CPU Cache 基础解析
文末含分享内容视频链接
CPU Cache 基础
最近看了一些 CPU 缓存相关的东西,在这里做一下记录。
Wiki 词条:CPU cache - Wikipedia
一些基本概念
CPU 缓存出现的原因
- 主存一般是 DRAM,CPU 速度比主存快很多倍,没有缓存存在时 CPU 性能很大程度取决于读取存储数据的能力
- 比 DRAM 快的存储介质是存在的,比如作为 CPU 高速缓存的 SRAM,只是很贵,做很大的 SRAM 不经济
- CPU 访问数据存在时间局部性和空间局部性,所以可以将 CPU 需要频繁访问的少量热数据放在速度快但很贵的 SRAM 中,既能大幅度改善 CPU 性能也不会让成本提升太多
Cache Line
CPU 每次访问数据时先在缓存中查找一次,找不到则去主存找,访问完数据后会将数据存入缓存,以备后用。这就产生了一个问题,CPU 在访问某个地址的时候如何知道目标数据是在缓存中存在?如何知道缓存的数据是否还有效没被修改?不能为每个存入缓存的字节都打标记,所以 CPU 缓存会划分为固定大小的 Block 称为 Cache Line,作为存取数据的最小单位。大小都为 2 的整数幂,比如 16 字节,256 字节等。这样一个 cache line 这一整块内存能通过一个标记来记录是否在内存中,是否还有效,是否被修改等。一次存取一块数据也能充分利用总线带宽以及 CPU 访问的空间局部性。
Cache Write Policy
Cache 不光是在读取数据时有用,目前大部分 CPU 在写入数据时也会先写 Cache。一方面是因为新存数据很可能会被再次使用,新写数据先写 Cache 能提高缓存命中率;另一方面 CPU 写 Cache 速度更快,从而写完之后 CPU 可以去干别的事情,能提高性能。
CPU 写数据如果 Cache 命中了,则为了保持 Cache 和主存一致有两种策略。如果 CPU 写 Cache 每次都要更新主存,则称为 Write-Through ,因为每次写 Cache 都伴随主存更新所以性能差,实际使用的也少;写 Cache 之后并不立即写主存而是等待一段时间能积累一些改动后再更新主存的策略称为 Write-Back ,性能更好但为了保证写入的数据不丢使机制更加复杂。采用 Write Back 方式被修改的内存在从 Cache 移出(比如 Cache 不够需要腾点空间)时,如果被修改的 Cache Line 还未写入主存需要在被移出 Cache 时更新主存,为了能分辨出哪些 Cache 是被修改过哪些没有,又需要增加一个新的标志位在 Cache Line 中去标识。
CPU 写数据如果 Cache 未命中,则只能直接去更新主存。但更新完主存后又有两个选择,将刚修改的数据存入 Cache 还是不存。每次直接修改完主存都将主存被修改数据所在 Cache Line 存入 Cache 叫做 Write-Allocate 。需要注意的是 Cache 存取的最小单位是 Cache Line。即使 CPU 只写一个字节,也需要将被修改字节所在附近 Cache Line 大小的一块内存完整的读入 Cache。如果 CPU 写主存的数据超过一个 Cache Line 大小,则不用再读主存原来内容,直接将新修改数据写入 Cache。相当于完全覆盖主存之前的数据。
写数据时除了需要考虑上述写 Cache 策略外,还需要保持各 CPU Cache 之间的一致性。比如一个 CPU 要向某个内存地址写数据,它需要通知其它所有 CPU 自己要写这个地址,如果其它 CPU 的 Cache Line 内有缓存这个地址的话,需要将这个 Cache Line 设置为 Invalidate。这样写数据的那个 CPU 就能安全的写数据了。下一次其它 CPU 要读这个内存地址时,发现这个 Cache Line 是 Invalidate 状态,所以需要重新从内存做加载,即发生一次 Communication Miss。这种 Miss 不是 Cache 不够大,也不是 Cache 冲突,而是因为其它 CPU 写同一个 Cache Line 里数据导致了 Cache Miss。缓存一致性维护需要专门文章来写。
SMP 和 NUMA
SMP 词条:Symmetric multiprocessing - Wikipedia
