python自然语言处理实战核心技术与算法——命名实体识别实战一:日期识别代码详解(二)
这里是《python自然语言处理实战核心技术与算法》——命名实体识别实战一:日期识别的第二部分,上一部分的文章链接点击这里。
目录
- 一、parse_datetime(msg)
- 1. try
- 2. except
- 二、预定义模板
- 三、year2dig(year)
- 四、cn2dig(src)
- 五、总结
- 六、总体代码与结果展示
- 七、参考
一、parse_datetime(msg)
def parse_datetime(msg):
"""
将每个提取到的文本日期串进行时间转换
实现方式:
通过正则表达式将日期串进行切割,分成'年''月''日''时''分''秒'等具体维度,然后针对每个子维度单独再进行识别
:param msg: 初步清洗后的每一个有关时间的句子
:return: 如果时间可以通过parse解析,那么返回解析后的时间
如果不能够解析,那么返回自行处理后的时间
否则返回None
"""
if msg is None or len(msg) == 0:
# 如果之前清洗失误或者其他原因造成的句子为空,则返回None
return None
try:
# 将日期格式化成datetime的时间,fuzzy=True: 允许时间是模糊时间,如:
# Today is January 1, 2047 at 8:21:00AM
# dt = parse(msg, fuzzy=True)
dt = parse(msg)
return dt.strftime('%Y-%m-%d %H:%M:%S')
except Exception as e:
m = re.match(r"([0-9零一二两三四五六七八九十]+ 年)? ([0-9一二两三四五六七八九十]+ 月)? "
r"([0-9一二两三四五六七八九十]+ [号日])? ([上中下午晚早]+)?"
r"([0-9零一二两三四五六七八九十百]+[点:.时])?([0-9零一二三四五六七八九十百]+ 分?)?"
r"([0-9零一二三四五六七八九十百]+ 秒)?", msg)
if m and m.group(0) is not None:
res = {
'year': m.group(1),
"month": m.group(2),
"day": m.group(3),
"hour": m.group(5) if m.group(5) is not None else '00',
"minute": m.group(6) if m.group(6) is not None else '00',
"second": m.group(7) if m.group(7) is not None else '00',
}
params = {}
for name in res:
if res[name] is not None and len(res[name]) != 0:
if name == 'year':
# 如果是年份,tmp就进入year2dig
tmp = year2dig(res[name][: -1])
else:
# 否则就是其他时间,那么进入cn2dig
tmp = cn2dig(res[name][: -1])
if tmp is not None:
# 当tmp之中存在阿拉伯数字的时候,params就为该tmp
params[name] = int(tmp)
# 使用今天的时间格式,然后将数字全部替换为params[]中的内容
target_date = datetime.today().replace(**params)
is_pm = m.group(4)
if is_pm is not None:
# 如果文字中有"中午"、"下午"、"晚上"二字
if is_pm == u'下午' or is_pm == u'晚上' or is_pm == u'中午':
hour = target_date.time().hour # 获取刚刚解析的时间的小时
if hour < 12:
# 如果小时小于12,那么替换为24小时制
target_date = target_date.replace(hour=hour + 12)
return target_date.strftime("%Y-%m-%d %H:%M:%S")
else:
return None
这一坨代码出的问题有点多,我估计大部分人的代码跑不通都是出在这一坨代码之中,我们接着来分析这坨代码。
最上面if语句就不用说了,就相当于是个保护措施,干掉之前清洗没清洗到的漏网之鱼。
主要是这个try-except语句。我们看到except语句中很大一坨代码,也就说明try中的代码可以处理掉一部分代码,另外一部分会抛出异常,交给except处理,所以我们先看try。
1. try
去掉return的这个格式化日期的代码之外,try中就只有一行代码:dt = parse(msg)。这里我的代码和书本上的不一样,我这里一会再说区别,先说这个parse,这个是来自于dateutil.parser库中的方法,源码中的说明如下:
Parse a string in one of the supported formats, using the
``parserinfo`` parameters.
翻译过来再结合上具体用法,那么大体为:将字符串通过什么参数格式化成日期。而书上的代码是:
dt = parse(msg, fuzzy=True)
多了个fuzzy = True这个参数,我查阅了很多资料都查不到这个实际意义,于是我们继续从源码下手:
Whether to allow fuzzy parsing, allowing for string like "Today is
January 1, 2047 at 8:21:00AM".
大体意思就是是否支持模糊格式化,那么我这里为什么把fuzzy = True给去掉了呢?
