新闻文本分类学习笔记
赛题介绍
地址:https://tianchi.aliyun.com/competition/entrance/531810/introduction
赛题背景:
- 要求选手根据新闻文本字符对新闻的类别进行分类
- 带大家接触NLP的预处理、模型构建和模型训练等知识点。
- 为本赛题定制了系列学习方案,其中包括数据科学库、通用流程和 baseline方案学习三部分。
赛题数据:
- 赛题数据为,新闻文本
- 按照字符级别进行匿名处理
- 整合划分出14个候选分类类别:财经、彩票、房产、股票、家居、教育、科技、社会、时尚、时政、体育、星座、游戏、娱乐。
- 训练集20w条样本,测试集A包括5w条样本,测试集B包括5w条样本
评测标准与读取方式:

数据分析与处理
首先我们需要读出数据,但这个数据有点大,训练集20w的样本大概就900M了,所以需要根据电脑内存情况来使用pandas的参数,最简单的可以是默认读取,那读出来就是一个dataframe,方便之后做操作:
train_df = pd.read_csv('train_set.csv', sep='\t')
而若是内存不够,则需要使用下面两种方式读或者看数据:
train_tfr = pd.read_csv('train_set.csv', sep='\t', chunksize=20000)
data = pd.DataFrame()
for train_data in train_tfr:
data = data.append(train_data,ignore_index=True)
data.shape

或者使用iterator参数,它相当于内置了一个生成器yield,可以根据想要的数据量进行取值,下次再使用get_chunk的时候,将拿到上一次结尾的数据,这也符合yield定义:
train_tfr = pd.read_csv('train_set.csv', sep='\t', iterator=True)
train_tfr.get_chunk(100)
有了数据后,我们就可以进行相关的信息统计:
train_df.head(5)
"""
label text text_len
0 2 2967 6758 339 2021 1854 3731 4109 3792 4149 15... 1057
1 11 4464 486 6352 5619 2465 4802 1452 3137 5778 54... 486
2 3 7346 4068 5074 3747 5681 6093 1777 2226 7354 6... 764
3 2 7159 948 4866 2109 5520 2490 211 3956 5520 549... 1570
4 3 3646 3055 3055 2490 4659 6065 3370 5814 2465 5... 307
"""
然后使用描述性统计看看它的分布情况,这里可以取前一百条:
data.describe()
"""
label
count 100.000000
mean 3.770000
std 3.489826
min 0.000000
25% 1.000000
50% 2.500000
75% 6.000000
max 13.000000
"""
因为文本数据是非结构化数据,没有标准化或者缺失值异常值的处理,所以大致看明白数据长什么样,知道它是一个中英文本,以及赛题介绍的类别,我们就可以更进一步的分析与可视化了。
%pylab inline
train_df['text_len'] = train_df['text'].apply(lambda x: len(x.split(' ')))
print(train_df['text_len'].describe())
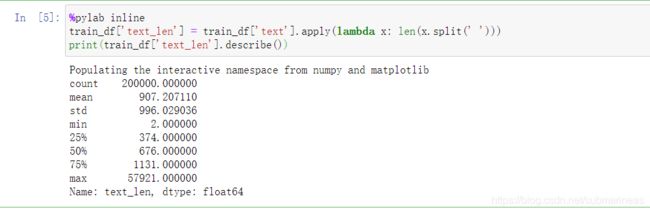
这里我们知道,删除空格造成的干扰后,包括字符一起,文本的平均长度是907,标准差是996,那从这两个数据可以得到样本比较稳定,趋向于正态,而最大与最小之间的差距,可能需要做一下归一化,更准确来讲可能是需要做截断。
_ = plt.hist(train_df['text_len'], bins=200)
plt.xlabel('Text char count')
plt.title("Histogram of char count")
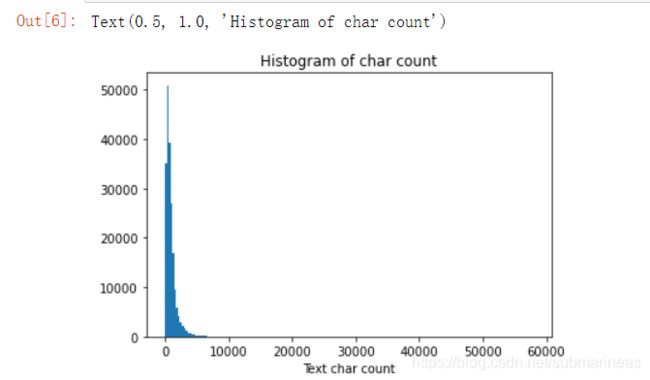
这也应征了上面的想法,如果在结构化数据里,这已经产生偏态了。
kind = pd.DataFrame(train_df['label'].value_counts()).reset_index()
fig = px.pie(kind,names="index",values="label")
fig.show()

from collections import Counter
all_lines = ' '.join(list(train_df['text']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:d[1], reverse = True)
print(len(word_count)) # 6869
print(word_count[0]) # ('3750', 7482224)
print(word_count[-1]) # ('3133', 1)
从统计结果中可以看出,在训练集中总共包括6869个字,其中编号3750的字出现的次数最多,编号3133的字出现的次数最少。这里还可以根据字在每个句子的出现情况,反推出标点符号。下面代码统计了不同字符在句子中出现的次数,其中字符3750,字符900和字 符648在20w新闻的覆盖率接近99%,很有可能是标点符号。
train_df['text_unique'] = train_df['text'].apply(lambda x: ' '.join(list(set(x.split(' ')))))
all_lines = ' '.join(list(train_df['text_unique']))
word_count = Counter(all_lines.split(" "))
word_count = sorted(word_count.items(), key=lambda d:int(d[1]), reverse = True)
print(word_count[0]) # ('3750', 197997)
print(word_count[1]) # ('900', 197653)
print(word_count[2]) # ('648', 191975)
TF-IDF + RidgeClassifier
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import RidgeClassifier
from sklearn.metrics import f1_score
tfidf = TfidfVectorizer(ngram_range=(1,3), max_features=3000)
train_test = tfidf.fit_transform(train_df['text'])
clf = RidgeClassifier()
clf.fit(train_test[:10000], train_df['label'].values[:10000])
val_pred = clf.predict(train_test[10000:])
print(f1_score(train_df['label'].values[10000:], val_pred, average='macro'))
"""
0.87
"""
不知道为什么第一次线上反而比线下低0.3以上?可能是我数据有问题,之前做探索性分析的时候做了很多变换。

然后用lr跑一下试试,最终达到了0.938的成绩,看来这个数据还是挺简单的,而且基本没有过拟合:
