Task5:Pytorch模型集成
一、前言
集成学习是指通过构建并结合多个学习器来完成学习任务的分类系统。
在机器学习中可以通过Stacking、Bagging、Boosting等常见的集成学习方法来提高预测精度,而在深度学习中,可以通过交叉验证的方法训练多个CNN模型,然后对这些训练好的模型进行集成就可以得到集成模型,从而提高字符识别的精度。如下图:
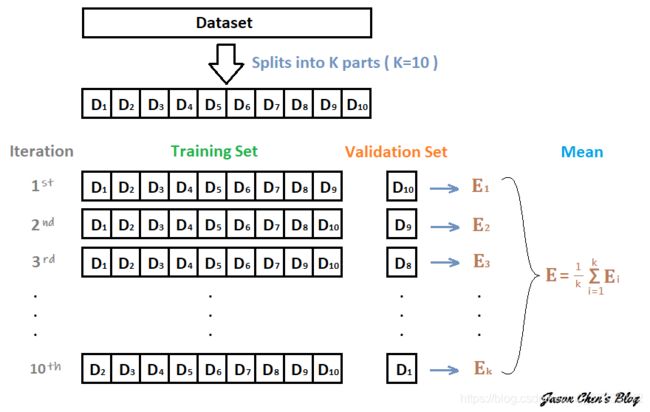
以上通过10折交叉验证,可训练得到10个CNN模型,集成方法有:
- 平均法:将10个模型预测结果的概率取平均值,然后解码为具体字符
- 投票法:对10个模型预测结果进行投票,得到最终字符
二、Pytorch实现模型集成
2.1 Dropout
Dropout作为一种DL训练技巧,是在每个Batch中,通过随机让一部分的节点停止工作减少过拟合,同样可以在预测模型时增加模型的精度,在训练模型中添加Dropout的方式为:
# 定义模型
class SVHN_Model1(nn.Module):
def __init__(self):
super(SVHN_Model1, self).__init__()
# CNN提取特征模块
self.cnn = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.Dropout(0.25), # 1/4随机失活
nn.MaxPool2d(2),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),
nn.ReLU(),
nn.Dropout(0.25), # 1/4随机失活
nn.MaxPool2d(2),
)
#全连接层
self.fc1 = nn.Linear(32*3*7, 11)
self.fc2 = nn.Linear(32*3*7, 11)
self.fc3 = nn.Linear(32*3*7, 11)
self.fc4 = nn.Linear(32*3*7, 11)
self.fc5 = nn.Linear(32*3*7, 11)
self.fc6 = nn.Linear(32*3*7, 11)
def forward(self, img):
feat = self.cnn(img)
feat = feat.view(feat.shape[0], -1)
c1 = self.fc1(feat)
c2 = self.fc2(feat)
c3 = self.fc3(feat)
c4 = self.fc4(feat)
c5 = self.fc5(feat)
c6 = self.fc6(feat)
return c1, c2, c3, c4, c5, c6
2.2TTA
测试集数据扩增(Test Time Augmention,TTA)也是常用的集成学习技巧,数据扩增不仅可以用在训练时候,而且可以在预测时候进行数据扩充,
对一个样本预测三次,取平均值
代码为:
def predict(test_loader, model, tta=10):
model.eval()
test_pred_tta = None
# TTA 次数
for _ in range(tta):
test_pred = []
with torch.no_grad():
for i, (input, target) in enumerate(test_loader):
c0, c1, c2, c3, c4, c5 = model(data[0])
output = np.concatenate([c0.data.numpy(), c1.data.numpy(),
c2.data.numpy(), c3.data.numpy(),
c4.data.numpy(), c5.data.numpy()], axis=1)
test_pred.append(output)
test_pred = np.vstack(test_pred)
if test_pred_tta is None:
test_pred_tta = test_pred
else:
test_pred_tta += test_pred
return test_pred_tta
2.3Snapshot
当训练多个模型可以通过平均值法折中处理,只训练一个CNN模型时,可以采用cyclical learning rate进行训练,每次训练保存精度较好的一些checkpoint,最后可以将多个checkpoint进行集成。
在训练过程中cyclical learning rate中学习率有周期性变大和减小的行为,因此CNN模型很有可能跳出局部最优进入另一个局部最优,但模型训练时间较长。
相对于ML来说,DL中CNN模型训练时间更长,受结构特征的影响也较大,所以多模型集成的效果也不一定有单模型的效率更高,应该尽量对数据集预处理进行较好的处理,调整CNN结构与loss function以训练单模型,往往效果更好。