NUMA 词条:Non-uniform memory access - Wikipedia
简单说 SMP 就是一组 CPU 会通过一条总线共享机器内的内存、IO 等资源。因为所有东西都是共享的,所以扩展性受限。
NUMA 则是将机器内 CPU 分为若干组,每个组内都有独立的内存,IO资源,组与组之间不相互共享内存和 IO 等资源,组之间通过专门的互联模块连接。总体上扩展性更强。
本文主要以 SMP 系统为例。CPU 以及 Cache,Memory 的关系如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H2wxDx3V-1586935954154)(http://lc-kaK4q1Br.cn-n1.lcfile.com/9688c18e01749b0f4d93/cpu%201.jpg)]
CPU 缓存结构
Direct Mapped Cache
最简单的缓存结构就是 Direct Mapped 结构。如下图所示,每个 Cache Line 由基本的 Valid 标志位,Tag 以及 Data 组成。当访问一个内存地址时,根据内存地址用 Hash 函数处理得到目标地址所在 Cache Line 的 Index。根据 Index 在 Cache 中找到对应 Cache Line 的 Data 数据,再从 Data 中根据内存地址的偏移量读取所需数据。因为 Hash 函数是固定的,所以每一个内存地址在缓存上对应固定的一块 Cache Line。所以是 Direct Mapped。
实际中为了性能 hash 函数都非常简单,就是从内存地址读取固定的几个 bit 数据作为 Cache Line 的 Index。拿下图为例,Cache Line 大小为 4 字节,一共 32 bit 是图中的 Data 字段。4 字节一共需要 2 bit 用于寻址,所以看到 32 bit 的地址中,0 1 两个 bit 作为 Offset。2 ~ 11 bit 作为 Cache Line 的 Index 一共 1024 个,12 ~ 31 bit 作为 tag 用于区分映射到相同 Cache Line 的不同内存 block。比如现在要读取的地址是 0x1124200F,先从地址中取 2 ~ 11 bit 得到 0x03 表示目标 Cache Line 的 Index 是 3,之后从地址中读 12 ~ 31 bit 作为 tag 是 0x11242。拿这个 Tag 跟 Index 为 3 的 Cache Line 的 Tag 做比较看是否一致,一致则表示当前 Cache Line 中包含目标地址,不一致则表示当前 Cache Line 中没有目标地址。因为 Cache 比内存小很多,所以可能出现多个不在同一 Cache Line 的内存地址被映射到同一个 Cache Line 的情况,所以需要用 Tag 做区分。最后,如果目标地址确实在 Cache Line,且 Cache Line 的 Valid 为 true,则读取 0x1124200F 地址的 0 ~ 1 bit,即找目标数据在 Cache Line 内的 Offset,得到 0x03 表示读取当前 Cache Line 中最后一个字节的数据。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PeR6GMdg-1586935954156)(http://lc-kaK4q1Br.cn-n1.lcfile.com/81f96f5f750d870b7039/cpu%202.jpg)]
上图的 Cache 是 1024 X 4 字节 一共 4 KB。但由于 Tag 和 Valid 的存在,缓存实际占用的空间还会更大。
替换策略
因为 Direct Mapped 方式下,每个内存在 Cache 中有固定的映射位置,所以新访问的数据要被存入 Cache 时,根据数据所在内存地址计算出 Index 发现该 Index 下已经存在有效的 Cache Line,需要将这个已存在的有效 Cache Line 从 Cache 中移出。如果采用 Write-Back 策略,移出时需要判断这个数据是否有被修改,被修改了需要更新主存。