是因为之前我测试的第一条语句是"我要住到明天下午三点",获得的结果是[‘2020-07-21 00:00:00’],于是我打断点发现根本没有进入except语句,而这个parse无法识别"下午三点",所以后面的结果是"00:00:00"。
但是你会发现去掉了之后也会有错,测试语句里面有一句话"预定28号的房间",这个"28号"是个模糊的概念,作为我们人,我们会理所应当的认为是最近的下一个28号,但是计算机不知道呀,所以这里是没法识别这个"28号"的,出来的结果也为[],所以这里也就又看出了基于规则的NER的缺点。
2. except
书上写的核心是这个正则表达式:
m = re.match(r"([0-9零一二两三四五六七八九十]+ 年)? ([0-9一二两三四五六七八九十]+ 月)? "
r"([0-9一二两三四五六七八九十]+ [号日])? ([上中下午晚早]+)?"
r"([0-9零一二两三四五六七八九十百]+[点:.时])?([0-9零一二三四五六七八九十百]+ 分?)?"
r"([0-9零一二三四五六七八九十百]+ 秒)?", msg)
这个匹配没啥好说的,还是比较好懂的,我这里主要说一下很关键的问题:注意空格!
这个空格要和上一篇文章提到的日期初始化第一步关联起来看,上文链接如下:点击这里。代码如下:
word = (datetime.today() + timedelta(days=key_date.get(k, 0))) \
.strftime('%Y {0} %m {1} %d {2} ').format('年', '月', '日')
大家看到,这里这个格式化的时候,每个字之间都有个空格,然后上面的正则,在有几个"+“和”?"之间也有空格,这个真不是我为了代码好看或者手抖而弄得空格,这真的是剧本需要,要结合上再下面的if语句看:
if m and m.group(0) is not None:
res = {
'year': m.group(1),
"month": m.group(2),
"day": m.group(3),
"hour": m.group(5) if m.group(5) is not None else '00',
"minute": m.group(6) if m.group(6) is not None else '00',
"second": m.group(7) if m.group(7) is not None else '00',
}
这个if不说了,就是match成功,重点是成功之后这个group,group(0)表明这个match对象有内容(不为None)。但是如果前面的格式化和正则都没有空格的话,那么match出来的对象就只有一项(即只有group(0)),就假设我们的语句match出来是"2020年07月21日09:30:00",那么res只会有一项,即{“year”: 2020年07月21日09:30:00},所以这里要加上空格区分不同的group。
注:不过话说回来,按理来说应该是每匹配成功一个内容,group增加一个,但是我是还没弄懂为什么不加空格会只有一个group。这里只能配上一张图表达我的心情:

之后的代码就涉及到下面两个方法了,我们下面再讲解这两个方法,先看到最下面的if语句,这个主要就是将时间转换成24小时制,没啥好说的,所以就讲解那两个方法。
这里参数传入,是传入的从头到倒数第二个字为止,我个人理解为什么不是全部传入,估计是为了清除最后一个空格或者最后一个字,比如"2020年"的"年",但是这里还会引入另外一个新的问题,如果文字本身就是"3点15",那么不就是把这个5清除了么,就会造成误差,而且从另外一个角度上讲,就算传进去一个无用的字符,反正后面也会清洗掉,那也无所谓呀,就感觉这个-1是可以不要的。
二、预定义模板
这个模板是使用在下面两个方法中的,功能是将汉字转换为阿拉伯数字:
UTIL_CN_NUM = {
'零': 0, '一': 1, '二': 2, '两': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9,
'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9,
}
UTIL_CN_UTIL = {'十': 10, '百': 100, '千': 1000, '万': 10000}
三、year2dig(year)
这个方法主要针对的是"年"这个维度,因为年份和其他几个时间的计算方式不同,所以这里分为了两个方法进行处理:
def year2dig(year):
"""
解析年份这个维度,主要是将中文或者阿拉伯数字统一转换为阿拉伯数字的年份
:param year: 传入的年份(从列表的头到倒数第二个字,即假设有"年"这个字,则清洗掉"年")
:return: 所表达的年份的阿拉伯数字或者None
"""
res = ''
for item in year:
# 循环遍历这个年份的每一个字符
if item in UTIL_CN_NUM.keys():
# 如果这个字在UTIL_CN_NUM中,则转换为相应的阿拉伯数字
res = res + str(UTIL_CN_NUM[item])
else:
# 否则直接相加
# 这里已经是经历了多方面清洗后的结果了,基本到这里不会在item中出现异常的字符
res = res + item
m = re.match("\d+", res)
if m:
