人工智能第1周(案例)
目录
一、数据探索
二、特征工程
一、数据探索
前言:个人觉得 read_csv之后,第一,head()大致看下数据长成什么样
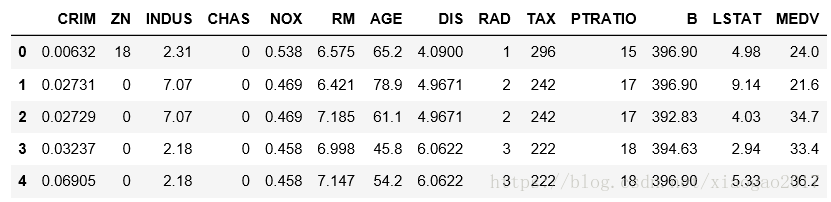
第二,info()一下,看看空值多不多

第三,如果属性不是很多,又比较了解业务,可有看下直方图、散点图等。如果不是的话,可有略过第三步。
第四,查看两两特征相关性(***)
(1)加载数据
import pandas as pd
data=pd.read_csv('./a.csv')
data.info() #列详情(列名、类型、列中是否为空)
(2)是否为空
data.info()、data.isnull().sum()#为空的个数
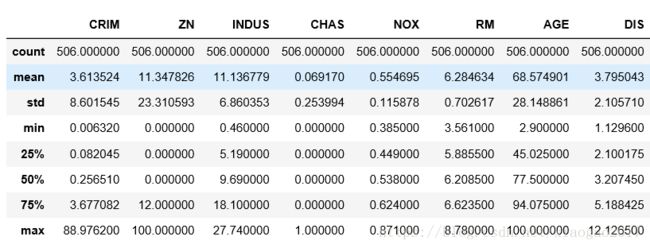
(3)列特性(属性特性)
data.describe()#个数、平均值、最大、最小、分位数
(4)目标y与其他属性的直方图
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig = plt.figure()
sns.distplot(data.CRIM.values, bins=30)#kde=True可有可无
plt.ylabel('percent of home', fontsize=20)
plt.xlabel('price of home', fontsize=20)
plt.show()
(5)热图 heatmap(两两特征相关性)
cols=data.columns
# 两两之间的相关系数 矩阵,通常认为相关系数大于0.5的为强相关
# corr()判断相关系数,-1=
plt.subplots(figsize=(13, 9))
#annot:是否显示值 mask:指定数据不展示 cbar:是否展示灰度带
sns.heatmap(data_corr,annot=True,mask=data_corr <0.5)#显示值
plt.savefig('house_coor.png' )
plt.show()
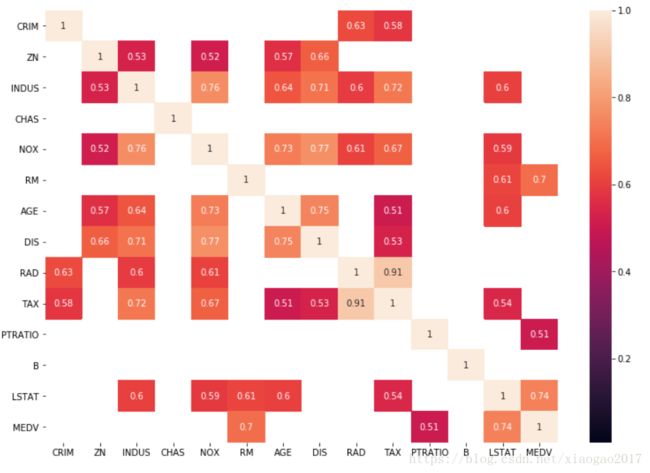
注意1:两两不线性相关,不代表不相关。
注意2:特征之间相关程度越弱越好,特征与y之间相关度越强越好。
(6)指定阈值,超过阈值的展示出来
#设定阈值,超过阈值的展示出来
threshold = 0.5
#超过阈值的 存放进来
corr_list = []
#矩阵 的行列都相等
size = data_corr.shape[0]
#循环遍历
for i in range(0, size):
#i+1表示 本身不计算
for j in range(i+1,size):
#如果求 corr()时,加上abs()的话,就不用管or之后的
if (data_corr.iloc[i,j] >= threshold and data_corr.iloc[i,j] < 1) or (data_corr.iloc[i,j] < 0 and data_corr.iloc[i,j] <= -threshold):
#保留i和j的目的:后面会显示 谁与谁的相关关系是多少
corr_list.append([data_corr.iloc[i,j],i,j])
#倒序
s_corr_list = sorted(corr_list,key=lambda x: -abs(x[0]))
#默认的是正序
#s_corr_list = sorted(corr_list)
for v,i,j in s_corr_list:
print ("%s and %s = %.2f" % (cols[i],cols[j],v))
二、特征工程
参考这里