Write-Back 策略在前面有介绍,即写数据时只写缓存就立即返回,但标记缓存为 Dirty,之后在某个时间再将 Dirty 的缓存写入主存。
Two-way Set Associative Cache
我们希望缓存越大越好,越大的缓存经常意味着更快的执行速度。对于 Direct Mapped Cache 结构,增大缓存就是增加 Index 数量,相当于是对上面表进行纵向扩展。但除了纵向扩展之外,还可以横向扩展来增加 Cache 大小,这就是 Two-way Set Associative Cache。
基本就是如下图所示,图上省略了 Tag 和 Valid 等标识每个 cell 就是一个 Cache Line,与 Direct Mapped Cache 不同点在于,Two-way Set Associative Cache 里每个 Index 对应了两个 Cache Line,每个 Cache Line 有自己的 Tag。同一个 index 下的两个 cache line 组成 Set。在访问内存时,先根据内存地址找到目标地址所在 Set 的 index,之后并发的去验证 Set 下的两个 Cache Line 的 Tag,验证目标地址是否在 Cache Line 内,在的话就读取数据,不在则去读主存。
这里并发的验证两个 Cache Line 的 Tag 是由硬件来保证,硬件电路结构会更加复杂但查询效率与 Direct Mapped Cache 一致。
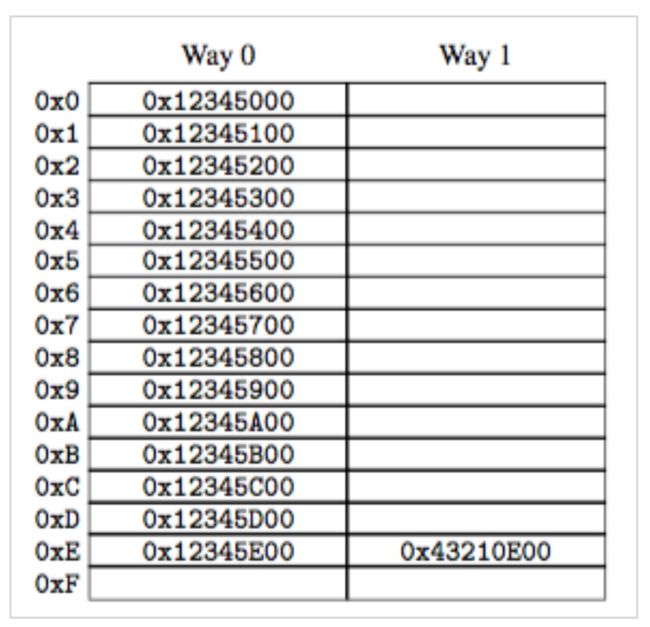
Set 内的两个 Cache Line 是具有相同 Index 的两个不同 Cache Line。上图来自 Is Parallel Programming Hard, And, If So, What Can You Do About It?,图 C.2。以这个图为例,假设 Cache Line 大小是 256 字节,所以图上所有地址最右侧都是 00,即有 8 bit 的 Offset,从 0 到 7。因为 Cache Line 只有 16 个,所以 index 是 4 bit,从 8 ~ 11。图中看到 0x12345E00 和 0x43210E00 在 8 ~ 11 bit 位置上是相同的,都是 0xE 所以这两个内存地址被映射到 Cache 中同一个 Index 下。这两个 Cache Line 就会放在同一个 Set 内,在访问时能同时被比较 Tag。
替换策略
新数据要存入 Cache 时,根据数据所在内存地址计算出 Index 后发现该 Index 下两个 Way 的 Cache Line 都已被占用且处在有效状态。需要有办法从这两个 Cache Line 里选一个出来移除。Direct Mapped 因为一个 Index 下只有一个 Cache Line 就没这个问题。
如果是这里说的 Two-way Set Associative Cache 还比较好弄,给每个 Way 增加一个最近访问过的标识。每次一个 Way 被访问就将最近访问位置位,并清理另一个 Way 的最近访问位。从而在执行替换时,将不是最近访问过的那个 Way 移除。不过下面会看到 N-way Set Associative Cache 当有 N 个 Way 的时候替换策略更加复杂,一般是尽可能使用最少的状态信息实现近似的 LRU。
N-way Set Associative Cache
顾名思义,就是在 Two-way Set Associative Cache 基础上继续横向扩展,在一个 Set 内加入更多更多的 Way 也即 Cache Line。这些 Cache Line 能被并发的同时验证 Tag。如果 Cache 内所有的 Cache Line 都在同一个 Set 内,即所有 Cache Line 都能同时被验证 Tag,则这种 Cache 叫做 Fully Associative Cache 。可以看出 Fully Associative Cache 性能是最强的,能省去从地址中读取 Index 查找 Set 的过程。但横向扩展的 Way 越多,结构越复杂,成本越高,越难实现大的 Cache。所以 Fully Associative Cache 虽然存在,但都很小,一般用在 TLB 上。
Cache 结构为什么发展出横向扩展?
