
movl 4(%esp), %eax
addl $1, %eax
ret
main:
movl $6, %eax
ret
可以看见编译器直接把main函数的结果算出来当做立即数返回了。。还是很强大的。。f和g这种简单函数也没有重新设置栈底,而是直接采用了变址寻址,提升了运行效率
云课堂作业
吴韬,原创作品转载请注明出处,《Linux内核分析》MOOC课程