# 当m开头为数字时,执行下面操作,否则返回None
if len(m.group(0)) == 2:
# 这里是假设输入的话为"我要住到21年..."之类的,那么year就只有2个字符,即这里m == 21,
# 那么就通过当前年份除100的整数部分再乘100最后加上这个数字获得最终年份
# 即int(2020 / 100) * 100 + int("21")
return int(datetime.today().year / 100) * 100 + int(m.group(0))
else:
# 否则直接返回该年份
return int(m.group(0))
else:
return None
这里注释我个人觉得写得很清楚了,值得一提的就是这个计算方式:
if len(m.group(0)) == 2:
# 这里是假设输入的话为"我要住到21年..."之类的,那么year就只有2个字符,即这里m == 21,
# 那么就通过当前年份除100的整数部分再乘100最后加上这个数字获得最终年份
# 即int(2020 / 100) * 100 + int("21")
return int(datetime.today().year / 100) * 100 + int(m.group(0))
这个2的来历反正我个人认为我们平时说年份不会加上"世纪",就比如"我在20年开头开始学习python","我毕业于19年"这样,不过这个计算方式确实挺新奇的,大佬就是大佬,先膜拜一下。
四、cn2dig(src)
def cn2dig(src):
"""
除了年份之外的其余时间的解析
:param src: 除了年份的其余时间(从列表的头到倒数第二个字,即假设有"月"这个字,则清洗掉"月")
:return rsl: 返回相应的除了年份的其余时间的阿拉伯数字
"""
if src == "":
# 如果src为空,那么直接返回None,又进行一次清洗
return None
m = re.match("\d+", src)
if m:
# 如果m是数字则直接返回该数字
return int(m.group(0))
rsl = 0
unit = 1
for item in src[:: -1]:
# 从后向前遍历src
if item in UTIL_CN_UTIL.keys():
# 如果item在UTIL_CN_UTIL中,则unit为这个字转换过来的阿拉伯数字
# 即假设src为"三十",那么第一个item为"十",对应的unit为10
unit = UTIL_CN_UTIL[item]
elif item in UTIL_CN_NUM.keys():
# 如果item不在UTIL_CN_UTIL而在UTIL_CN_NUM中,则转换为相应的阿拉伯数字并且与unit相乘
# 就假设刚刚那个"三十",第二个字为"三",对应的num为3,rsl就为30
num = UTIL_CN_NUM[item]
rsl += num * unit
else:
# 如果都不在,那么就不是数字,就直接返回None
return None
if rsl < unit:
# 如果出现"十五"这种情况,那么是先执行上面的elif,即rsl = 5,再执行if,即unit = 10,
# 这时候rsl < unit,那么执行相加操作
rsl += unit
return rsl
这里主要也是计算方式,因为我注释写的比较分散,我这里用"三十"和"十三"的图示来讲解这个计算过程。(注:作者这里是从后向前遍历的)
- “三十”:
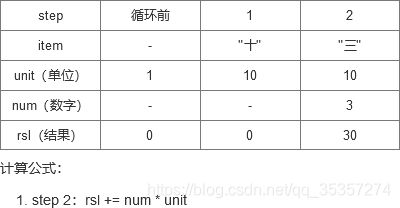
- “十三”:这里是在循环后因为unit > rsl,所以进入下面的if语句。
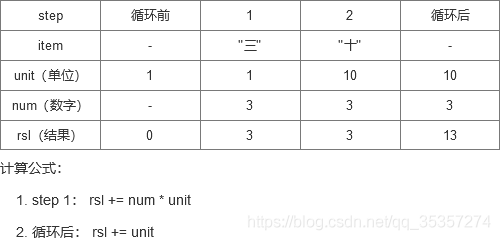
这一坨的核心就是如何让 “数字” * “单位” 获得最后结果。
五、总结
当我阅读完整个代码后,我总结出来以下几点与大家分享:
- 基于规则的NER运行快速,但是普适性很差,如果要进行功能扩展,那么可能会花费更多的人力物力;
- check_time_valid(word)中的第一个if语句感觉可以优化的更简单明了一些;
- 对于parse_datetime(msg)中传入year2dig和cn2dig的参数,感觉不太需要把最后一个字符去掉,有可能会造成错误,比如: “三点十五”,那么就会去掉"五",造成错误;
- parse(msg, fuzzy=True)的问题,如果加上fuzzy=True,那么有些句子进入不了except语句导致错误,但是如果不加的话,那么有些语句无法解析也会错误。
六、总体代码与结果展示
总体代码包括注释我放在了github上,链接如下:https://github.com/Balding-Lee/nlp_3
结果如下:
我要住到明天下午三点:['2020-07-22 15:00:00']
预定28号的房间:[]
我要从26号下午4点住到8月2号:[]
我要预定今天到30号的房间:['2020-07-21 00:00:00']
今天30号呵呵:['2020-07-21 00:00:00']
我从今天住到后天下午3点:['2020-07-21 00:00:00', '2020-07-23 15:00:00']
就会发现确实有很多的问题需要进行优化。
七、参考
[1]涂铭,刘祥,刘树春.Python自然语言处理实战核心技术与算法[M].机械工业出版社:北京,2018.4:63.