这个是我自己提出来的问题。对 Direct Mapped Cache 扩展 Cache 时就是增加更多的 index,让 cache 表变得更长。但为什么会发展出 Two-way Set Associative Cache 呢?比如如果一共 16 个 Cache Line,是 16 行 Cache Line 还是 8 行 Set 每个 Set 两个 Cache Line 在容量和命中率上似乎并没有差别。
后来看到了 这个问题 ,明白了其中的原因。主要是需要区分出来 Conflict Miss 和 Capacity Miss (还有一个 Communication Miss,前面说过)。当 Cache 容量足够,但由于两块不同的内存映射到了同一个 Cache Line,导致必须将老的内存块剔除产生的 Miss 叫做 Conflict Miss,即使整个 Cache 都是空的,只有这一个 Cache Line 有效时也会出现 Miss。而由于容量不足导致的 Miss 就是 Capacity Miss。比如 cache 只有 32k,访问的数据有 200k,那访问时候一定会出现后访问的数据不断的把先访问数据从 Cache 中顶出去,导致 Cache 一直处在 Miss 状态的问题。
在 Capacity Miss 方面横向扩展和纵向扩展没有什么区别,主要区别就是 Conflict Miss。假若轮番访问 A B 两个内存,这两个内存映射到同一个 Cache Line 上,那对于 Direct Mapped Cache,因为每块内存只有固定的一个 Cache Line 能存放,则会出现持续的 Conflict Miss,称为 cache thrashing。而 Two-way Set Associative Cache 就能将 A B 两块内存放入同一个 Set 下,就都能 Cache 住,不会出现 Conflict Miss。这就是横向扩展的好处,也是为什么横向扩展即使困难,各个 CPU 都在向这个方向发展。并且横向扩展和纵向扩展并不冲突,Two-way Set Associative Cache 也能加多 Set 来进行扩展。
Cache Prefetching
词条:Cache prefetching - Wikipedia
Cache 运作时并不一定每次只加载一条 Cache Line,而是可能根据程序运行状况,发现有一些固定模式比如 for loop 的时候在加载 Cache Line 时会多加载一点,类似于通过 Batch 来做优化一样。
为什么缓存存取速度比主存快
Why is SRAM better than DRAM? - Quora
False Sharing
Wiki 词条:False sharing - Wikipedia
比如像下面图这个样子:

A B 两个对象在内存上被连续的创建在一起,假若这两个对象都很小,小于一个 Cache Line 大小,那他们可能会共用同一个 Cache Line。如果再有两个线程 Thread 1 和 Thread 2 会去操作这两个对象,我们从代码角度保证 Thread 1 只会操作 A,而 Thread2 只会操作 B。那按道理这两个 Thread 访问 A B 不该有相互影响,都能并行操作。但现在因为它俩刚好在同一个 Cache Line 内,就会出现 A B 对象所在 Cache Line 在两个 CPU 上来回搬迁的问题。
比如 Thread 1 要修改对象 A,那 Thread 1 所在 CPU 1 会先获取 A 所在 Cache Line 的 Exclusive 权限,会发送 Invalidate 给其它 CPU 让其它 CPU 设置该 Cache Line 为无效。之后 Thread 2 要修改对象 B,Thread 2 所在 CPU 2 又会尝试获取 B 所在 Cache Line 的 Exclusive 权限,会发 Invalidate 给其它 CPU,包括 CPU 1。CPU 1 要是已经写完了 A,那就要把数据刷写内存,之后设置 Cache Line 无效并响应 Invalidate。没写完就得等待 CPU 1 写完 A 后再处理 Cache Line 的 Invalidate 问题。之后 CPU 2 再去操作 Cache Line 更新 B 对象。再后来 Thread 1 要去更新 A 对象的话又要去把 A B 所在 Cache Line 在 CPU 2 上设置无效。也就是说这块 Cache Line 失去了 Cache 功能,会在两个 CPU 上来回搬迁,会经常性的执行刷写内存,读取内存操作,导致两个本来看上去没有关系的操作实际上有相互干扰。
想观测到这个现象最简单的是让 A B 是同一个类的不同 Field,而不是两个独立对象,比如:
class SomeClass{
volatile long valueA;
volatile long valueB;
}
这个对象在内存上布局如下:
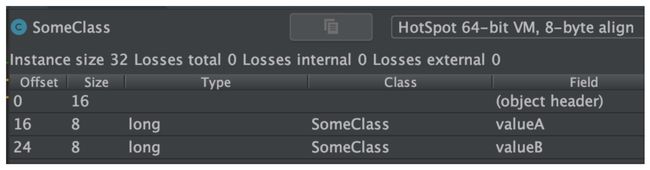
看到这个 Object 只有 32 字节,在我机器上一个 Cache Line 是 64 字节 (mac 上执行 sysctl machdep.cpu.cache.linesize,Linux 上执行 getconf LEVEL1_DCACHE_LINESIZE 来查看),所以 A B 都能放在同一个 Cache Line 上,之后可以创建出来两个 Thread 去分别操作同一个 SomeClass 对象的 valueA 和 valueB Field,记录一下时间,再跟下面解决方案里说的方式做对比,看看 False Sharing 的现象。
解决办法
解决这个问题的办法也很容易,如果是上面例子的话,就是让被操作的 valueA 和 valueB 隔得远一点。比如可以这么声明:
class SomeClassPadding {
volatile long valueA;
public long p01, p02, p03, p04, p05, p06, p07, p08;
volatile long valueB;
}
对象内存布局就变成了:

因为我确认我机器的 Cache Line 是 64 字节,所以加了 8 个 long。如果 Padding 少一些,比如 6 个,那 valueA 在 Offset 16,第六个 Padding 在 Offset 64,valueB 恰好是 Offset 64,似乎已经足够将 valueB 放到下一个 Cache Line 了但实际还是有问题。因为对象不一定刚好分配在 Cache Line 开头,比如 Cache Line 恰好从 valueA 所在 Offset 16 开始,到 Offset 80 结束,如果只有 6 个 long 做 Padding,那 valueA 和 valueB 还是在同一个 Cache Line 上。所以 Padding 至少需要和 Cache Line 一样长。
还有要注意看到 Padding 得声明为 public,不然 JVM 发现这一堆 Padding 不可能被访问到可能就直接优化掉了。
在我机器上测试,Padding 之后性能提升了大概 4 5 倍的样子。如果上面 SomeClasPadding 去掉 volatile 声明,则提升大概 1.5 倍的样子,之所以有这个差距是因为没有 volatile 的话线程操作 valueA 和 valueB 如果 Cache Line 不在当前 CPU Cache 中,它并不要求等待 Cache Line 加载进来后再做写入,而是可以把写入操作放在一个叫 Store Buffer 的地方以提高性能,具体可以关注我们的下一篇分享内容。等 Cache Line 加载后再对它做修改,相当于是将一段时间的写入操作积累了一下一口气写入。而有了 volatile 后则要求每次写入真的得等 Cache Line 加载后再写,从而放大了等待 Cache Line 加载的时间,更容易观察到 False Sharing 问题。
另外,Padding 当然是有代价的。一个是让对象变得更大,占用内存,再有是 Padding 了一堆无用数据还得加载到 Cache 里,白白占用了 Cache 空间。
需要注意的是自己手工 Padding 方法可能被虚拟机做重排,即 Padding 本来想加到 valueA 和 valueB 之间,但可能被重排到 valueB 之后,导致实际没有什么用。比如:
class SomeClassPadding {
volatile long valueA;
public int p01, p02, p03, p04, p05, p06, p07, p08;
volatile long valueB;
}
实际的内存布局是下图这样,即 Padding 都跑到 valueB 后面去了。另外按说 Cache Line 是 64 字节的话用 int 做 Padding 至少要 16 个,我这里只是为了说明手工 Padding 的问题,所以少写了一些。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Muy3idK2-1586935954163)(http://lc-kak4q1br.cn-n1.lcfile.com/d4db3ac75998721ae102/cpu7.jpg)]
内存布局实际会依赖虚拟机而不同,所以上面这种 Padding 方式是不可靠的。即使变量真声明为 long 也不能保证所有虚拟机都按照相同方式做排列。最靠谱的手工 Padding 方式是用 Class 的层级结构做 Padding,因为 JVM 要求父类的成员一定要排在子类成员之前,所以级联的 Class 结构能保证 Padding 的可靠性。比如:
class SomeClassValueA {
volatile long valueA;
}
class SomeClassPaddings extends SomeClassValueA{
public int p01, p02, p03, p04, p05, p06, p07, p08, p09, p10, p11;
}
class SomeClassValueB extends SomeClassPaddings{
volatile long valueB;
}
class SomeClass extends SomeClassValueB{
}
内存结构就变成:
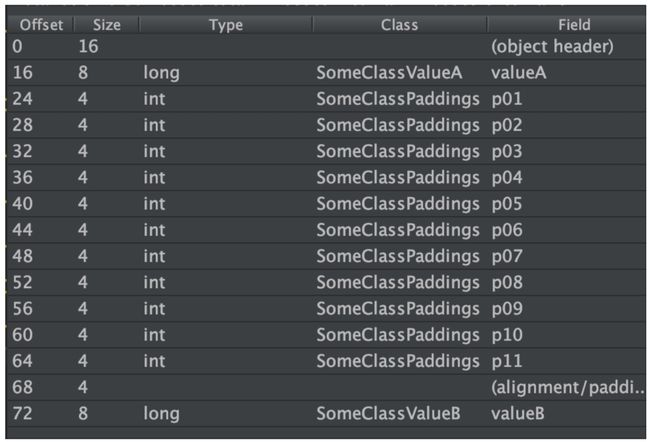
这里为了演示用 int 做 Padding,又不想让图片太长,所以只写了 11 个 int,但实际至少需要 16 个 int 即凑够 64 字节才行。一般 Padding 都用 long 做,不会用 int,可以少写很多变量。
这个顺序是 JVM 规范保证的,所以所有虚拟机都会按照这个方式排列,所以是可靠的。
另一个方法是用 @Contentded 注解,java 8 后开始支持,java 11 后 Contended 从 sun.misc 搬到了 jdk.internal.misc。它作用就是自动帮你做 Padding,它保证在任意 JVM 上都能有 Padding 效果,就不用我们再去构造 Class 级联结构了。比如上面例子中用 @Contended 就是:
class SomeClassContended {
volatile long valueA;
@Contended
volatile long valueB;
}
它的内存结构在 HotSpot 64 下是:
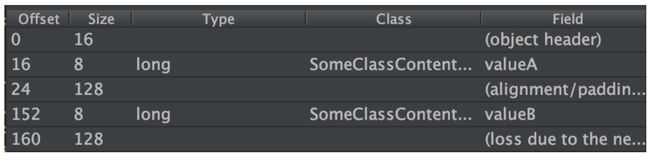
它是按 128 做 padding 的,它并没管我机器的 Cache Line 是多少,另外它是在 valueB 前后都做 Padding。这也是更推荐的方式。一般来说都尽力用 @Contended 注解了,除非为了兼容 Java 8 以下 JVM 或者为了性能,为了 Object 大小等原因,才可能会去手工做 Padding。
上面内存结构是通过 JOL 插件 来查看的,它里面用的OpenJDK: jol 工具。
False Sharing 测试的话可以参考 JMH 的例子 写自己的测试。
实际 Padding 例子,可以看看 Netty 4.1.48 下的 InternalThreadLocalMap。
JVM 上这个问题常见吗
上面 False Sharing 的例子是我们故意构造而得到的,所以很容易复现,很容易观察到。但实际开发中让同一个对象里不同 Field 被多个线程同时访问的情况并不多。倒是有这种例子比如 ConcurrentHashMap 里用于计算元素总量的 CounterCell 类。不过这种场景并不是很多,而一般情况下,拿上面的 SomeClass 来举例,它更可能被声明为:
class SomeClass{
volatile long value;
}
SomeClass a = new SomeClass();
SomeClass b = new SomeClass();
之后 Thread 1 和 Thread 2 分别去操作 a,b 两个对象。这种场景下,按说确实有 False Sharing 问题,但因为 a, b 对象都分配在 JVM 堆上,它俩得刚巧在堆上被连续创建出来,且在后续一系列 GC 中都一直能恰好挨在一起,才能持续的存在 False Sharing 问题。这么看来 False Sharing 似乎很难出现。比如我们测试时,让每个 Thread 都像上面这样 new SomeClass() 之后都操作自己 new 出来的 SomeClass 对象,我们会发现无论怎么测试,性能都和没有 False Sharing 时的性能一致,也即没有 False Sharing 问题。下面会说为什么这里没有 False Sharing。
更进一步,即使是同一个 Class 内的不同 Field,如果不是普通变量而是引用,比如这样:
class SomeClass {
ObjectA valueA;
ObjectB valueB;
}
两个 Thread 分别操作这两个引用,False Sharing 问题要求这两个引用恰好指向 JVM 堆上两个相邻对象,且两个对象得足够小,保证两个对象内被操作的值离得足够近,能放在同一个 Cache Line 上。想想每个对象都有 Object Header 也即天生就有至少 16 字节的 Padding 在,这也让被操作的值更不容易恰好在同一个 Cache Line 上。
所以 False Sharing 问题在 JVM 上并不会特别常见。
TLAB,PLAB 可能会加重 False Sharing 问题
按说 False Sharing 问题不会很常见,不过 TLAB 和 PLAB 机制可能会增大它出现的几率。TLAB 全称 Thread Local Allocation Buffers,我并没有找到一个特别好的介绍,这个 Blog 马马虎虎能看看: Introduction to Thread Local Allocation Buffers (TLAB) - DZone Java。
以下图为例,Java 分配内存通常一开始在 Eden 区分配,一个指针用来区分分配过的区域和还未分配的区域。每次分配内存都需要去移动这个指针来分配。如果所有线程分配内存时候都去操作这个指针,势必会产生很多竞争,各个线程都想去移动这个指针,而 TLAB 的存在即是说每次线程分配内存的时候不是申请多少就分配多少,而是每次分配稍大的区域,如下图虚线,之后内存分配尽力在线程自己的这块内存区域上进行,从而减少对 ptr 指针的竞争。如果线程的 TLAB 用完了,或者分配的对象太大,才会去争抢 ptr。
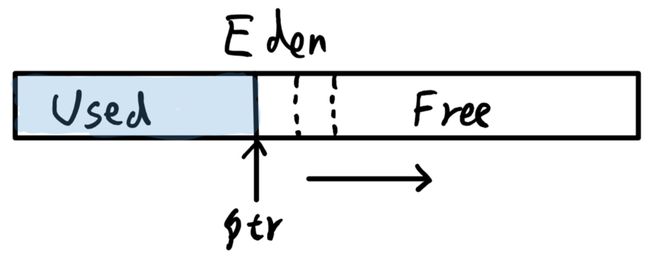
与 TLAB 类似的还一个叫做 PLAB 的,Promotion Local Allocation Buffers,用在一组 GC 线程并发的将新生代对象晋升到老代时使用。也是每个 GC 线程会提前分配一块区域,每次晋升对象的时候将对象拷贝至线程自己的这块分配好的区域上,从而减小竞争。
如果是标记-整理算法,按说对象并发的 Sweep 到新位置时也会是用上面这种方法进行。不过这个我没有找到说明的地方。
这么一来之前说两个线程分别 new SomeClass(),每个线程只操作自己 new 出来的 SomeClass 对象不会引起 False Sharing 的原因就清楚了,因为每个线程会把 SomeClass 分配在自己的 TLAB 上,一般 TLAB 大于 Cache Line 所以不会引起 False Sharing 问题。JVM 上容易引起 False Sharing 问题的点也清楚了,即一个线程连续分配了两个对象,这两个对象后来被分配给不同的线程,并且被它们频繁更新,这两个对象在两个不同线程上就容易出现 False Sharing 问题,即使经历数轮 GC,它俩可能在内存上还是可能在一起,所以说 TLAB 和 PLAB 会增大 False Sharing 出现的概率。
怎么证实这一点呢?不太容易,但指导思想就是让同一个线程连续 new 对象,再让其它线程来访问这些对象。只要对象不会很大,因为 TLAB 的关系,这些对象中有两个在同一个 Cache Line 上的几率会很大。比如我在 JMH 测试时这么写:
public static class SomeClassValue {
volatile int value;
}
@State(Scope.Group)
public static class SomeClass {
SomeClassValue[] val = new SomeClassValue[2];
public SomeClass() {
this.val[0] = new SomeClassValue();
this.val[1] = new SomeClassValue();
}
}
@Benchmark
@Group("share")
public void testA(SomeClass someClass) {
someClass.c[0].value++;
}
@Benchmark
@Group("share")
public void testB(SomeClass someClass) {
someClass.c[1].value++;
}
看到线程会共享 SomeClass 对象,但会分别访问 SomeClass 中不同的 SomeClassValue。这两个 value 可能会被放在同一个 Cache Line 上而被观测到执行性能下降。
JVM 上 False Sharing 严重吗
正常来说 False Sharing 并不常见,想测出它也不容易,可能根据机器型号不同,JVM 版本不同,运行状况甚至运行时机不同而不一定什么时候出现,但是一旦出现在系统的 Hot Spot 上,数倍的性能损失是很严重的。False Sharing 可能产生严重问题的场景是:
- 某个 Class 的对象被连续的创建;
- 创建的对象被分发给多个不同的线程去读取、写入,每个线程本来可以独享一个对象;
- 对象内被线程操作的 Field 被声明为 volatile;
比如可以拿 Netty 4.1.48 下的 InternalThreadLocalMap 作为例子感受一下。这个 Thread Local Map 本来是每个 EventLoop 一个的,各个 EventLoop 不相互干扰。但是访问 Thread Local 对象本身是 Hot Spot,访问的很多,如果一旦出现 False Sharing 就会导致性能大幅度下降。EventLoop 是 Netty 启动时在一个 for loop 中一口气被创建出来的,所以一组 InternalThreadLocalMap 中有几个刚巧紧挨着被创建出来是完全可能的。所以 InternalThreadLocalMap 用 Padding 做了一下保护。当然我理解即使 EventLoop 不是连续被创建出来也该去保护一下 InternalThreadLocalMap 以防恰好多个 Map 对象被放到同一个 Cache Line 上去。
CPU Cache(CPU 缓存)基础解析
参考
- PerfBook
- 淺談memory cache « Opass’s Blog
- Computer Architecture - Class notes
- 《现代体系结构上的UNIX系统》
- 与程序员相关的CPU缓存知识 | | 酷 壳 - CoolShell
- https://people.freebsd.org/~lstewart/articles/cpumemory.pdf
- Writing cache-friendly code - Stardog
- http://java-performance.com/